研读Rust圣经解析——Rust learn-10(泛型,trait,生命周期)
泛型
泛型是具体类型或其他属性的抽象替代。我们可以表达泛型的属性,比如他们的行为或如何与其他泛型相关联,而不需要在编写和编译代码时知道他们在这里实际上代表什么,直到代码编译时,自动帮助我们进行确认泛型的真实类型,称为泛型擦除,在Rust中称其为单态化,以此来保证效率,所以你无需为效率担心
应用泛型方法
泛型方法指定使用<T>当然字母可以是任意的大写(规范)一般来说:
- T:类型type
- K:键
- V:值
use rand;
use rand::Rng;
fn rand_back<T>(list: &[T]) -> &T {
let rand_num = rand::thread_rng().gen_range(0..3);
return &list[rand_num];
}
fn main() {
let arr = [5, 4, 3];
let res = rand_back(&arr);
println!("{}", res);
}
泛型结构体
将类型应用到结构体中,在字段中设置出来
在后续使用的时候我们直接在变量上指定变量所用的泛型的类型即可
struct User<T> {
id: T,
username: T,
}
fn main() {
let user:User<i32> = User {
id: 32,
username: 454,
};
}
枚举泛型
enum Res<S, F> {
Success(S),
Fail(F),
}
方法定义中的泛型
为结构体的实现方法也可以设置泛型?不是的,是应为结构体就是个泛型,所以为结构体实现方法的时候需要在impl上设置<T>
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point {
x: 5, y: 10 };
println!("p.x = {}", p.x());
}
trait
trait 定义了某个特定类型拥有可能与其他类型共享的功能。可以通过 trait 以一种抽象的方式定义共享的行为。可以使用 trait bounds 指定泛型是任何拥有特定行为的类型。
那么实际上trait你就可以认为类似是Java的接口,需要进行实现
定义一个trait
使用trait关键字就可以定义一个trait,我们在其中去定义我们需要的子类实现的方法,无需指定方法的具体行为
trait Service{
fn init();
fn do_job();
fn finish();
}
默认trait方法实现
不知道大家记不记得在Java的接口中有一个default关键字用于默认实现接口中的方法,后续子类可以选择覆盖,不然则使用接口的默认方法其实Rust也有这样的特性
不过不需要任何关键字进行声明你直接写就行:
trait Service {
fn init();
fn do_job();
fn finish() {
println!("all services are closed");
}
}
为结构体实现trait
通过使用impl trait for struct为结构体实现trait
impl Service for User<i32> {
fn init() {
todo!()
}
fn do_job() {
todo!()
}
}
调用trait中实现的方法
调用方法主要看trait是否使用self作为入参,只有通过self为入参的才能被赋予的变量通过.调用
我们来看个例子:
struct User<T> {
id: T,
username: T,
}
trait Service {
fn init(&self);
fn do_job();
fn finish() {
println!("all services are closed");
}
}
impl Service for User<i32> {
fn init(&self) {
println!("do init")
}
fn do_job() {
println!("do job")
}
}
fn main() {
let user: User<i32> = User {
id: 32,
username: 454,
};
user.init();
User::finish()
}
从例子中就能清楚的发现,入参没有self只能用::
将trait作为参数
这也是一种非常常见的写法,我们要求只有实现某个trait的实体才能作为入参,应用其中的公共方法
我们看到User和User2都实现了Service,我们后面传入参数的时候既可以传User也可以传User2
struct User<T> {
id: T,
username: T,
}
struct User2{
id:i32
}
trait Service {
fn init(&self);
fn do_job();
fn finish() {
println!("all services are closed");
}
}
impl Service for User<i32> {
fn init(&self) {
println!("do init")
}
fn do_job() {
println!("do job")
}
}
impl Service for User2{
fn init(&self) {
todo!()
}
fn do_job() {
todo!()
}
}
fn use_Service(impl_instance:&impl Service){
impl_instance.init();
}
trait bound
我们认为这只是trait的语法糖,其应用场景在于需要大量传入trait入参的场景
fn test<T: Service>(item1: &T, item2: &T) {
相当于
fn test(item1: &impl Service, item2: &impl Service) {
多实现入参绑定
在我们真实的程序中,一个struct不可能只实现一个trait,这个问题大家学过设计模式就知道了,我们会常常把一个模块需要的实现抽象分离出去,然后让一个模块选择自己需要的某个或某几个进行实现
我们就可以使用+运算符进行限定绑定入参
fn test(param:&(impl Service1 + Service2))
这说明param这个入参既需要实现Service1也要实现Service2
我们也可以通过bound进行简写
fn test<T:Service1+Service2>(param:&T)
where简写
然而,使用过多的 trait bound 也有缺点。每个泛型有其自己的 trait bound,所以有多个泛型参数的函数在名称和参数列表之间会有很长的 trait bound 信息,这使得函数签名难以阅读。
如下:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {
我们可以通过where简写(我最喜欢)
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
多重bound绑定实现
我们来思考一下:如果我们没有如HashMap这样的类型,而我们的需求是要通过结构体构建并输出如下的结果:
User {
id: KV {
key: 1,
value: "1001",
},
username: KV {
key: 2,
value: "zhangsan",
},
}
那我们就需要构建一个叫KV的struct,设置key,value的字段名称,如下:
#[derive(Debug)]
struct User {
id: KV,
username: KV,
}
#[derive(Debug)]
struct KV {
key: i32,
value: String,
}
fn main() {
let user = User {
id: KV {
key: 1,
value: "1001".to_string(),
},
username: KV {
key: 2,
value: "zhangsan".to_string(),
},
};
println!("{:#?}", user);
}
这样可以直接实现,现在有个要求,我们希望KV的value类型不止能存储String,也可以存其他的类型,我们就能想到:
#[derive(Debug)]
struct User<K,V> {
id: KV<K>,
username: KV<V>,
}
#[derive(Debug)]
struct KV<T> {
key: i32,
value: T,
}
fn main() {
let user = User {
id: KV {
key: 1,
value: 1001,
},
username: KV {
key: 2,
value: "zhangsan".to_string(),
},
};
println!("{:#?}", user);
}
到这一步也很简单,但是我们就会开始发现一些问题,如果我们需要对某些泛型进行约束,就会变得很复杂,也不易阅读
我们需要更简单,更泛用,更有约束力的写法:
impl<T:Service1+Service3> KV<T>{
//....
}
如此KV这个结构体的传入T需要实现Service1+Service3
如下是一个具体的例子:
其中a变量是不可以使用show方法的
impl<T> Service1 for KV<T> {
}
impl<T> Service3 for KV<T> {
fn service3(&self) {
println!("service3")
}
}
impl<T: Service1 + Service3> KV<T> {
fn show(&self) {
println!("{}", self.key);
}
}
fn main() {
let a = KV {
key: 1,
value: "shd".to_string(),
};
a.service1();
a.service3();
let b = KV {
key: 1,
value: KV{
key: 2,
value: "shd".to_string(),
}
};
b.show();
}
生命周期
生命周期是另一类我们已经使用过的泛型。不同于确保类型有期望的行为,生命周期确保引用如预期一直有效。
生命周期避免了悬垂引用
生命周期的主要目标是避免悬垂引用(dangling references),后者会导致程序引用了非预期引用的数据。
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
我们看到在这个程序中r = &x;被一个新作用域包含在内,这导致最后print的时候r依然还是没有值的,转化为生命周期的说法就是:
- let r:创建了r变量
- {:进入一个新作用域
- let x = 5 :创建变量,赋值为5
- r:引用x
- }:退出作用域,x生命周期结束
- println!(“r: {}”, r):打印
我们可以看到,出了作用域相应的x被销毁了生命周期结束,但是r没有结束,在打印时候依然存在,但是引用随着值销毁了,导致悬垂
因此若要不产生悬垂,必须延长x的生命周期
定义生命周期
我们为一个变量定义生命周期只需要再加上'a实际上你可以写任意的字母或单词(static,等关键词除外,因为是静态生命周期,后面说),生命周期一般设置在方法上,为了指明作用域结束后的回收
我们来看一段程序:
fn main() {
let a = "sjd";
let b = "absc";
let res = show(a,b);
println!("{}", res)
}
fn show(s: &str,b:&str) -> &str {
return if s.len() > b.len() {
b
} else {
a
}
}
很简单,传入字符串切片,判断长度并返回,简单吧,但是编译报错!
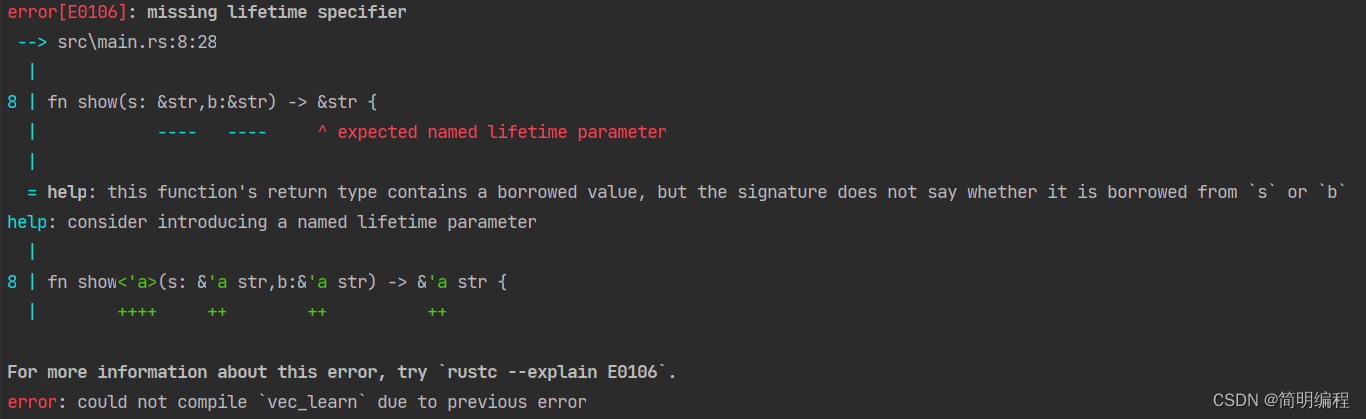
大家会想,我平时传一个字符串切片进去返回出来没什么问题啊比如:
fn main() {
let a = "sjd";
let b = "absc";
let res2 = show2(a);
println!("{}", res2);
}
fn show2(s: &str) ->&str{
s
}
没错这个函数当然没问题,因为编译器知道最后一定返回s,但是上面的程序,编译器不知道最后返回的是哪一个,当我们定义这个函数的时候,并不知道传递给函数的具体值,所以也不知道到底是 if 还是 else 会被执行。我们也不知道传入的引用的具体生命周期,所以自然出现问题。
所以我们就要显示的标注生命周期帮助编译器进行理解
标注生命周期
如下,我们对函数中使用的参数标注了生命周期,对返回值也标注了,相当于告诉编译器,两个参数有同样长的生命周期, 函数返回的引用的生命周期与函数参数所引用的值的生命周期的较小者一致
fn main() {
let a = "sjd";
let b = "absc";
let res = show(a, b);
println!("{}", res);
}
fn show<'a>(s: &'a str, b: &'a str) -> &'a str {
return if s.len() > b.len() {
b
} else {
s
};
}
也就是说,这个函数的返回值的生命周期和入参的生命周期中较小者一致,这样直到较小者的生命周期结束,返回值的生命周期也会结束
结构体生命周期
除了在方法上标注生命周期,在结构体上也可以标注生命周期
struct ImportantExcerpt<'a> {
part: &'a str,
}
这个结构体有唯一一个字段 part,它存放了一个字符串 slice,这是一个引用。类似于泛型参数类型,必须在结构体名称后面的尖括号中声明泛型生命周期参数,以便在结构体定义中使用生命周期参数。这个注解意味着 ImportantExcerpt 的实例不能比其 part 字段中的引用存在的更久。
输出/输入生命周期
函数或方法的参数的生命周期被称为 输入生命周期(input lifetimes),而返回值的生命周期被称为 输出生命周期(output lifetimes)。
生命周期规则
https://kaisery.github.io/trpl-zh-cn/ch10-03-lifetime-syntax.html
编译器采用三条规则来判断引用何时不需要明确的注解。第一条规则适用于输入生命周期,后两条规则适用于输出生命周期。如果编译器检查完这三条规则后仍然存在没有计算出生命周期的引用,编译器将会停止并生成错误
- 编译器为每一个引用参数都分配一个生命周期参数。换句话说就是,函数有一个引用参数的就有一个生命周期参数:fn foo<'a>(x: &'a i32),有两个引用参数的函数就有两个不同的生命周期参数,fn foo<'a, 'b>(x: &'a i32, y: &'b i32),依此类推
- 如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数:fn foo<'a>(x: &'a i32) -> &'a i32。(这也是为什么我们不用给单参函数显示声明生命周期的原因)
- 如果方法有多个输入生命周期参数并且其中一个参数是 &self 或 &mut self,说明是个对象的方法那么所有输出生命周期参数被赋予 self 的生命周期
静态生命周期
'static,其生命周期能够存活于整个程序期间。所有的字符串字面值都拥有 'static 生命周期
将引用指定为 'static 之前,思考一下这个引用是否真的在整个程序的生命周期里都有效,以及你是否希望它存在得这么久。大部分情况中,推荐 'static 生命周期的错误信息都是尝试创建一个悬垂引用或者可用的生命周期不匹配的结果。在这种情况下的解决方案是修复这些问题而不是指定一个 'static 的生命周期