
Elastic App Search 中的引擎(engines)使你能够索引文档并提供开箱即用的可调搜索功能。 默认情况下,引擎支持预定义的语言列表。 如果你的语言不在该列表中,此博客将说明如何添加对其他语言的支持。 我们将通过创建一个 App Search 引擎来实现这一点,该引擎具有针对该语言设置的分析器。
在我们深入细节之前,让我们定义什么是 Elasticsearch 分析器:
Elasticsearch 分析器是一个包含三个较低级别构建块的包:字符过滤器、标记器和标记过滤器。 分析器可以是内置的或定制的。 内置分析器将构建块预打包到适合不同语言和文本类型的分析器中。更多关于 Analyzer 的内容,请参阅文章 “Elasticsearch: analyzer”。
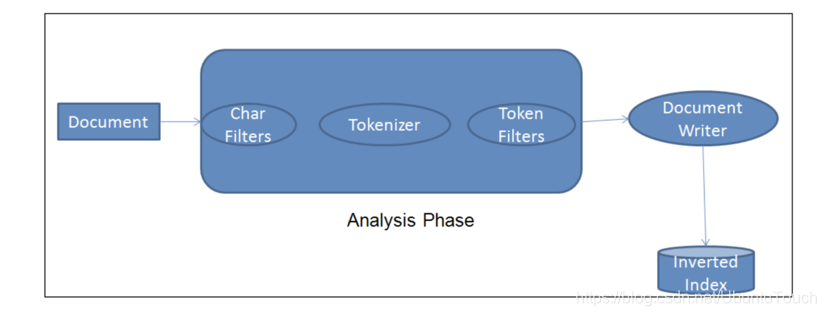
每个字段的分析器用于:
- 索引文档。 每个文档字段都将使用其相应的分析器进行处理,并分解为分词以方便搜索。
- 搜索文档。 将分析 search query 以确保与已分析的索引字段正确匹配。
基于 Elasticsearch 索引的引擎使你能够从现有的 Elasticsearch 索引创建 App Search 引擎。 我们将使用我们自己的分析器和映射创建一个 Elasticsearch 索引,并在 App Search 中使用该索引。
这个过程有四个步骤:
- 创建 Elasticsearch 索引和索引文档
- 将语言分析器添加到该索引
- 更新索引映射以使用分析器
- 重新索引文档
1)创建 Elasticsearch 索引和索引文档
首先,让我们使用一个尚未针对任何语言进行优化的索引。 假设这是一个没有预定义映射的新索引,它是在第一次为文档建立索引时创建的。
在 Elasticsearch 中,映射(mapping)是定义文档及其包含的字段如何存储和索引的过程。 每个文档都是字段的集合,每个字段都有自己的数据类型。 映射数据时,你创建一个映射定义,其中包含与文档相关的字段列表。
回到我们的例子。 该索引称为 books,title 为罗马尼亚语。 我们选择罗马尼亚语是因为它是我的语言,它不包含在 App Search 默认支持的语言列表中。
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2)增加语言分析器到书籍索引
当我们检查 books 索引映射时,我们发现它没有针对罗马尼亚语进行优化。 你可以看出 settings 块中没有 analysis 字段,并且文本字段不使用自定义分析器。
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}如果我们尝试使用 books 索引创建 App Search 引擎,我们会遇到两个问题。 首先,搜索结果将不会针对罗马尼亚语进行优化,其次,精确调整等功能将被禁用。
关于不同类型的 Elastic App Search 引擎的快速说明:
- 默认选项是 App Search 托管引擎,它将自动创建和管理隐藏的 Elasticsearch 索引。 使用此选项,你必须使用 App Search 文档 API 在引擎中提取数据。
- 对于另一个选项,App Search 会创建一个具有现有 Elasticsearch 索引的引擎 —— 在这种情况下,App Search 将按原样使用该索引。 在这里,你可以使用 Elasticsearch 索引文档 API 直接在底层索引中提取数据。
[相关文章:Elasticsearch Search API:一种定位 App Search 文档的新方法]
当你从现有 Elasticsearch 索引创建引擎时,如果映射不遵循 App Search 约定,则不会为该引擎启用所有功能。 让我们通过查看完全由 App Search 管理的引擎来更仔细地了解 App Search 映射约定。 该引擎有两个字段,title 和 author,并使用英语。
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}你会看到 title 字段有几个子字段。date、float 和 location 子字段不是文本字段。
在这里,我们感兴趣的是如何设置 App Search 需要的文本字段。 多了几个字段! 此文档页面解释了 App Search 中使用的文本字段。 让我们看看 App Search 为属于 App Search 托管引擎的隐藏索引设置的分析器:
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}
如果我们想为不同的语言(例如挪威语、芬兰语或阿拉伯语)创建一个可以在 App Search 中使用的索引,我们将需要类似的分析器。 对于我们的示例,我们需要确保词干和停用词过滤器使用罗马尼亚语版本。
回到我们最初的 books 索引,让我们添加正确的分析器。
在这里快速警告一下。 对于现有索引,分析器是一种 Elasticsearch 设置,只能在索引关闭时更改。 在这种方法中,我们从现有索引开始,因此需要关闭索引、添加分析器,然后 reopen 索引。
注意:作为替代方案,你也可以使用正确的映射从头开始重新创建索引,然后索引所有文档。 如果这更适合你的用例,请随意跳过本指南中讨论打开和关闭索引以及重新索引的部分。
你可以通过运行 POST books/_close 来关闭索引。 之后,我们将添加分析器:
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}你可以看到,我们正在添加 ro-stem-filter 以提取罗马尼亚语的词干,这将提高罗马尼亚语特定单词变体的搜索相关性。 我们包括罗马尼亚语停用词过滤器 (ro-stop-words-filter) 以确保罗马尼亚语停用词不被考虑用于搜索目的。
现在我们将通过执行 POST books/_open 重新打开索引。
3)更新索引映射以使用分析器
一旦我们有了分析设置,我们就可以修改索引映射。 App Search 使用动态模板来确保新字段具有正确的子字段和分析器。 对于我们的示例,我们只会将子字段添加到现有的 title 和 author 字段中:
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4)重新索引文档
books 索引现在几乎可以在 App Search 中使用了!
我们只需要确保我们在修改映射之前索引的文档具有所有正确的子字段。 为此,我们可以使用 update_by_query 就地运行重建索引:
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}由于我们使用的是 match_all 查询,因此所有现有文档都将被更新。
通过 update by query 请求,我们还可以包含一个脚本参数来定义如何更新文档。
请注意,我们没有更改文档,但我们确实希望按原样重新索引现有文档,以确保文本字段 author 和 title 具有正确的子字段。 因此,我们不需要在我们的查询请求更新中包含脚本。
我们现在有一个语言优化的索引,我们可以在带有 Elasticsearch 引擎的 App Search 中使用! 你将在以下屏幕截图中看到实际的好处。
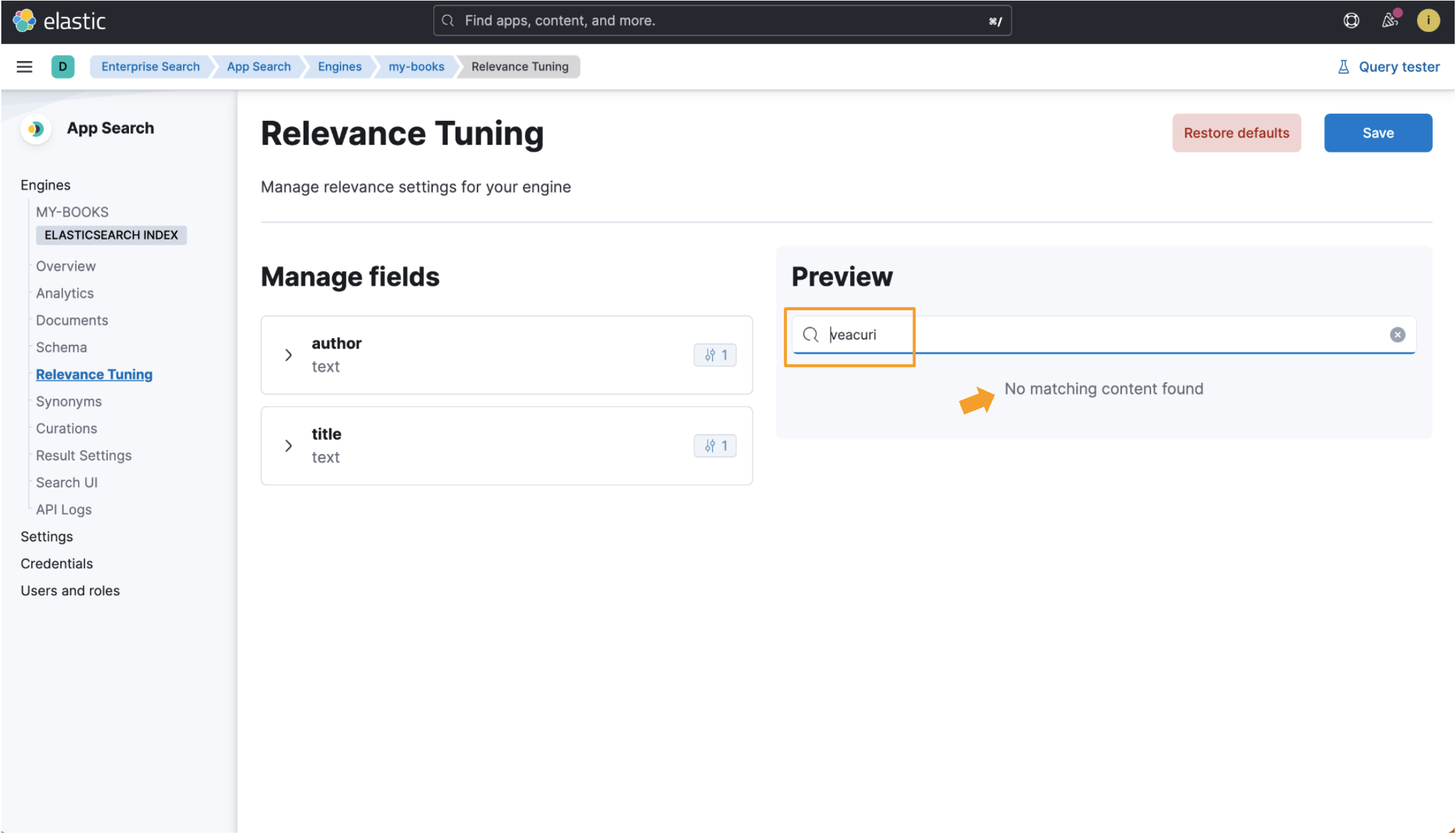
我们将使用书名 One Hundred Years of Solitude 作为参考。 罗马尼亚语的翻译标题是 Un veac de singurătate。 注意 veac 这个词,它是罗马尼亚语中 “世纪” 的意思。 我们将使用 veac 的复数形式进行搜索,即 veacuri。 我们在将要查看的两个示例中都提取了此数据记录:
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}当索引未针对某种语言进行优化时,罗马尼亚书名 Un veac de singurătate 将使用标准分析器进行索引,该分析器适用于大多数语言,但可能并不总是与相关文档匹配。 搜索 veacuri 不会显示任何结果,因为此搜索输入与数据记录中的任何纯文本都不匹配。
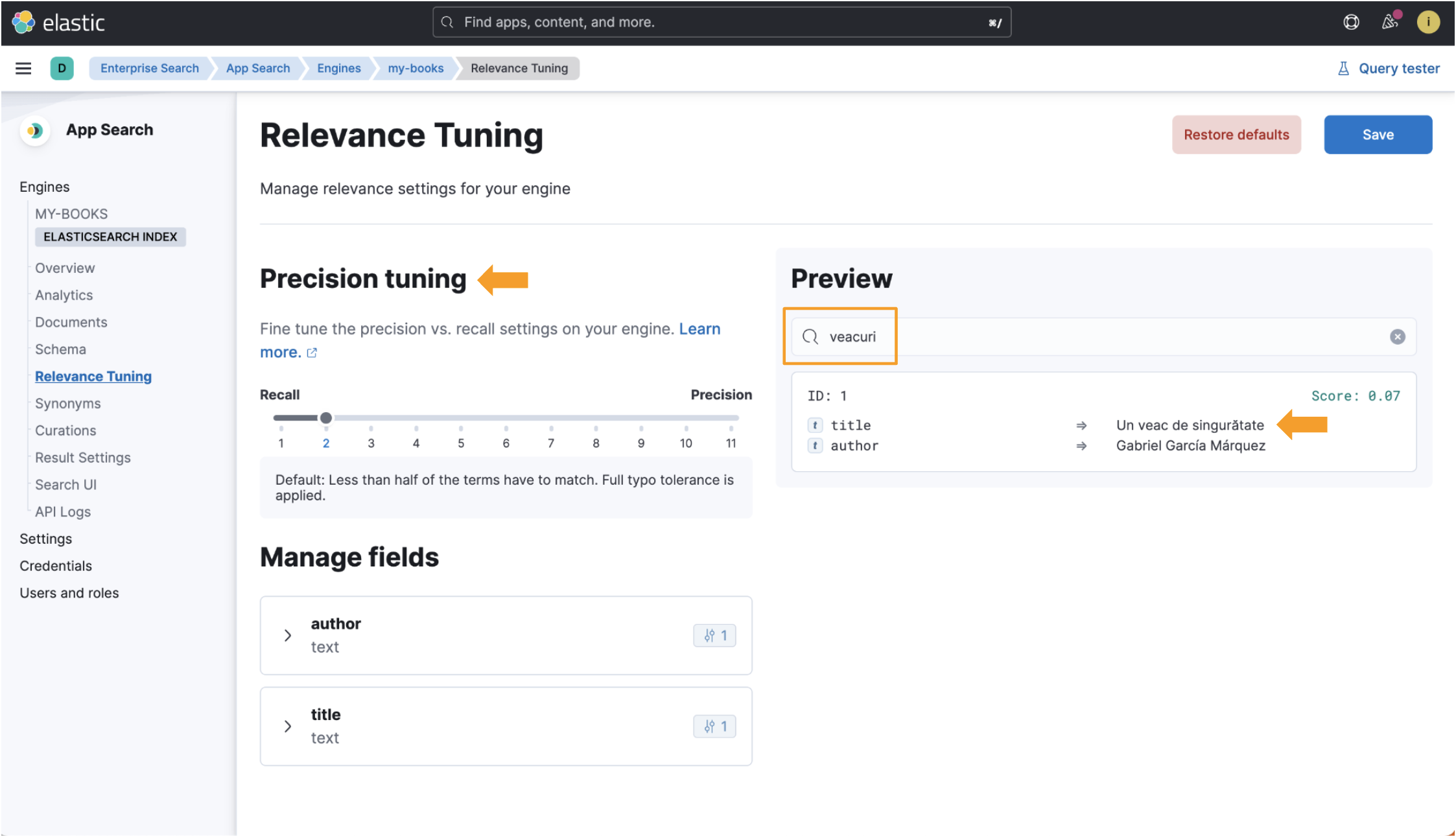
然而,在使用语言优化索引时,当我们搜索 veacuri 时,Elastic App Search 会将其与罗马尼亚语单词 veac 相匹配,并返回我们要查找的数据。 相关调整视图中也提供精确调整字段! 查看此图像中所有突出显示的位:
因此,我们在 Elastic Enterprise Search 中添加了对罗马尼亚语的支持,这是我的语言! 可以复制本指南中使用的过程来创建针对 Elasticsearch 支持的任何其他语言优化的索引。 有关 Elasticsearch 中支持的语言分析器的完整列表,请查看此文档页面。
Elasticsearch 中的分析器是一个引人入胜的话题。 如果你有兴趣了解更多信息,这里有一些其他资源:
- Elasticsearch 文本分析概述文档页面
- Elasticsearch 内置分析器参考文档页面(有关支持的语言分析器列表,请参阅此子页面。)
- 了解有关 Elastic Enterprise Search 和 Elastic Cloud 试用的更多信息