5.某宝店铺分析(电商模式)
SQL180 某宝店铺的SPU数量
select style_id,
count(item_id) as SPU_num
from product_tb
group by style_id
order by SPU_num desc
SQL181 某宝店铺的实际销售额与客单价
select
sum(sales_price) as sales_total,
round(sum(sales_price)/count(distinct user_id),2) as per_trans
from sales_tb
SQL182 某宝店铺折扣率
- 题目中sales_price是结算金额,不要像我一样把他当成单个产品的售出金额,又给他乘一遍sales_num)
select
round(sum(sales_price)/sum(tag_price*sales_num)*100,2) as discount_rate
from product_tb
join sales_tb using(item_id)
SQL183 某宝店铺动销率与售罄率
- 第一次是这么写的,但是结果都偏小。 原因是:库存表与销售表连接之后对应的每条sku的库存记录不是唯一的,inventory会有重复的计算,直接计算结果偏小。举个例子,sales_tb里有两个A003,就会返回两个A003对应的inventory,所以需要去重。
select style_id,
round(sum(sales_num)/(sum(inventory)-sum(sales_num))*100,2) as pin_rate,
round(sum(sales_price)/sum(tag_price*inventory)*100,2) as sell_through_rate
from product_tb
left join sales_tb using(item_id)
group by style_id
order by style_id
- 下面是正确的写法,先通过item_id进行分组,求出每个item_id下售出的商品数量以及GMV,再通过style_id进行分组,求出每个style_id下的商品动销率和售空率
select style_id,
round(sum(num)/(sum(inventory)-sum(num))*100,2) as pin_rate,
round(sum(GMV)/sum(tag_price*inventory)*100,2) as sell_through_rate
from product_tb as a
join (
select item_id,
sum(sales_num) as num,
sum(sales_price) as GMV
from sales_tb
group by item_id
) as b
on a.item_id=b.item_id
group by style_id
order by style_id
- 通过对inventory去重,也可以得到正确答案 。但是当product_tb表中存在多个产品的inventory数量相同时,结果就会是错的。
select style_id,
round(sum(sales_num)/(sum(distinct inventory)-sum(sales_num))*100,2),
round(sum(sales_price)/sum(distinct((tag_price*inventory)))*100,2)
from product_tb
join sales_tb using(item_id)
group by style_id
SQL184 某宝店铺连续2天及以上购物的用户及其对应天数
-
本题类似于167题的算法,难点在于计算出连续的天数。
-
解题思路:首先对日期进行排序,其次判断连续日期,并查询统计连续天数>=2的用户即可
-
判断连续日期的方法:
第一步,对日期去重后进行排序(或者直接用dense_rank进行排序,这是因为dense_rank对于重复的日期,在排序上是相同的,如果是同一天,所以不用再考虑重复日期的影响);
第二步,日期减去排序对应序号的天数如果是一个相同的值,则说明这些日期就是连续的。
第三步,对连续的日期再次排序就得到了最大的连续数列。
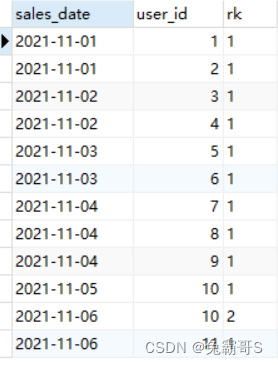
-
判断连续日期,并查询统计连续天数>=2的用户的方法:
使用date_sub()函数并聚合后判断日期连续
如果sales_date 减去rk(天)是相同的日期,则说明他们这些天都是连续的日期(所以要使用dense_rank()并且对日期进行去重,不然重复的日期也会被记作连续的天数)。
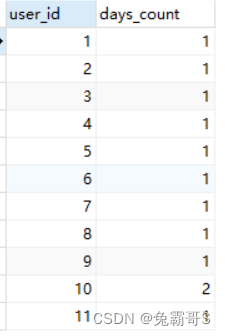
-
count(1)和count()之间没有区别,因为count()count(1)都不会去过滤空值。但count(1)的计算效率要高于 count(*)
select user_id,
count(1) as days_count
from (
select distinct sales_date,
user_id,
dense_rank()over(partition by user_id order by sales_date)rk
FROM sales_tb
)t1
group by user_id,
date_sub(sales_date,interval rk day)
HAVING count(1)>=2;