对于清洗来说,没有绝对万能的通用模板,你会遇到各种问题,只能写好多种不同的版本根据不同的情况选择合适的程序来调用,比如初步清洗,二次清洗
一.索引删除及基本统计运算
import pandas as pd
import numpy as np创建一个四行四列数字从0~15的二维数组,并把它转换成dataframe,列索引变成A B C D
df = pd.DataFrame(np.arange(0, 16).reshape(4, 4), columns=['A', 'B', 'C', 'D'])
print(df)A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
对指定索引删除一行或一列
# 删除一行
print(df.drop(0, axis=0))
# 删除一列
print(df.drop('A', axis=1))A B C D
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
B C D
0 1 2 3
1 5 6 7
2 9 10 11
3 13 14 15
# 求每一行的平均值
print(df.mean(axis=1))
# 每一列的平均值
print(df.mean(axis=0))
# 求每一行的和
print(df.sum(axis=1))0 1.5
1 5.5
2 9.5
3 13.5
dtype: float64
A 6.0
B 7.0
C 8.0
D 9.0
dtype: float64
0 6
1 22
2 38
3 54
dtype: int64
# 新增一行,行索引为4,计算每一列的和
df.loc[4] = df.sum(axis=0)
print(df)
# 新增一列,列名叫sum_values,计算每一行的和
df['sum_values'] = df.sum(axis=1)
print(df)A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 24 28 32 36
A B C D sum_values
0 0 1 2 3 6
1 4 5 6 7 22
2 8 9 10 11 38
3 12 13 14 15 54
4 24 28 32 36 120
二.pandas读取表中数据,对空值检测及处理
删除空值: dropna(axis , how ,inplace)
填充空值:fillna(value, method, axis, inplace)
axis:删除的是行还是列 index / 0 行 column / 1 列
how: 怎么删 any:任何空值都会被删掉 all:所有值为空才会删
inplace: True/False 是/否修改当前对象
method: ffill 向前填充 bfill 向后填充
value : 用于填充的值:可以是单个值,也可是字典
示范:
使用Excal创建表格如下
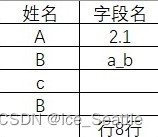
1.读取数据,检测空值
df = pd.read_excel('./old.xlsx') # skiprows=lambda x: x in [0, 0]
# 数据信息
print(df.info())
print("检测空值:\n", df.isnull())
print("检测单列空值:", df['字段名'].isnull)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 姓名 4 non-null object
1 字段名 3 non-null object
dtypes: object(2)
memory usage: 208.0+ bytes
None
检测空值:
姓名 字段名
0 False False
1 False False
2 False True
3 False True
4 True False
检测单列空值: <bound method Series.isnull of 0 2.1
1 a_b
2 NaN
3 NaN
4 行8行
# 删除所有空的行
df.dropna(axis=0, how='all', inplace=True)
# 删除所有空的列
df.dropna(axis=1, how='all', inplace=True)2.填补空值
# 3.填补空值
df.fillna({'姓名': 'D'}, inplace=True)
df.fillna({'字段名': 0}, inplace=True)
df['字段名'] = df['字段名'].fillna(method='ffill')这里对姓名这列的空值填充了D,对字段名这列空值填充了0
inplace是否修改当前操作对象,True最后表输出的时候就会被更改,ffill为向前填充
3.判断指定字段数据中是否重复
# 检测姓名这一列是否有重复,是返回True,不是返回False
print(df.duplicated('字段名'))Name: 字段名, dtype: object>
0 False
1 False
2 False
3 True
4 False
dtype: bool
4.对重复数据删除
# 删除有姓名重复的这一行
print(df.drop_duplicates('姓名'))姓名 字段名
0 A 2.1
1 B a_b
2 c 0
4 NaN 行8行
三.对应数据的特殊处理
使用方法:
1.先获取series的str属性,然后在属性上调用函数
2.只能在字符串列使用,不能在数字列中使用
3.dataframe没有字符串属性
4.series.str不是python中的字符串方法,而是一个属性,和python中的str是两码事
5.expend series>>dataframe
df['字段名'] = df['字段名'].astype('str')
df['字段名'] = df['字段名'].str.replace('.', '', regex=True)
df['姓名'] = df['姓名'].str.upper()
df['字段名'] = df['字段名'].str.split('_', expand=True)[0] # [][]列索引,行索引
df['字段名'] = df['字段名'].str.replace('行', '')
df['字段名'][1] = ord(df.loc[1]['字段名']) # loc查询[][]为行索引,列索引
# 类型转换,将str转换为int否则不能计算
df['字段名'] = df['字段名'].astype('int64')如上代码,
第一条使用astype()将数据类型转换为str字符串格式
第二条为去掉old表中数据2.1原有的小数点,此时要使用df[''].str某一列的值,即series.str,并使用字符串函数的replace()将小数点替换为空,指定正则regex=True,否则出现警告
FutureWarning: The default value of regex will change from True to False in a future version. In addition, single character regular expressions will *not* be treated as literal strings when regex=True.
df['字段名'] = df['字段名'].str.replace('.', '')
第三条,由于old表中c为小写,我们统一将姓名这一栏的数据全为大写,使用字符串函数的upper()
第四条,old表中出现a_b数据,我们想要留下a则,使用split()以'_'进行分割,取第一个个元素,即[0]
第五条,去除old表中 行8行数据的行,留下数字类型
第六条,将查询dataframe数据中位置[1]['字段名']的数据,以ord()函数转换为十进制数字的形式赋给df,要注意查询loc对应的[][]是先行索引,后列索引,而数据赋值的时候相反
第七条,将df['字段名']这一列的所有数据转换为int型,在处理时均为字符串类型,转换为int以便于接下来的运算
处理完如下
姓名 字段名
0 A 21
1 B 97
2 C 0
3 B 0
4 D 8
四.计算单个数据值
print("平均值 meandf:", df['字段名'].mean())
print("最大 max:", df['字段名'].max())
print("最小值 min:", df['字段名'].min())
print("中位数 median:", df['字段名'].median())
print("按值计数 value_counts:", df['字段名'].value_counts(0))平均值 meandf: 25.2
最大 max: 97
最小值 min: 0
中位数 median: 8.0
按值计数 value_counts: 0 221 1
97 1
8 1
五.数据排序
1.通过series排序
ascending属性为False时为降序排序
# 通过字段名升序排序
print(df['字段名'].sort_values(ascending=True))Name: 字段名, dtype: int64
2 0
3 0
4 8
0 21
1 97
2.dataframe单列排序
print(df.sort_values(by='字段名', ascending=True))Name: 字段名, dtype: int64
姓名 字段名
2 C 0
3 B 0
4 D 8
0 A 21
1 B 97
3.dataframe多列排序
print(df.sort_values(by=['姓名', '字段名'], ascending=[True, True]))姓名 字段名
0 A 21
3 B 0
1 B 97
2 C 0
4 D 8
保存数据
df.to_excel('./new.xlsx', index=False)查看新数据

数据清洗重点是综合运用,使用python的主要目的就是简化清洗过程,根据不同的时候选择不同的工具进行不同层次的清洗
六.完整代码
# _*_ coding:utf-8 _*_
# @Time : 2022/9/12 19:06
# @Author : ice_Seattle
# @File : 数据清洗.py
# @Software: PyCharm
import pandas as pd
# 导入 excel
df = pd.read_excel('./old.xlsx') # skiprows=lambda x: x in [0, 0]
# skiprows:跳过多少行
# 数据信息
print(df.info())
print("检测空值:\n", df.isnull())
print("检测单列空值:", df['字段名'].isnull)
# 删除空值
# 删除所有空的行
df.dropna(axis=0, how='all', inplace=True)
# 删除所有空的列
df.dropna(axis=1, how='all', inplace=True)
# 3.填补空值
df.fillna({'姓名': 'D'}, inplace=True)
df.fillna({'字段名': 0}, inplace=True)
df['字段名'] = df['字段名'].fillna(method='ffill')
# 检测姓名这一列是否有重复,是返回True,不是返回False
print(df.duplicated('字段名'))
# 删除有姓名重复的这一行
print(df.drop_duplicates('姓名'))
df['字段名'] = df['字段名'].astype('str')
df['字段名'] = df['字段名'].str.replace('.', '', regex=True)
df['姓名'] = df['姓名'].str.upper()
df['字段名'] = df['字段名'].str.split('_', expand=True)[0] # [][]列索引,行索引
df['字段名'] = df['字段名'].str.replace('行', '')
df['字段名'][1] = ord(df.loc[1]['字段名']) # loc查询[][]为行索引,列索引
# 类型转换,将str转换为int否则不能计算
df['字段名'] = df['字段名'].astype('int64')
print(df)
# 计算单个数据值
print("平均值 meandf:", df['字段名'].mean())
print("最大 max:", df['字段名'].max())
print("最小值 min:", df['字段名'].min())
print("中位数 median:", df['字段名'].median())
print("按值计数 value_counts:", df['字段名'].value_counts(0))
# 通过series排序
# 通过字段名升序排序
print(df['字段名'].sort_values(ascending=True))
# 2.dataframe 单列排序
print(df.sort_values(by='字段名', ascending=True))
# dataframe多列排序
print(df.sort_values(by=['姓名', '字段名'], ascending=[True, True]))
# 保存数据
df.to_excel('./new.xlsx', index=False)对于还会遇到什么问题的数据欢迎大家来评论区下留言,我们一起探讨