一、简单查询

二、条件查询

三、操作单表中的数据

四、数据库约束


五、数据库的事务处理

六、多表关系设计:
七、*多表查询:

八、范式:

#创建数据库(数据名称(如demo),关键字=>大写 ; 数据库名、表名、字段名=>小写)
CREATE DATABASE demo;
#判断是否存在=》不存在则创建
CREATE DATABASE IF NOT EXISTS demo;
#指定字符集=》默认Latin1
CREATE DATABASE demo CHARACTER SET utf8;
#查看数据库
SHOW DATABASES;
#查看某个数据库的详细信息
#CREATE DATABASE `demo` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci */
SHOW CREATE DATABASE demo;
#删除数据库
DROP DATABASE demo;
#使用(选中)数据库
USE demo;
#查看当前正在执行的数据库
SELECT DATABASE();
#创建表(sys_user)和字段
CREATE TABLE sys_user (
#字段名称 字段类型
uid INT AUTO_INCREMENT COMMENT '用户id',
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名',
password CHAR(32) NOT NULL COMMENT '密码',
salt CHAR(36) COMMENT '盐值',
phone VARCHAR(20) COMMENT '电话号码',
email VARCHAR(30) COMMENT '电子邮箱',
gender INT COMMENT '性别:0-女,1-男',
avatar VARCHAR(50) COMMENT '头像',
is_delete INT COMMENT '是否删除:0-未删除,1-已删除',
created_user VARCHAR(20) COMMENT '日志-创建人',
created_time DATETIME COMMENT '日志-创建时间',
modified_user VARCHAR(20) COMMENT '日志-最后修改执行人',
modified_time DATETIME COMMENT '日志-最后修改时间',
#指定主键(最后','需要省略)
PRIMARY KEY (uid)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#快速通过原有的表结构来构建一个新的一模一样的表(旧sys_user=》新sys_user副本)
CREATE TABLE sys_user副本 LIKE sys_user;
#数据类型
#【菜鸟教程】 https://www.runoob.com/mysql/mysql-data-types.html
#char与varchar的区别:
#都是保存字符串的,对应JAVA中的String类型
#区别:
# char:固定长度的字符串(其剩余空间,别的不能用),浪费存储空间,效率高;
# varchar:可变长度的字符串(VARCHAR(50)最大能存储50个字节),效率低(频繁扩容或缩容操作);节省存储空间
#使用场景:
# char:性别,身份证号码,手机号
# varchar:一定范围内变化的字符串
#查看当前数据库中所有表
SHOW TABLES;
#查看数据库中某张表的结构(表的字段信息)
DESC sys_user;
#查看数据库中某张表的SQL语句定义
SHOW CREATE TABLE sys_user;
#`:半角符号=》用来标记名称(避免关键字重复);主要用来修饰字段,表,数据库名,(索引名、视图名...);可以省略
USE demo;
#删除表(彻底删除,没办法恢复)
DROP TABLE sys_user副本;
#判断表是否存在(存在则删除,不存在则不执行)
DROP TABLE IF EXISTS sys_user副本;
#修改表的名称(旧sys_user=》新t_user)
RENAME TABLE sys_user to t_user;
#修改表的默认字符集编码(GBK)
ALTER TABLE t_user CHARACTER SET GBK;
#查看数据库中某张表的SQL语句定义
SHOW CREATE TABLE t_user;
#向表中添加新的字段
ALTER TABLE t_user ADD cdesc VARCHAR(20);
#修改原有字段的长度、数据类型
ALTER TABLE t_user MODIFY cdesc CHAR(30);
#修改原有字段的名称、长度、数据类型
ALTER TABLE t_user CHANGE cdesc descption VARCHAR (30);
#废弃(删除)字段
ALTER TABLE t_user DROP descption;
#插入数据(部分字段=>字段声明不能省略)
INSERT INTO t_user (username,password) VALUES ("admin",123456);
#插入数据(全部字段=>全部指定了值,才可省略)
INSERT INTO t_user VALUES ("admin",123456,...);
#更新(修改)数据(没有指定条件则更新整列)
UPDATE t_user SET (username="管理员",password=123);
#更新(修改)数据(有指定条件则更新受影响的列)
UPDATE t_user SET (username="管理员",password=123) WHERE id=1;
#删除数据(不加条件则清空表)
DELETE FROM t_user;
#删除表中所有数据
TRUNCATE TABLE t_user;
#delete与truncate的区别:
# delete:逐行进行数据的删除,效率低
# truncate:先把指定的表直接删除,再重新创建一张一模一样的表
#删除数据(加条件)
DELETE FROM t_user WHERE password=123456;
#查询全部数据
SELECT * FROM t_user
#查询指定字段的数据
SELECT uid,username,password FROM t_user
#清除重复数据值DISTINCT
SELECT DISTINCT username FROM t_user
#指定列的别名查询(as可以省略,单引号可以省略)
SELECT username 用户名,password as '密码' FROM t_user;
#字符和固定某个数值进行运算 select 字段名称+固定值 from 表名;
SELECT username,password + 1 FROM t_user;
#字段和字段之间进行数值运算(数值类型) select 字段名称1+字段名称2 from 表名;
SELECT username,password + password 密码 FROM t_user;
#条件查询:比较运算符
#>,>=,<,<=,=,!=,<> <>表示不等于(!=),没有==
#between ... and ... 显示在某一区间的值
#IN(集合) 集合表示多个值,使用逗号分隔;字段值=集合里面的值=》输出
#LIKE 通配符 模糊查询=>%:任意多个字符串;_:匹配一个任意的字符串
#IS NULL 查询某一列为NULL的值,注:不能写=NULL
SELECT * FROM t_user WHERE username='1';
SELECT * FROM t_user WHERE password BETWEEN 3 AND 1234567;
SELECT * FROM t_user WHERE password IN( 3, 1234567);
SELECT * FROM t_user WHERE password LIKE '%2%';#包含2
SELECT * FROM t_user WHERE password LIKE '2%';#2开头
SELECT * FROM t_user WHERE password LIKE '_2%';#2在第二位的
SELECT * FROM t_user WHERE password LIKE '__2%';#2在第三位的
SELECT * FROM t_user WHERE username IS NULL;
SELECT * FROM t_user WHERE username IS NOT NULL;
#条件查询:逻辑运算符
#AND或&& 与,多个条件同时成立
#OR或|| 或,多个条件任意成立
#NOT或! 非,不成立,即取反
SELECT * FROM t_user WHERE username='2' AND password='2';
SELECT * FROM t_user WHERE username='2' OR password='3';
SELECT * FROM t_user WHERE NOT username='2';
SELECT * FROM t_user WHERE username NOT IN ('2');
#1.数据库访问表复制
#创建一个数据库,如CREATE DATABASE db CHARACTER SET utf8;
#工具=》数据传输
#2.排序
#单列排序 ORDER BY ASC(升序)/DESC(降序),默认ASC(升序)
SELECT * FROM t_user ORDER BY created_time DESC;
SELECT * FROM t_user ORDER BY created_time ASC;
#组合排序(前一个字段相同,自动比较后一个字段)
SELECT * FROM t_user ORDER BY created_time DESC, update_time DESC;
#3.聚合函数
#count 统计行数(NULL除外),使用*代替某一个字段
#sum 计算列的数值和
#max 最大值
#min 最小值
#avg 平均值
SELECT count(password) FROM t_user;
SELECT count(*) FROM t_user;
SELECT sum(password) FROM t_user;
#4.分组 GROUP BY
SELECT username,avg(password) FROM t_user GROUP BY username;
#查询部门的平均薪资
SELECT dept_name '部门名称',avg(salary) '平均薪资' FROM emp GROUP BY dept_name;
SELECT dept_name '部门名称',avg(salary) '平均薪资' FROM emp where dept_name IS NOT NULL GROUP BY dept_name;
#查询部门的平均薪资大于6000的部门 having:用于分组后进一步添加过滤条件
SELECT dept_name '部门名称',avg(salary) '平均薪资' FROM emp where dept_name IS NOT NULL GROUP BY dept_name HAVING avg(salary)>6000;
SELECT dept_name '部门名称',avg(salary) '平均薪资' FROM emp GROUP BY dept_name HAVING avg(salary)>6000 AND dept_name IS NOT NULL;
#having与where的区别:
# where:分组前执行过滤,后面不能声明聚合函数
# having:分组后执行过滤,后面可以声明聚合函数
#5.分页 limit off,length 整数类型;取>=0的数字;off:起始行;length:显示条数
SELECT * FROM t_user LIMIT 0,2;
#起始行为0可以省略
SELECT * FROM t_user LIMIT 2;
#从第2条数据开始,连续查看4条
SELECT * FROM t_user LIMIT 2,4;
#分页操作
SELECT * FROM t_user LIMIT (当前页-1)*每页条数,每页条数;
#SQL约束(防止不正确、不安全的数据保存到数据库中)
# 主键约束:primary key
# 唯一约束:unique
# 非空约束:not null
# 外键约束:foreign key
#主键约束:不可重复、唯一、非空=>字段名称 字段类型 PRIMARY KEY
#方式1:
CREATE TABLE sys_user (
#字段名称 字段类型
uid INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户id',#AUTO_INCREMENT自增
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名',
);
#方式2:字段声明后
CREATE TABLE sys_user (
#字段名称 字段类型
uid INT AUTO_INCREMENT COMMENT '用户id',
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名',
#指定主键(最后','需要省略)
PRIMARY KEY (uid)
);
#方式3
ALTER TABLE t_user ADD PRIMARY KEY (uid);
#删除主键约束
ALTER TABLE t_user DROP PRIMARY KEY;
#delete和truncate影响自增:
# delete:只是删除数据,结构不会改变,对自增没有影响
# truncate:将表先删除再创建,所以自增从新开始计数,会影响自增
#唯一约束:=>字段名称 字段类型 UNIQUE
#非空约束:=>字段名称 字段类型 NOT NULL
#外键约束:=>字段名称 字段类型 FOREIGN KEY
#默认值 DEFAULT
CREATE TABLE sys_user (
#字段名称 字段类型
uid INT AUTO_INCREMENT COMMENT '用户id',
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名',
password CHAR(32) NOT NULL COMMENT '密码',
is_delete INT DEFAULT 0 COMMENT '是否删除:0-未删除,1-已删除',
PRIMARY KEY (uid)
);
#数据库事务(由多个SQl语句组成,如果有任意一条产生异常,都不能提交数据库;全部正常执行,则提交;反之则回滚到事务执行前状态的数据库)
#回滚:在事务执行过程中,如果产生异常,则恢复到事务执行前的状态
#模拟转账业务:tom向jack转账500
UPDATE account SET money=money-500 WHERE username='tom';#此时服务器宕机了
UPDATE account SET money=money+500 WHERE username='jack';
#1、手动提交事务:(有异常会自动调用rollback;即使执行了comment,也不会影响数据库)
#开启事务 start transaction或begin
#提交事务 comment
#回滚事务 rollback
BEGIN;
UPDATE account SET money=money-500 WHERE username='tom';#此时服务器宕机了
UPDATE account SET money=money+500 WHERE username='jack';
COMMENT;
#2、自动提交事务(默认方式,导致上述问题):
#全局变量autocommit:ON:开启;OFF:关闭
#查看当前事务的默认提交方式
SHOW VARIABLES LIKE 'autocommit';
#修改默认提交方式(非自动,记得改回默认ON状态) 属性名需要使用@@开头
SET @@autocommit=OFF;#改为非自动后,执行sql语句要加COMMENT;
#3、四大特性及事务隔离级别:
#原子性:所有sql语句要么都执行成功,要么都失败
#一致性:如转账前,总金额2000;转账后,总金额也是2000
#隔离性:事务与事务之间互不影响
#持久性:一旦执行成功,修改就是持久的
#数据库并发问题:多用户同时涌入到服务器中,可能导致一些数据库问题=>解决:事务隔离级别
# 脏读 一个事务读取到另一个事务尚未提交的数据
# 不可重复读 一个事务中两次读取的数据不一致,但要求是一致的,进行update操作时引发的问题
# 幻读 查询得到的数据状态不准确,导致幻读
#四种隔离级别:(上面的级别最低,下面的级别最高)
# 1 读未提交 read uncommitted 脏读 不可重复读 幻读
# 2 读已提交 read committed 不可重复读 幻读 Oracle和SQLServer
# 3 可重复读 repeatable read 幻读 MySQL(MariaDB)
# 4 串行化 serializable serializable可以彻底解决幻读,但事务只能排队执行,严重影响效率(不会使用)
#查询当前数据库的隔离级别(默认级别)
SELECT @@tx_isolation;
#修改默认访问隔离级别:SET GLOBAL TRANSACTION ISOLATION LEVEL 隔离级别名称(read uncommitted/read committed/repeatable read/serializable);
SET GLOBAL TRANSACTION ISOLATION LEVEL serializable; #=》设置完后,需要重启软件
#创建外键约束语法
#前提条件,表中的数据是合法的,已经是有正确的映射关系的(即从表的外键字段名 在外键表主键里面都存在)
#表已存在创建外键:ALTER TABLE 从表名 CONSTRAINT 外键约束的名称 ADD FOREIGN KEY 外键字段名 REFERENCES 主表名(外键表主键)
ALTER TABLE employee CONSTRAINT emp_dept_fk ADD FOREIGN KEY (dept_id) REFERENCES department (id);
#或者
ALTER TABLE employee ADD FOREIGN KEY (dept_id) REFERENCES department (id);
#在创建表同时创建外键:字段名称 字段类型 FOREIGN KEY
CREATE TABLE sys_user (
#字段名称 字段类型,
CONSTRAINT 外键约束的名称 ADD FOREIGN KEY 外键字段名 REFERENCES 主表名(外键表主键)
);
#删除外键约束:ALTER TABLE 从表名 DROP FOREIGN KEY 外键的名称;
ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk;
#外键约束的注意事项:
#1.从表外键与主表主键:数据类型一致
#2.先添加主表中的数据,再添加从表中的数据
#3.先删除从表中的数据,再删除主表中的数据
#级联操作:主表中的数据内容被删除/更新,从表中被关联的所有数据被自动全部删除/更新
#1.级联删除:ON DELETE CASCADE
ALTER TABLE 从表名 CONSTRAINT 外键约束的名称 ADD FOREIGN KEY 外键字段名 REFERENCES 主表名(外键表主键)ON DELETE CASCADE;
#或者
CREATE TABLE sys_user (
#字段名称 字段类型,
CONSTRAINT 外键约束的名称 ADD FOREIGN KEY 外键字段名 REFERENCES 主表名(外键表主键) ON DELETE CASCADE
);
#2.级联更新:ON UPDATE CASCADE
ALTER TABLE 从表名 CONSTRAINT 外键约束的名称 ADD FOREIGN KEY 外键字段名 REFERENCES 主表名(外键表主键)ON UPDATE CASCADE;
#3.级联删除和级联更新:ON DELETE CASCADE ON UPDATE CASCADE
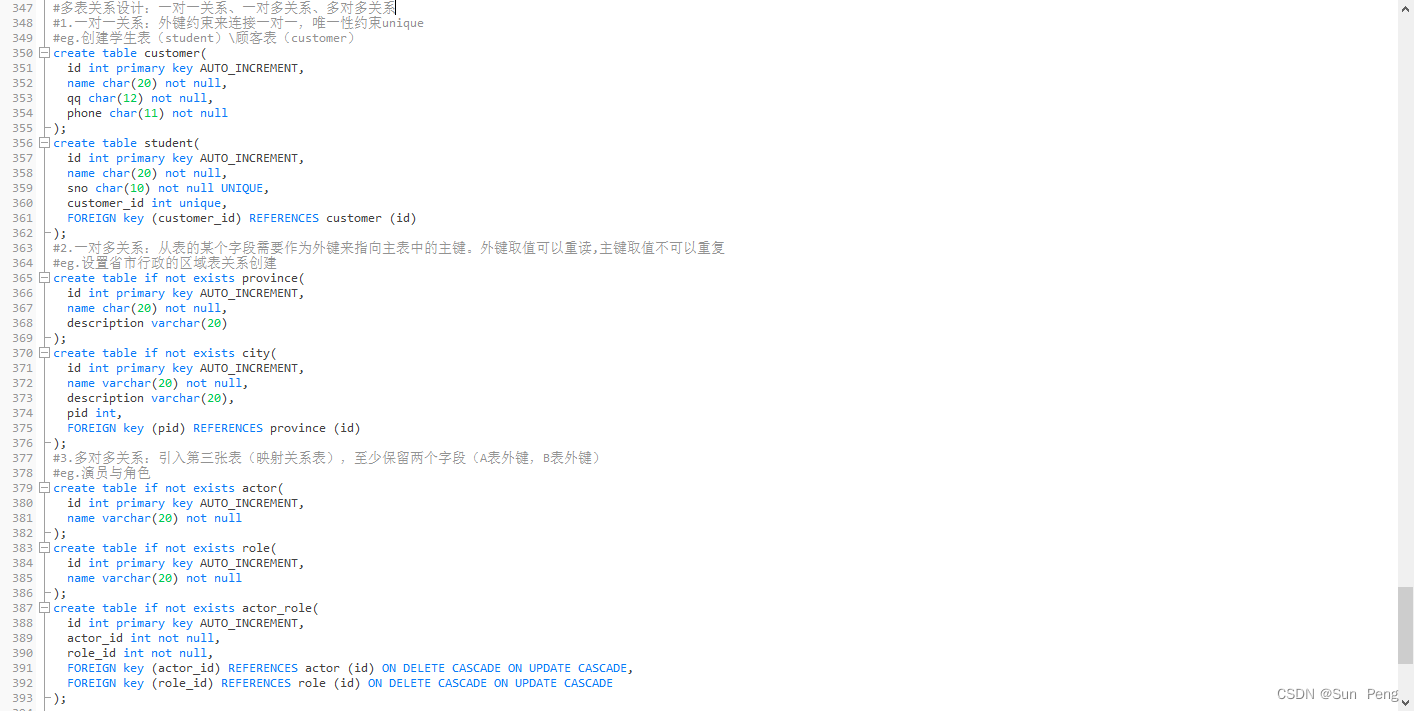
#多表关系设计:一对一关系、一对多关系、多对多关系
#1.一对一关系:外键约束来连接一对一,唯一性约束unique
#eg.创建学生表(student)\顾客表(customer)
create table customer(
id int primary key AUTO_INCREMENT,
name char(20) not null,
qq char(12) not null,
phone char(11) not null
);
create table student(
id int primary key AUTO_INCREMENT,
name char(20) not null,
sno char(10) not null UNIQUE,
customer_id int unique,
FOREIGN key (customer_id) REFERENCES customer (id)
);
#2.一对多关系:从表的某个字段需要作为外键来指向主表中的主键。外键取值可以重读,主键取值不可以重复
#eg.设置省市行政的区域表关系创建
create table if not exists province(
id int primary key AUTO_INCREMENT,
name char(20) not null,
description varchar(20)
);
create table if not exists city(
id int primary key AUTO_INCREMENT,
name varchar(20) not null,
description varchar(20),
pid int,
FOREIGN key (pid) REFERENCES province (id)
);
#3.多对多关系:引入第三张表(映射关系表),至少保留两个字段(A表外键,B表外键)
#eg.演员与角色
create table if not exists actor(
id int primary key AUTO_INCREMENT,
name varchar(20) not null
);
create table if not exists role(
id int primary key AUTO_INCREMENT,
name varchar(20) not null
);
create table if not exists actor_role(
id int primary key AUTO_INCREMENT,
actor_id int not null,
role_id int not null,
FOREIGN key (actor_id) REFERENCES actor (id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN key (role_id) REFERENCES role (id) ON DELETE CASCADE ON UPDATE CASCADE
);
#多表查询
SELECT 字段列表 FROM 表名1,表名2,...;
#笛卡尔积问题:多表查询中数据冗余问题
#内连接:使用比较运算符进行表的某列数据的比较操作,并将满足的结果重新组合展示给用户(从表的外键=主表的主键) 两表交集
# 1.隐式内连接:使用where关键字将比较运算符,作为多表连接条件=>SELECT 字段列表 FROM 表名1,表名2 WHERE 关联条件;
SELECT * FROM province,city WHERE province.id=city.pid AND province.name='北京市';
# 2.显式内连接:JOIN...ON=>SELECT 字段列表 FROM 表名1 [INNER] JOIN 表名2 ON 关联条件;
SELECT * FROM province JOIN city ON province.id=city.pid WHERE province.name='北京市';
#外连接:
# 1.左外连接:LEFT JOIN 左表作为基表,和右表进行数据匹配,如果右表中没有数据与之匹配,则左表数据保留,右表使用null值来显示 左表全部,右表交集
SELECT * FROM 左表 LEFT [OUTER] JOIN 右表 ON 关联条件;#[OUTER]表示OUTER关键字可以省略
#eg:SELECT c.cname '商品分类名',count(p.pname) '商品总数' FROM category c LEFT JOIN products p ON c.cid=p.category_id GROUP BY c.cname;
# 2.右外连接:RIGHT JOIN
SELECT * FROM 右表 RIGHT [OUTER] JOIN 左表 ON 关联条件;
#子查询:一个查询语句作为另一个查询的条件时
# 1.使用结构:
# WHERE型子查询:将内层查询结果作为外层查询条件
SELECT 字段列表 FROM 表名 WHERE 字符名 = (或者字段名 IN) (SELECT 字段列表 FROM 表名 WHERE ...);
# FROM型子查询:将内层查询结果作为外层查询的临时表(需要起别名)
SELECT 字段列表 FROM (SELECT 字段列表 FROM 表名 WHERE ...) 别名 WHERE ...;
# EXISTS型子查询:把外层查询结果拿到内层去测试比较,如果内层的SQL语句成立,则显示;否则不显示
SELECT 字段列表 FROM 表名 WHERE EXISTS(SELECT 字段列表 FROM 表名 WHERE ...);
# 2.返回结果:
# 标量子查询:子查询返回一个一行一列(一个数据)
# 列子查询:返回一列多行(一列数据)
# 行子查询:返回一行多列(一行数据)
# 表子查询:返回多行多列(二维表)
#范式:
#第一范式:列不可拆分
#第二范式:一张表只能描述一件事
#第三范式:消除传递依赖(空间最省原则),不能存在可以被推导出来的列
#反三范式:通过增加冗余或重复的数据来提高数据库的读取性能(以空间换时间)
#索引:提升查询效率和运行速度
#frm:表结构文件
#ibd:表中数据和索引内容
# 1.普通索引:条件查询,排序操作
#(1)
CREATE TABLE 表名(
字段名 数据类型,
INDEX [索引名] (字段名);#eg:INDEX index_name (name)
);
#(2)在已有表上添加索引
CREATE INDEX 索引名 ON 表名 (字段名);
#(3)修改表结构添加索引
ALTER TABLE 表名 ADD INDEX 索引名 (字段名);
# 2.唯一索引:索引列的值只出现一次,唯一性,可以为NULL(只能出现一次)
#(1)
CREATE TABLE 表名(
字段名 数据类型,
UNIQUE INDEX [索引名] (字段名);#eg:UNIQUE INDEX index_name (name)
);
#(2)
CREATE UNIQUE INDEX 索引名 ON 表名 (字段名);
#(3)
ALTER TABLE 表名 ADD UNIQUE INDEX 索引名 (字段名);
# 3.主键索引:PRIMARY KEY
#(1)
CREATE TABLE 表名(
字段名 数据类型 PRIMARY KEY,
);
#(2)
ALTER TABLE 表名 ADD PRIMARY KEY (字段名);
#删除普通/唯一索引:
ALTER TABLE 表名 DROP INDEX 索引名;
#删除主键索引:(前提:主键没有添加自增=》解决:ALTER TABLE 表名 modify 主键字段 主键类型=》ALTER TABLE 表名 DROP PRIMARY KEY;)
ALTER TABLE 表名 DROP PRIMARY KEY;