文章目录

Flink 中的Table API & SQL
一、Table API & SQL 介绍
1. 为什么要Table API和SQL
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/overview/

Flink的Table模块包括 Table API 和 SQL:
Table API 是一种类SQL的API,通过Table API,用户可以像操作表一样操作数据,非常直观和方便
SQL作为一种声明式语言,有着标准的语法和规范,用户可以不用关心底层实现即可进行数据的处理,非常易于上手
Flink Table API 和 SQL 的实现上有80%左右的代码是公用的。作为一个流批统一的计算引擎,Flink 的 Runtime 层是统一的。
2. Table API & SQL的特点
Flink之所以选择将 Table API & SQL 作为未来的核心 API,是因为其具有一些非常重要的特点:

- 声明式:属于设定式语言,用户只要表达清楚需求即可,不需要了解底层执行;
- 高性能:可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
- 简单易学:易于理解,不同行业和领域的人都懂,学习成本较低;
- 标准稳定:语义遵循SQL标准,非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
- 流批统一:可以做到API层面上流与批的统一,相同的SQL逻辑,既可流模式运行,也可批模式运行,Flink底层Runtime本身就是一个流与批统一的引擎
3. Table API& SQL发展历程
3.1 架构升级
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。随着版本的不断更新,API 也出现了很多不兼容的地方。
在 Flink 1.9 中,Table 模块迎来了核心架构的升级,引入了阿里巴巴Blink团队贡献的诸多功能
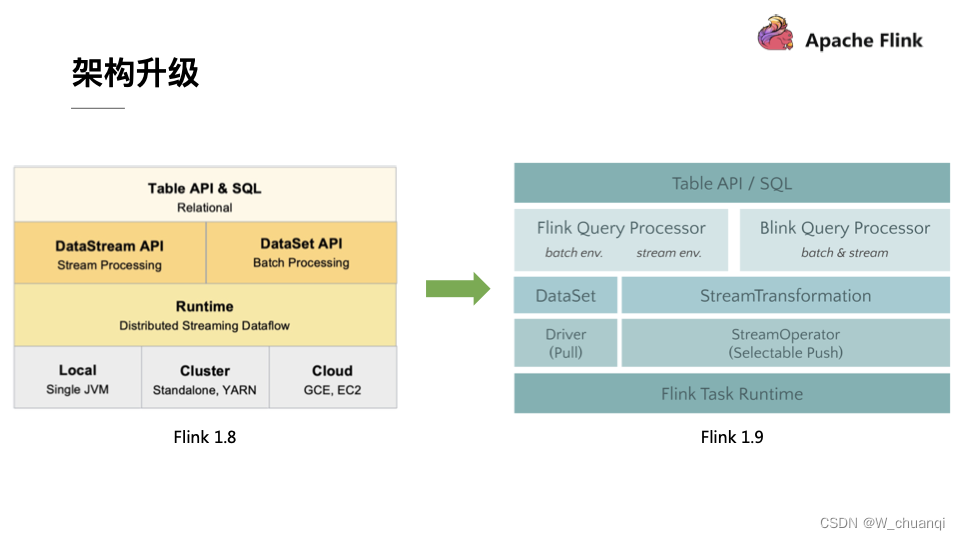
在Flink 1.9 之前,Flink API 层 一直分为DataStream API 和 DataSet API,Table API & SQL 位于 DataStream API 和 DataSet API 之上。可以看处流处理和批处理有各自独立的api (流处理DataStream,批处理DataSet)。而且有不同的执行计划解析过程,codegen过程也完全不一样,完全没有流批一体的概念,面向用户不太友好。
在Flink1.9之后新的架构中,有两个查询处理器:Flink Query Processor,也称作Old Planner和Blink Query Processor,也称作Blink Planner。为了兼容老版本Table及SQL模块,插件化实现了Planner,Flink原有的Flink Planner不变,后期版本会被移除。新增加了Blink Planner,新的代码及特性会在Blink planner模块上实现。批或者流都是通过解析为Stream Transformation来实现的,不像Flink Planner,批是基于Dataset,流是基于DataStream。
3.2 查询处理器的选择
查询处理器是 Planner 的具体实现,通过parser、optimizer、codegen(代码生成技术)等流程将 Table API & SQL作业转换成 Flink Runtime 可识别的 Transformation DAG,最终由 Flink Runtime 进行作业的调度和执行。
Flink Query Processor查询处理器针对流计算和批处理作业有不同的分支处理,流计算作业底层的 API 是 DataStream API, 批处理作业底层的 API 是 DataSet API。
Blink Query Processor查询处理器则实现流批作业接口的统一,底层的 API 都是Transformation,这就意味着我们和Dataset完全没有关系了。
Flink1.11之后Blink Query Processor查询处理器已经是默认的了:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/

3.3 了解-Blink planner和Flink Planner具体区别如下:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/common.html

3.4 了解-Blink planner和Flink Planner具体区别如下:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/common.html

4. 注意事项
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/common/
All Flink Scala APIs are deprecated and will be removed in a future Flink version. You can still build your application in Scala, but you should move to the Java version of either the DataStream and/or Table API.
所有Flink Scala api都已弃用,并将在未来的Flink版本中删除。您仍然可以在Scala中构建应用程序,但是应该使用Java版本的DataStream和/或Table API。
二.、API
- 创建表
- 查询表
- 输出表
三、案例
1. 案例一
将DataStream注册为Table和view并进行SQL统计
1)导入pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.7</version>
</dependency>
</dependencies>
注意本地scala版本:2.12为scala版本。
2)新建包和类
3)代码实现
package cn.edu.hgu.bigdata20.flink.table_demo;
import cn.edu.hgu.bigdata20.flink.mysql.Student;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
import static org.apache.flink.table.api.Expressions.$;
/**
* description:flink的TableAPI和SQL演示
* author 王
* date 2023/04/20
*/
public class FlinkTableDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.table env
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 3.source
DataStream<Student> StudentA = env.fromCollection(Arrays.asList(
new Student(101, "张三", "男", 20, "14567457623", "唐山"),
new Student(102, "李四", "女", 18, "17467457623", "张家口"),
new Student(103, "王五", "男", 19, "18367457623", "承德")
));
DataStream<Student> StudentB = env.fromCollection(Arrays.asList(
new Student(201, "赵六", "女", 21, "18867457623", "秦皇岛"),
new Student(202, "钱七", "男", 19, "17567457623", "邢台"),
new Student(203, "孙八", "女", 18, "16767457623", "廊坊")
));
// 3.注册表
// 3.1 转换一个流为一个表
Table tableA = tEnv.fromDataStream(StudentA, $("id"), $("sname"), $("sex"), $("age"), $("phone"), $("address"));
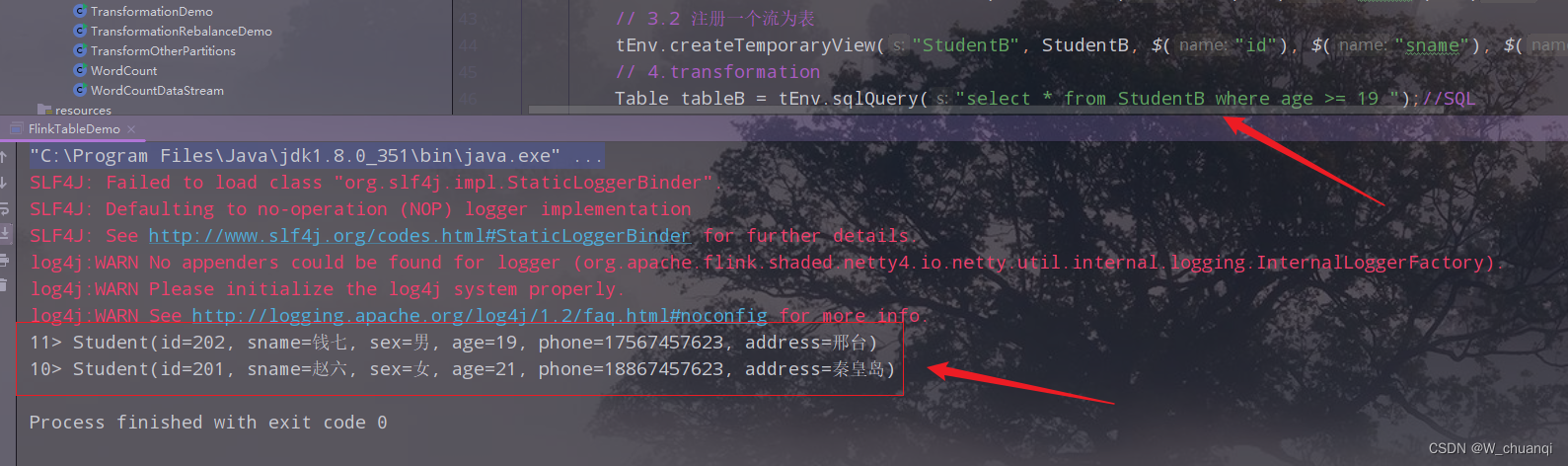
// 3.2 注册一个流为表
tEnv.createTemporaryView("StudentB", StudentB, $("id"), $("sname"), $("sex"), $("age"), $("phone"), $("address"));
// 4.transformation
Table tableB = tEnv.sqlQuery("select * from StudentB where age >= 19 ");//SQL
// 5.sink
// 把表转换为流
DataStream<Student> resultA = tEnv.toAppendStream(tableA, Student.class);
DataStream<Student> resultB = tEnv.toAppendStream(tableB, Student.class)
// tableA.printSchema();
// tableB.printSchema();
// resultA.print();
resultB.print();
// 6.execute
env.execute();
}
}
4)运行,查看结果
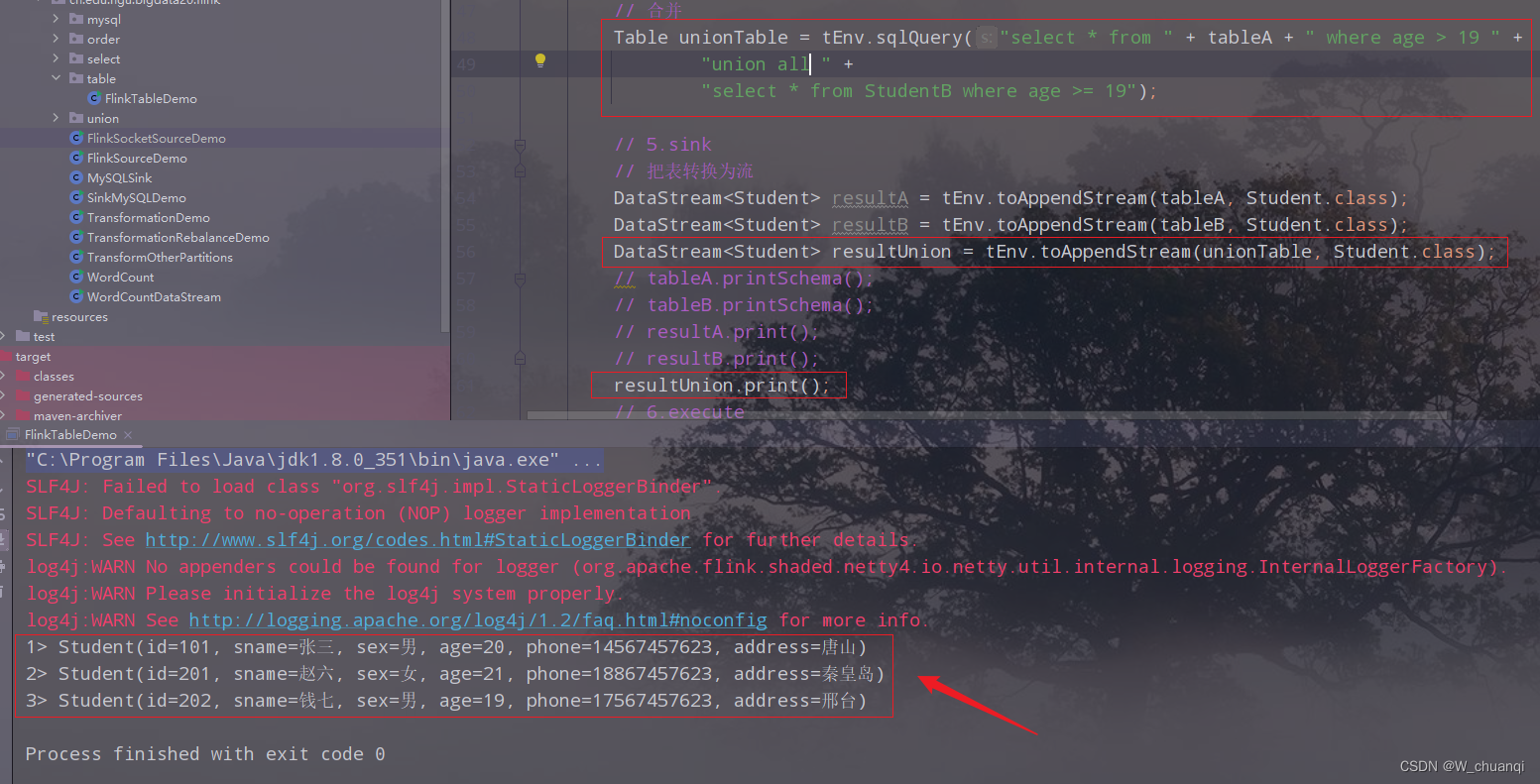
5)表的合并操作
package cn.edu.hgu.bigdata20.flink.table;
import cn.edu.hgu.bigdata20.flink.mysql.Student;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Arrays;
import static org.apache.flink.table.api.Expressions.$;
/**
* description:flink的TableAPI和SQL演示
* author 王
* date 2023/04/20
*/
public class FlinkTableDemo {
public static void main(String[] args) throws Exception {
// 1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.table env
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 3.source
DataStream<Student> StudentA = env.fromCollection(Arrays.asList(
new Student(101, "张三", "男", 20, "14567457623", "唐山"),
new Student(102, "李四", "女", 18, "17467457623", "张家口"),
new Student(103, "王五", "男", 19, "18367457623", "承德")
));
DataStream<Student> StudentB = env.fromCollection(Arrays.asList(
new Student(201, "赵六", "女", 21, "18867457623", "秦皇岛"),
new Student(202, "钱七", "男", 19, "17567457623", "邢台"),
new Student(203, "孙八", "女", 18, "16767457623", "廊坊")
));
// 3.注册表
// 3.1 转换一个流为一个表
Table tableA = tEnv.fromDataStream(StudentA, $("id"), $("sname"), $("sex"), $("age"), $("phone"), $("address"));
// 3.2 注册一个流为表
tEnv.createTemporaryView("StudentB", StudentB, $("id"), $("sname"), $("sex"), $("age"), $("phone"), $("address"));
// 4.transformation
Table tableB = tEnv.sqlQuery("select * from StudentB where age >= 19 ");//SQL
// 合并
Table unionTable = tEnv.sqlQuery("select * from " + tableA + " where age > 19 " +
"union all " +
"select * from StudentB where age >= 19");
// 5.sink
// 把表转换为流
DataStream<Student> resultA = tEnv.toAppendStream(tableA, Student.class);
DataStream<Student> resultB = tEnv.toAppendStream(tableB, Student.class);
DataStream<Student> resultUnion = tEnv.toAppendStream(unionTable, Student.class);
// tableA.printSchema();
// tableB.printSchema();
// resultA.print();
// resultB.print();
resultUnion.print();
// 6.execute
env.execute();
}
}
出现问题:Caused by: org.apache.calcite.sql.parser.SqlParseException: Encountered “<”,可能是符号有问题。
6)合并结果