前言
最近准备备考PYTHON 计算机二级 ,一边刷题,一边把学习笔记记录下来,如果有同样准备考试的小伙伴,欢迎交流学习,共同进步。学习资源来自b站。链接为:计算机二级Python课程。
考点-jieba库

- jieba库 是目前表现较为不错的 Python 中文分词组件,它主要有以下特性:
1)支持四种分词模式:精确模式、全模式、搜索引擎模式、paddle模式。
2)支持繁体分词。
3)支持自定义词典。
4)MIT 授权协议。 - 二级考试jieba库最常考察函数 jieba.lcut(s)。
该函数试图将句子最精确地切开,适合文本分析,默认精确模式,返回一个列表类型。
第一题
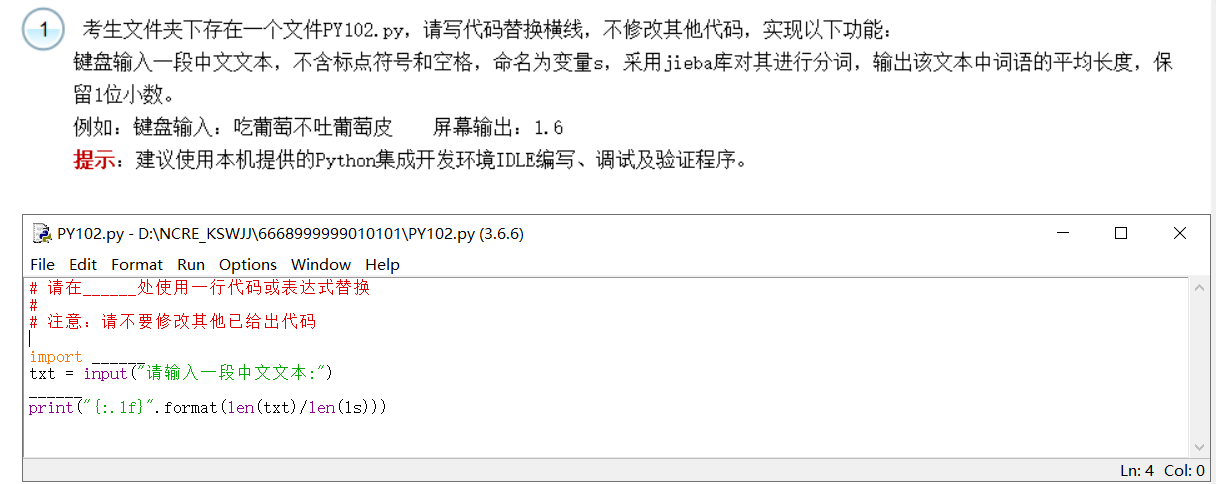
题目:
解析:
- 采用jieba库,所以**import jieba,第一空**so easy!
- jieba.lcut(txt) 返回输入文本的切片列表,赋给ls , 即:ls = jieba.lcut(txt) 填入第二空。
答案:
# 请在______处使用一行代码或表达式替换
# 注意:请不要修改其他已给出代码
import jieba
txt = input("请输入一段中文文本:")
ls = jieba.lcut(txt)
print("{:.1f}".format(len(txt)/len(ls)))
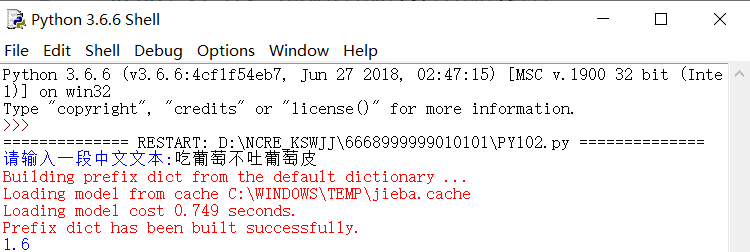
运行结果:
第四题
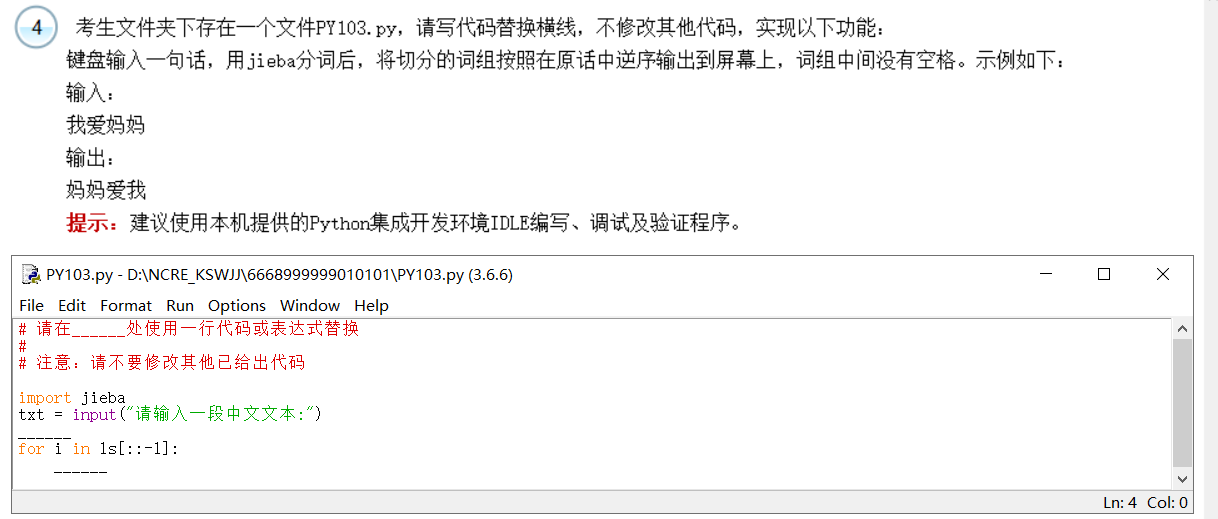
题目:
解析:
- 第一空与第一题类似,ls = jieba.lcut(txt),返回输入文本的切片列表,赋给ls。
- 接下来我们需要将输入文本逆序输出。
ls[::-1] 已经逆序了,我们只需要输出即可。
但要注意:直接 print(i) 是错误的,因为循环一次输出一次结果会是:
妈妈
爱
我 - 所以 print(i,end=“”) ,每次循环让空进行结尾,那输出就会是连着的。
答案:
# 请在______处使用一行代码或表达式替换
# 注意:请不要修改其他已给出代码
import jieba
txt = input("请输入一段中文文本:")
ls = jieba.lcut(txt)
for i in ls[::-1]:
print(i,end="")
运行结果:
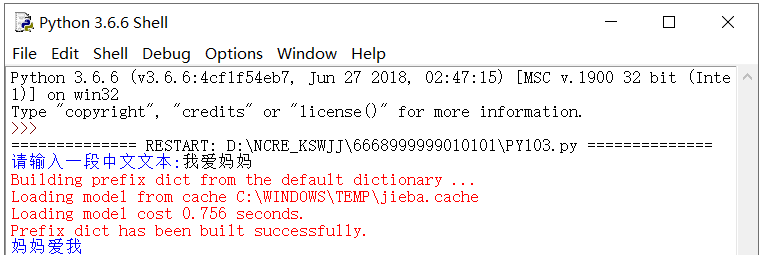
第六题
题目:
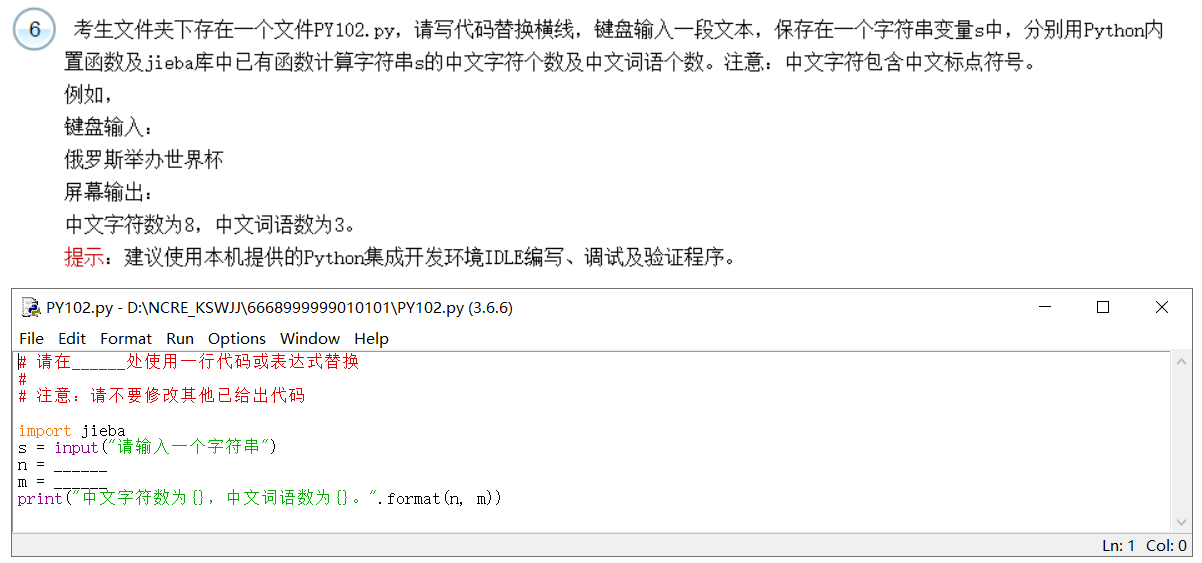
解析:
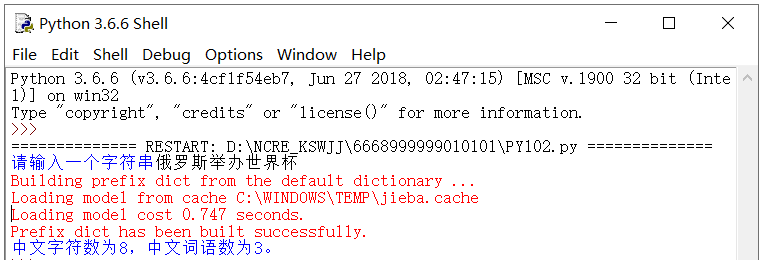
- 中文字符数:n = len(s)
- 中文词语数:m = len(jieba.lcut(s))
答案:
# 请在______处使用一行代码或表达式替换
# 注意:请不要修改其他已给出代码
import jieba
s = input("请输入一个字符串")
n = len(s)
m = len(jieba.lcut(s))
print("中文字符数为{},中文词语数为{}。".format(n, m))
运行结果: