一、理解
1.1、爬虫:网络爬虫也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。
1.2、Cheerio:Cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的 jQuery核心实现。适合各种Web爬虫程序。
二、待抓取页面分析
2.1、url分页分析
// 第一页地址
https://money.163.com/special/businessnews/
// 第二页地址
https://money.163.com/special/businessnews_02/
// 第三页地址
https://money.163.com/special/businessnews_03/我们通过页面地址分析,url的分页参数在最后一个字段通过 _02 标记,第一页没有,2-9页,是02-09,超过10 正常展示
2.2、列表分析
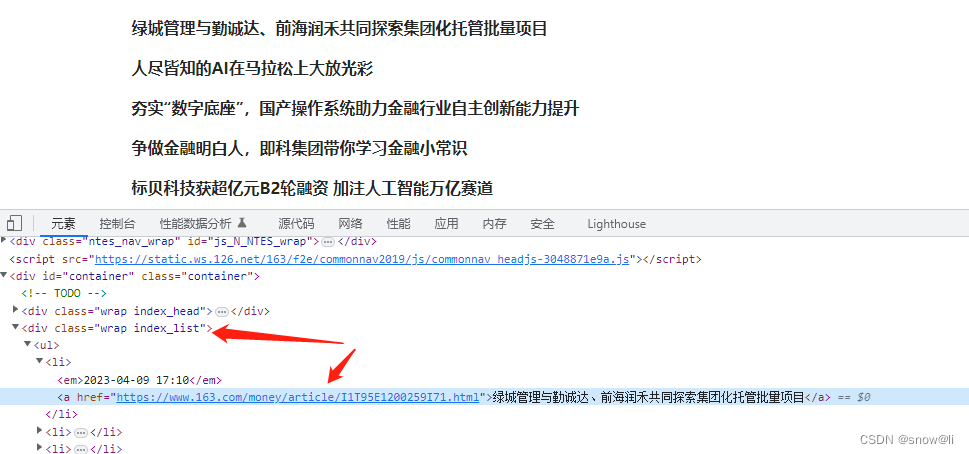
2.3、分页器分析
这里展示了全部的页码,我们可以获取到最后一页的页码数,从而抓取到每一页

2.4、文章详情页分析,找到要抓取的字段,标题,正文
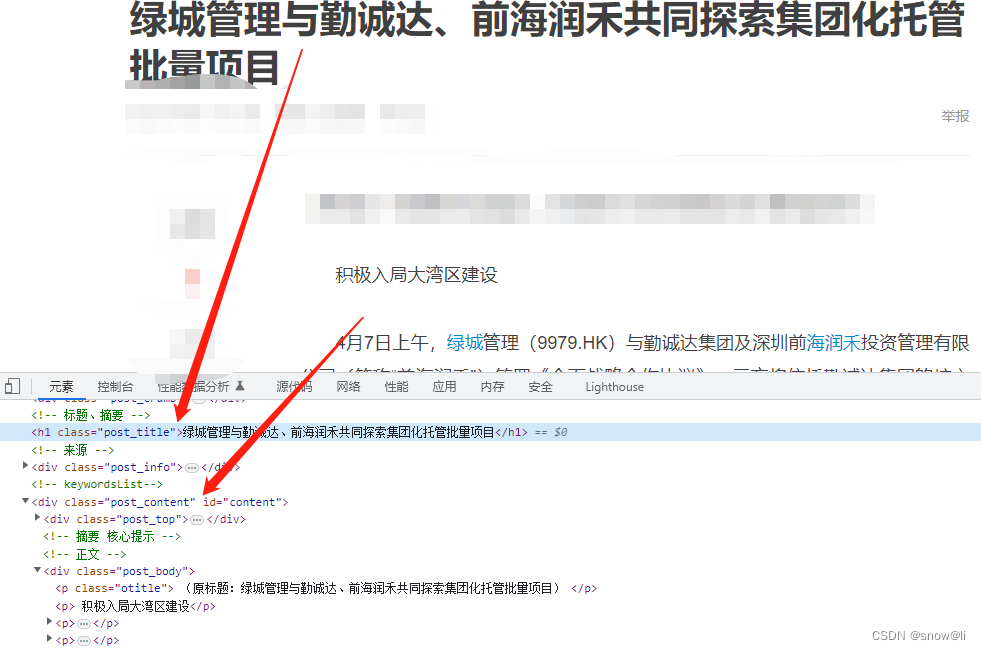
三、实践node爬虫
3.1、创建目录spider
创建目录spider,pnpm init创建package.json
3.2、安装依赖
npm i axios
npm i cheerio3.3、代码
const cheerio = require('cheerio')
const axios = require('axios')
const url = require('url')
const fs = require('fs')
const request = axios.create({
baseURL: 'https://money.163.com/' // 网易财经商讯
})
// 获取最后一页的页码数
const getLastPage = async () => {
const { data } = await request({
method: 'GET',
url: '/special/businessnews/', // 新闻列表首页
})
const $ = cheerio.load(data)
const paginations = $('.index_pages a') // 分页区域
const lastPageHref = paginations.eq(paginations.length - 2).attr('href')
return Number(lastPageHref.split("/")[4].split("_")[1])
}
// 需求:获取 网易财经商讯网站 所有的文章列表(文章标题、文章内容)并且将该数据存储到数据库中
// 获取所有文章列表
const getArticles = async () => {
const lastPage = await getLastPage()
console.log('28', lastPage)
const links = []
for (let page = 1; page <= lastPage; page++) {
let url = "special/businessnews/"
if(page > 1 && page <= 9){
url = `special/businessnews_0${page}/`
} else if(page > 9){
url = `special/businessnews_${page}/`
}
const { data } = await request({
method: 'GET',
url: url,
})
const $ = cheerio.load(data)
$('.index_list a').each((index, element) => {
const item = $(element) // 转换为 $ 元素
links.push(item.attr('href'))
})
// 每次抓取完一页的数据就等待一段时间,太快容易被发现
await new Promise(resolve => {
setTimeout(resolve, 1000)
})
console.log("links.length", links.length)
}
return links
}
// 获取文章内容
const getArticleContent = async (url) => {
const { data } = await request({
method: 'GET',
url
})
const $ = cheerio.load(data)
const title = $('.post_title').text().trim()
const content = $('.post_body').html()
return {
title,
content
}
}
const main = async () => {
// 1. 获取所有文章列表链接
const articles = await getArticles()
// 2. 遍历文章列表
for (let i = 0; i < articles.length; i++) {
const link = articles[i]
const article = await getArticleContent(link)
// 生产环境可以存到数据库里边了
fs.appendFileSync('./db.txt', `
标题:${article.title}
文章内容:${article.content}
\r\n\r\n\r\n\r\n
`)
console.log(`${link} 抓取完成`)
await wait(500)
}
}
main()
function wait (time) {
return new Promise(resolve => {
setTimeout(() => {
resolve()
}, time)
})
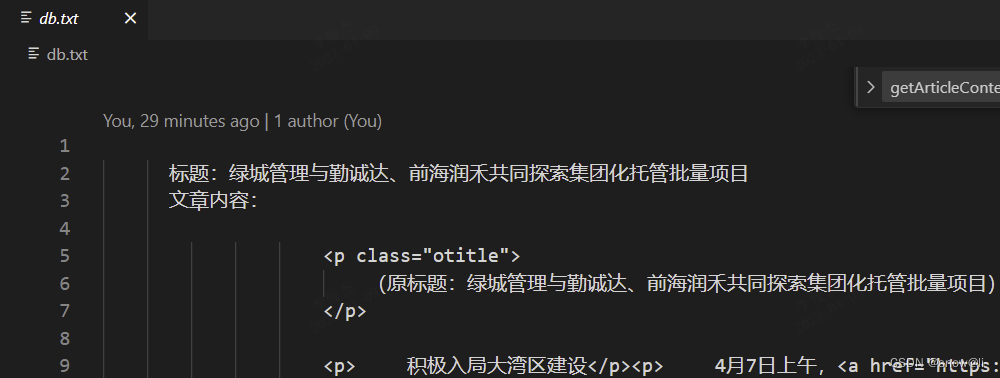
}3.4、执行爬虫
执行node spider.js,数据抓取到db.txt文件,成功。
四、爬虫配置文件
本文仅实现了一个网站列表的抓取,代码全部在一个文件内实现。如果是要抓取多个文件可以把每个网站的结构写在一个json文件内,爬虫读取每个网站的配置文件,从而提高效率。同时可以把开发爬虫和写爬虫配置的工作分开交由不同的人员实现,提高爬虫开发过程的整体效率。
// 配置文件
{
url: "",
list: [],
pagination: {
max: 20,
},
article: {
title: "",
author: "",
time: "",
content: ""
}
...
}五、欢迎交流指正,关注我,一起学习。
参考链接: