目录

一、程序和进程
程序:一段代码,这个代码规定了将来运行时程序执行的流程
进程:一个程序运行起来之后,代码+用到的资源(cpu、内存、网络等)称之为进程,它是操作系统分配资源的基本单位
二、创建进程
from multiprocessing import Process
import time
def test():
"""子进程单独执行代码"""
while True:
print("这是子进程")
time.sleep(1)
if __name__ == '__main__':
p = Process(target=test)
p.start()
# 主进程单独执行的代码
while True:
print("这是主进程")
time.sleep(1)

三、使用类的方式来创建进程
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
while True:
print("我是子进程")
time.sleep(1)
if __name__ == '__main__':
p = MyProcess()
p.start()
while True:
print("这是主进程")
time.sleep(1)

四、创建 进程对象的时候传递参数
import multiprocessing
def task(name, age, **kwargs):
print("name:", name)
print("age:", age)
print(kwargs)
if __name__ == '__main__':
p = multiprocessing.Process(target=task, args=("李明", 18), kwargs={"m": 10})
p.start()

五、 进程是不共享全局变量的
线程可以共享全局变量,但是进程是不可以共享全局变量的。
import multiprocessing
import time
NUM = 100
def task1():
global NUM
NUM = 200
print("----in task1 num:%d" % NUM)
def task2():
print("----in task2 num:%d" % NUM)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p1.start()
time.sleep(1) # 确保进程1修改了NUM
p2.start()
为什么进程会不共享全局变量?
①当创建一个子进程的时候,会复制父进程的很多东西(全局变量等)
②子进程和主进程都是单独的2个进程,不是一个,当一个进程结束的时候,不会对其他进程产生影响
③所有的线程都在同一个进程中,这个进程是主进程。
④当一个程序运行之后,会默认叫做主进程,这个进程中有1个默认的线程,叫主线程。进程是资源+代码的统称。线程是真正执行代码的。

六、进程间通信(IPC)---Queue
不同电脑上的进程间通信---socket
同一台电脑不同进程间的通信---文件、共享内存(内存映射)、管道。
队列:
from multiprocessing import Queue
q = Queue(3) # 初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) # false full()判断队列是否已满
q.put("消息3") # true
print(q.full())
# 因为消息队列已满,所以会导致下面的try都会抛出异常
# 第一个try会等待2秒,看是否能成功添加,不能就会抛出异常
# 第二个try会立刻抛出异常
try:
q.put("消息4", timeout=2)
except:
print("消息队列已满,现有消息数量%s" % q.qsize())
try:
q.put_nowait("消息4")
except:
print("消息队列已满,现有消息数量%s" % q.qsize())
# 推荐的方式,先判断消息队列是否已满,再写入
if not q.full():
q.put_nowait("消息4")
# 读取消息时,先判断消息队列是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
进程中使用队列:
import multiprocessing
import time
def task1(q):
for i in ["A", "B", "C"]:
q.put(i)
def task2(q):
while True:
time.sleep(0.5)
if not q.empty():
value = q.get()
print("提取出来的数据是:", value)
else:
break
if __name__ == '__main__':
q = multiprocessing.Queue()
p1 = multiprocessing.Process(target=task1, args=(q,))
p2 = multiprocessing.Process(target=task2, args=(q,))
p1.start()
p2.start() 
小结:
(1)进程之间是独立的,所有的数据各自用各自的,因此为了能够让这些进程之间共享数据,不能使用全局变量,可以使用Linux(Unix)给出的解决方案:
①进程间通信(IPC):管道、命名管道、socket(重点)----能够实现多台电脑上的进程间通信等等
②为了更加简单的实现进程间的通信,可以使用队列Queue

七、进程vs线程
进程:能够完成多任务,比如在一台电脑上能够同时运行多个qq
线程:能够完成多任务,比如一个qq中的多个聊天窗口
①进程是系统进行资源分配和调度的一个单独单位。线程是进程的一个实体,是cpu调度和分配的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源
②一个程序至少有一个进程,一个进程至少有一个线程。线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。进行在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序地运行效率。线程是不能独立执行,必须存在于进程中
③线程开销小,但不利于资源地管理和保护,而进程相反
八、进程池
如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。进程可以重复用,就可以节约创建进程和销毁进程的资源
from multiprocessing import Pool
import os
import time
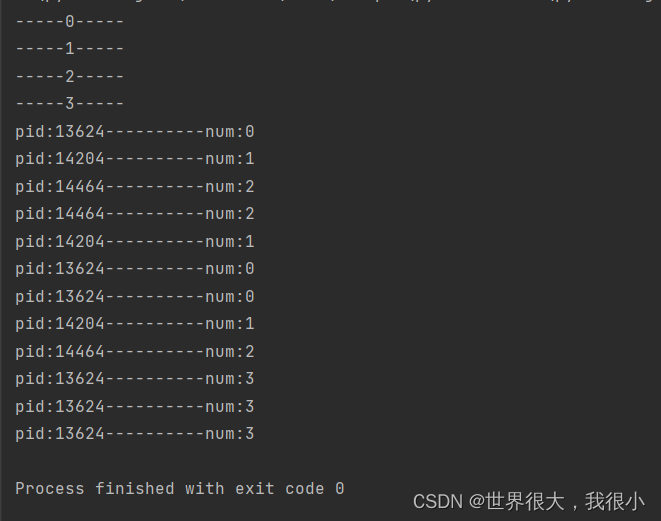
def worker(num):
for i in range(3):
print("pid:%d----------num:%d" % (os.getpid(), num))
time.sleep(1)
if __name__ == '__main__':
# 3表示进程池中最多有三个进程一起执行
pool = Pool(3)
for i in range(3):
print('-----%d-----' % i)
# 向进程池中添加任务
# 注意:如果添加的任务数量超过了进程池中进程的个数的话,那么就不会接着往进程池中添加
# 如果还没有执行的话,他会等待前面的进程结束,然后在往里面添加。
pool.apply_async(worker, (i,))
pool.close() # 关闭进程池
pool.join() # 主进程在这里等待,只有子进程全部结束之后,在开启主线程 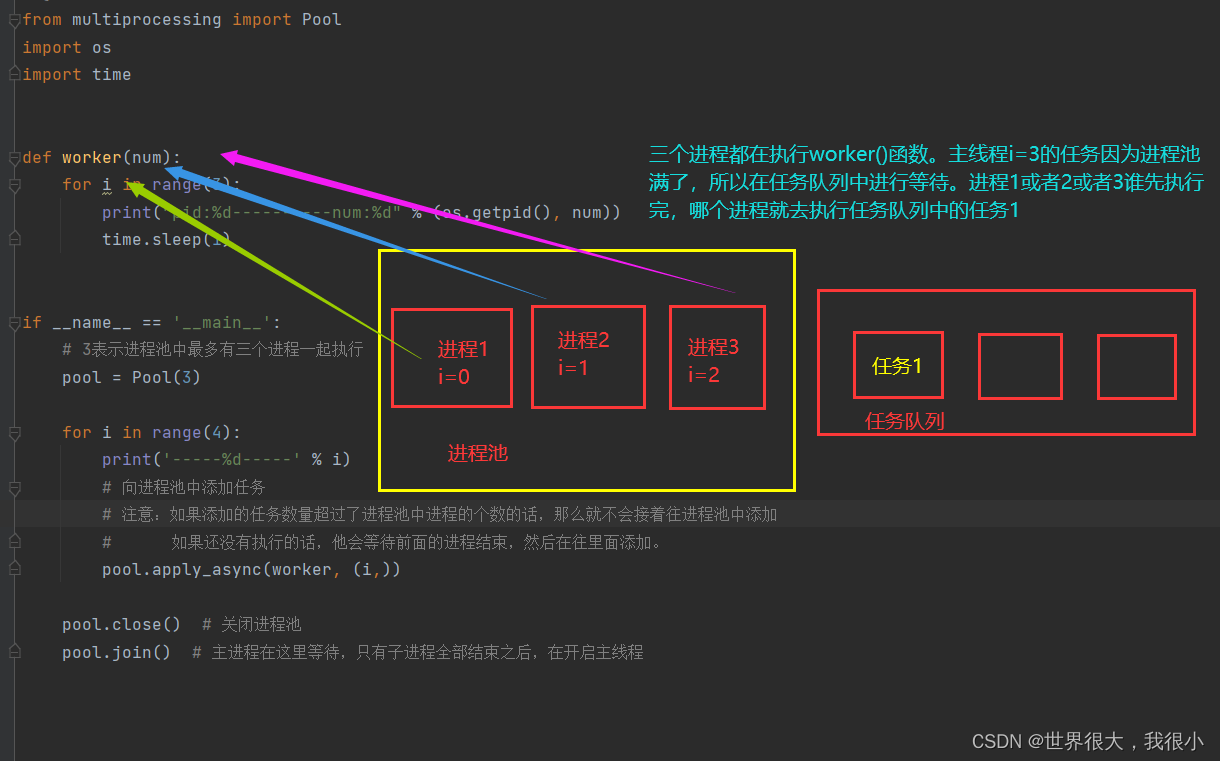
join的作用:
回收资源,防止僵尸进程,浪费资源
九、进程池间的通信
from multiprocessing import Pool, Manager
import os
import time
def reader(q):
print("read启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("read从Queue获取到消息:%s" % q.get())
def writer(q):
print("write启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)
if __name__ == '__main__':
q = Manager().Queue()
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
