背景
之前的程序生成了300w行的日志,bug的地方有“error”字样,其他部分皆为正常日志,不用管,想看看error前面都发生了啥事,然而人眼硬看300w,即使有ctrl+f也很麻烦,于是打算写个程序,自动提取出崩溃的上面5行日志信息。
比如
start
init
running
running
working
deleting
error
start
init
error
想提取成
init
running
running
working
deleting
error
start
init
error
程序代码
def get_lines(file):
for line in file:
yield line
def extract_lines(input_file, output_file, window_size, markword):
window = []
for line in get_lines(input_file):
window.append(line)
if (len(window) > window_size):
window = window[1:]
if markword in line:
for l in window:
output_file.write(l)
window = []
with open('log.txt', 'r', encoding='UTF-8') as input_file, open('output.txt', 'w',
encoding='UTF-8') as output_file:
extract_lines(input_file, output_file, 5, 'error')
运行结果
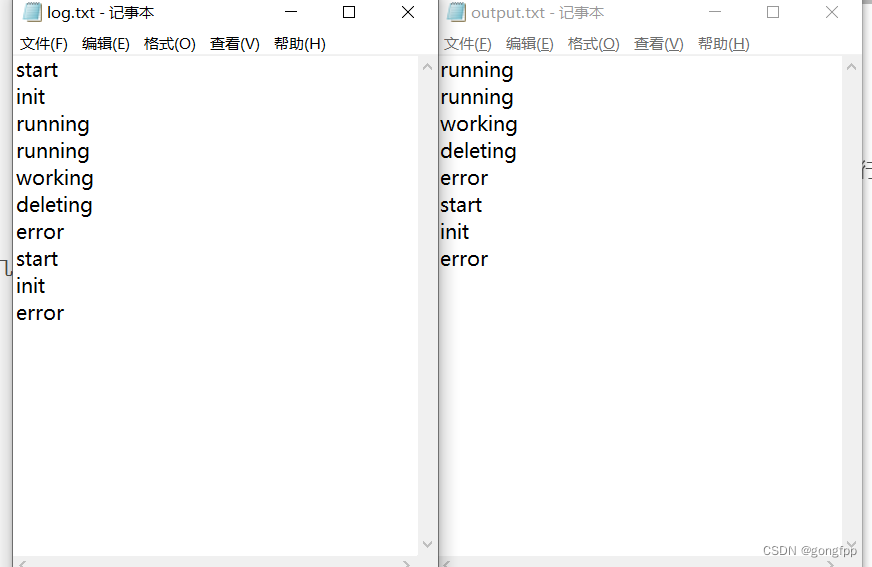
左图是输入,右图输出 可以看到能正确完成任务。
注意事项和解释
- 你的文本用的什么编码自己在源代码处改,想提取多少行就把5改成几。
- 只要是文本行内有输出关键字(markword)就行,比如上面的例子,如果有一行是running with error xxx ,这行包括了error关键字,他以及上面几行也会被输出。
- 程序能跑大文件,因为用了yield关键字来流式处理文本,不会一次性读入所以数据。(300w行日志有3个g,这里就不放图了)
- n行内容正序输出用的是滑动窗口的思想,详情请自行谷歌或读代码。