【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
电影推荐系统
目录
1. 问题介绍
使用矩阵分解, 根据用户给短电影的评分数据, 做一个千人千面的个性化推荐系统。
需要安装推荐系统库surprise, 使用如下命令安装: pip install scikit-surprise
1.1推荐系统矩阵分解方法介绍
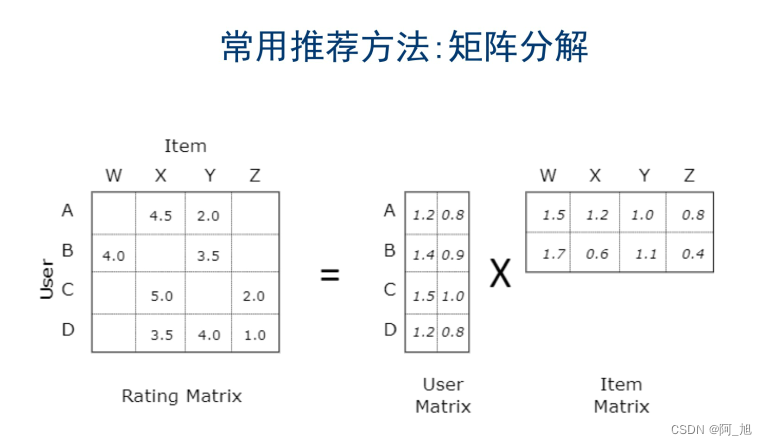






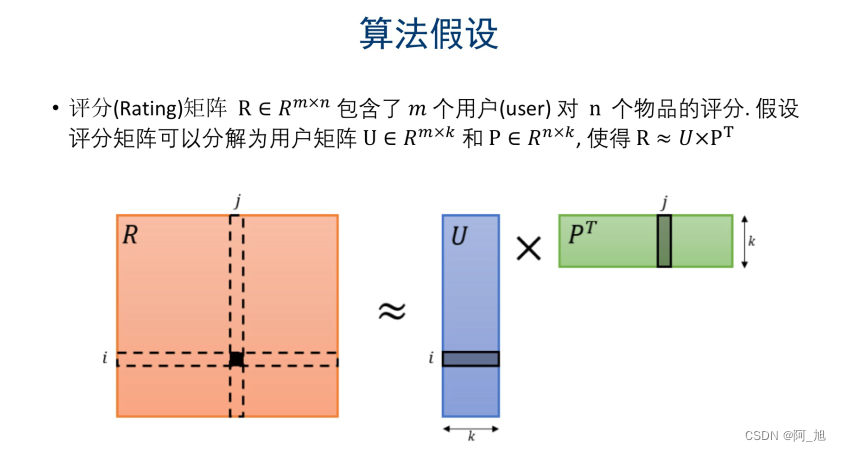




1.2 数据集:ml-100k
该数据集包括了943位用户对1682部电影的评分信息(总共100,000),评分也是1-5的整数;
- u.data文件包含了100,000条评分信息,每条记录的形式:user id | item id | rating | timestamp.(分隔符是一个tab)
2. 推荐系统实现
2.1 定义矩阵分解函数
关注GZH:阿旭算法与机器学习,回复:“电影推荐系统”即可获取本文数据集、源码与项目文档
# 导入 nunpy 和 surprise 辅助库
import numpy as np
import surprise
注: Surprise库本身没有提供纯粹的矩阵分解的算法, 在这里我们自己实现了基于Alternating Least Squares的矩阵分解, 使用梯度下降法优化;
矩阵分解类MatrixFactorization继承了surprise.AlgoBase, 方便我们使用surpise库提供的其它功能
class MatrixFactorization(surprise.AlgoBase):
'''基于矩阵分解的推荐.'''
def __init__(self, learning_rate, n_epochs, n_factors, lmd):
self.lr = learning_rate # 梯度下降法的学习率
self.n_epochs = n_epochs # 梯度下降法的迭代次数
self.n_factors = n_factors # 分解的矩阵的秩(rank)
self.lmd = lmd # 防止过拟合的正则化的强度
def fit(self, trainset):
'''通过梯度下降法训练, 得到所有 u_i 和 p_j 的值'''
print('Fitting data with SGD...')
# 随机初始化 user 和 item 矩阵.
u = np.random.normal(0, .1, (trainset.n_users, self.n_factors))
p = np.random.normal(0, .1, (trainset.n_items, self.n_factors))
# 梯度下降法
for _ in range(self.n_epochs):
for i, j, r_ij in trainset.all_ratings():
err = r_ij - np.dot(u[i], p[j])
# 利用梯度调整 u_i 和 p_j
u[i] -= -self.lr * err * p[j] + self.lr * self.lmd * u[i]
p[j] -= -self.lr * err * u[i] + self.lr * self.lmd * p[j]
# 注意: 修正 p_j 时, 按照严格定义, 我们应该使用 u_i 修正之前的值, 但是实际上差别微乎其微
self.u, self.p = u, p
self.trainset = trainset
def estimate(self, i, j):
'''预测 user i 对 item j 的评分.'''
# 如果用户 i 和物品 j 是已知的值, 返回 u_i 和 p_j 的点积
# 否则使用全局平均评分rating值(cold start 冷启动问题)
if self.trainset.knows_user(i) and self.trainset.knows_item(j):
return np.dot(self.u[i], self.p[j])
else:
return self.trainset.global_mean
2.2 基于上述矩阵分解实现电影推荐
from surprise import BaselineOnly
from surprise import Dataset
from surprise import Reader
from surprise import accuracy
from surprise.model_selection import cross_validate
from surprise.model_selection import train_test_split
import os
# 数据文件
file_path = os.path.expanduser('./ml-100k/u.data')
# - u.data文件包含了100,000条评分信息,每条记录的形式:user id | item id | rating | timestamp.(分隔符是一个tab)
# 数据文件的格式如下:
# 'user item rating timestamp', 使用制表符 '\t' 分割, rating值在1-5之间.
reader = Reader(line_format='user item rating timestamp', sep='\t', rating_scale=(1, 5))
data = Dataset.load_from_file(file_path, reader=reader)
# 查看文件内容
import pandas as pd
df = pd.read_csv("./ml-100k/u.data")
df.head()
| 196\t242\t3\t881250949 | |
|---|---|
| 0 | 186\t302\t3\t891717742 |
| 1 | 22\t377\t1\t878887116 |
| 2 | 244\t51\t2\t880606923 |
| 3 | 166\t346\t1\t886397596 |
| 4 | 298\t474\t4\t884182806 |
df.shape
(99999, 1)
默认的SGD方法
# 将数据随机分为训练和测试数据集
trainset, testset = train_test_split(data, test_size=.25)
# 初始化以上定义的矩阵分解类.
algo = MatrixFactorization(learning_rate=.005, n_epochs=60, n_factors=2, lmd = 0.2)
# 训练
algo.fit(trainset)
# 预测
predictions = algo.test(testset)
# 计算平均绝对误差
accuracy.mae(predictions)
Fitting data with SGD...
MAE: 0.7818
0.7817791289983778
用 surpise 内建的基于最近邻的方法做比较
# 使用 surpise 内建的基于最近邻的方法做比较
algo = surprise.KNNBasic()
algo.fit(trainset)
predictions = algo.test(testset)
accuracy.mae(predictions)
Computing the msd similarity matrix...
Done computing similarity matrix.
MAE: 0.7725
0.7724598550399949
用 surpise 内建的基于 SVD 的方法做比较
# 使用 surpise 内建的基于 SVD 的方法做比较
algo = surprise.SVD()
algo.fit(trainset)
predictions = algo.test(testset)
accuracy.mae(predictions)
MAE: 0.7398
0.7397586022054631
如果文章对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,回复:“电影推荐系统”即可获取本文数据集、源码与项目文档,欢迎共同学习交流