原创文章,转载请说明来自《老饼讲解神经网络》:bp.bbbdata.com
目录
本文是笔者细扒matlab神经网络工具箱newlvq的源码后,去除冗余代码,重现的简版newlvq代码,代码与newlvq的结果完全一致。通过本代码的学习,可以完全细节的了解LVQ的实现逻辑。
- 代码的逻辑解说可参考《LVQ-重现matlab实现代码》
- LVQ的原理可参考《LVQ神经网络基本原理》
一、代码结构说明
代码主要包含了三个函数:
testLvqNet: 测试用例主函数,直接运行时就是执行该函数。
- 1、数据:使用自带fisheriris数据,
- 2、用自写的函数训练一个LVQ网络,与预测结果。
- 3、使用工具箱训练一个LVQ网络。比较自写函数与工具箱训练结果是否一致(权重、训练误差的比较)
trainLvq:训练一个LVQ神经网络。
- 支持LVQ1规则与LVQ2规则
predict:用训练好的网络进行预测。
- 传入需要预测的X,与网络的权重矩阵,即可得到预测结果。
二、代码运行结果解说
1、自写LVQ预测错误的样本序号:

2、自写LVQ网络的权重结果:

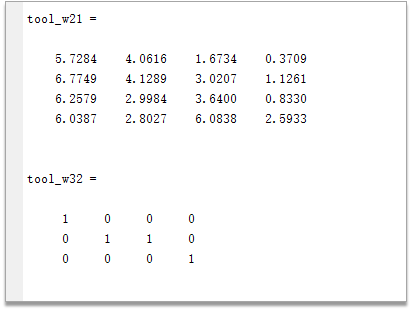
3、matlab神经网络工具箱训练得到的权重:
4、自写LVQ与matlab神经网络工具箱的权重差异:

可以看到,自写的代码与matlab2014b神经网络工具箱跑的LVQ结果完全一致,完美重现工具箱代码。
三、算法流程图

四、具体代码
matlab2014b亲测已跑通:
%调用demo
function testLvqNet()
% 数据加载与参数预设
% 加载数据
load fisheriris
X = meas';
[~,yc] = ismember(species,unique(species));
y = full(ind2vec(yc'));
%网络参数
hn_pc = [0.4,0.4,0.2]; % 各个输出的隐节点占比
hn = 4; % 隐节点个数
lr = 0.01; % 学习率
method = 'learnlv2'; % 学习方法
epochs = 100; % 训练最大步数
%---------调用自写函数进行训练--------------
rand('seed',70);
[w21,w32,e2,Erc] = trainLvq(X,y,hn,hn_pc,epochs,lr,method);
[~,predict_idx] = max(predict(X,w21,w32));
err_predict = find(predict_idx~= yc')
w21
w32
% -----调用工具箱,与工具箱的结果比较------
% 调用工具箱进行训练
rand('seed',70);
net = newlvq(X,hn,hn_pc,lr,method);
net.trainparam.epochs = epochs;
[net,tr] = train(net,X,y);
% 工具箱的结果
tool_w21=net.IW{1}
tool_w32=net.LW{2}
tool_Erc =tr.perf;
% 与工具箱的差异
maxECompareNet = max([max(abs(w21(:)-tool_w21(:))),...
max(abs(w32(:)-tool_w32(:))),max(abs(Erc(:)-tool_Erc(:)))])
% 网络与训练函数
function [w21,w32,e2,Erc]=trainLvq(X,y,hn,hn_pc,epochs,lr,method)
%----------参数设置与常量计算-----------------
wd = 0.25; % 窗口值,lvq2专用
goal = 0; % 目标误差
max_epochs = epochs; % 最大迭代次数
[in ,sn] = size(X); % 输入个数,样本个数
on = size(y,1); % 输出个数
% ---------网络权重初始化---------------
%初始化输入层到隐层权重w21,初始化规则:取每个输入的中心点
x_mid = (min(X,[],2)+max(X,[],2))/2; % 计算输入的中心点
w21 = repmat(x_mid',hn,1);
%初始化隐层到输出层权重:w32,初始化规则:将隐节点按比例hn_pc连接输出节点
indices = [0; floor(cumsum(hn_pc(:))*hn)]; % 计算比例所对应的隐节点编号
w32 = zeros(on,hn); % 初始化w32
for i=1:on
w32(i,(indices(i)+1):indices(i+1)) = 1; % 将隐节点与输出节点有连接的,置为1
end
% ---------网络权重训练---------------
[oa,ha] = predict(X,w21,w32); % 计算网络的输出
eo = (oa - y); % 计算网络的输出与各个真实样本的误差
e2 = sum(eo(:).^2)/length(eo(:)); % 计算当前总误差(均方差)
Erc = [e2]; % 初始化误差记录矩阵
% 记录最好的结果
best.e2 = e2;
best.w21 = w21;
best.w32 = w32;
best.epoch = 0;
web('bp.bbbdata.com')
% 迭代训练网络权重
for i = 1: max_epochs
% 将所有样本随机顺序逐个训练网络
for k = 1:sn
j = fix(rand*sn)+1;
cur_x = X(:,j) ; % 当前样本
[oa,ha,hv] = predict(cur_x,w21,w32); % 计算当前样本的预测值
out_correct = (oa == y(:,j)); % 更新样本预测误差
% 更新w21
dw21 = zeros(size(w21));
if (method=='learnlv1')
win_idx = find(ha);
if all(out_correct) % 如果分类正确,往样本方向移动
dw21(win_idx,: ) =dw21(win_idx,: )+lr*(cur_x'-w21(win_idx,:));
else % 如果分类错误,往样本反方向移动
dw21(win_idx,: ) =dw21(win_idx,: ) - lr*(cur_x'-w21(win_idx,:));
end
elseif(method=='learnlv2')
%找出第一第二大的值,即离x最近的两个隐节点的编号
hv_tmp = hv;
[~,k1] = max(hv_tmp);
hv_tmp(k1)=-inf;
[~,k2] = max(hv_tmp);
hide_correct =w32'*out_correct; % 隐节点是否正确(隐节点正确与否和所连接的输出正确与否一致)
if(hide_correct(k1)==hide_correct(k2)) % 两个节点都正确或都错误
d1 = abs(hv(k1)); % 最近节点的距离
d2 = abs(hv(k2)); % 最远节点的距离
if (d1/d2 > ((1-wd)/(1+wd))) %如果样本离两个中心都比较近,调整中心,拉开距离
if hide_correct(k1) == 1 %如果两个节点都正确,则拉开距离,使近者更近,远者更远
dw21(k1,:) = dw21(k1,:) + lr*(cur_x'-w21(k1,:));
dw21(k2,:) = dw21(k2,:) - lr*(cur_x'-w21(k2,:));
else% 如果两者都错误,尝试使第二中心更靠近。
dw21(k1,:) = dw21(k1,:) - lr*(cur_x'-w21(k1,:));
dw21(k2,:) = dw21(k2,:) + lr*(cur_x'-w21(k2,:));
end
end
end
end
w21 = w21+dw21;
end
[oa,ha] = predict(X,w21,w32); % 计算网络的输出
e2 = sum(sum((oa - y).^2))/length(oa(:)); % 计算当前总误差(均方差)
Erc = [Erc,e2]; % 记录当前总误差
if(e2<best.e2)
best.e2=e2;
best.w21 = w21;
best.w32 = w32;
best.epoch=0;
end
if(e2 <= goal) break; end % 如果误差达到目标,退出训练
end
%返回历史最佳结果
e2 = best.e2;
w21 = best.w21;
w32 = best.w32 ;
% 预测,输出oa(输出层的激活值,即y);ha(隐层的激活值),hv(隐层的值,即与x的距离)
function [oa,ha,hv] = predict(X,w21,w32)
sn = size(X,2);%样本个数
hn = size(w21,1);%隐节点个数
%计算输出
%隐节点值
hv = zeros(hn,sn);
for i =1:hn
cur_w = w21(i,:)'*ones(1,sn); % 第i个隐节点,输入-隐层权重,展成样本列
hv(i,:) = -sum((cur_w-X).^ 2) .^ 0.5; % -sqrt(sum((权重-输入)^2) 即-输入与权重的欧氏距离
end
%隐节点激活值
ha= zeros(hn,sn);
[~,idx] = max(hv);
ha(sub2ind(size(ha),idx,1:sn)) =1;
oa = w32*ha;热爱学习的同学快关注老饼的公众号吧!-公众号名:老饼讲解BP神经网络。
相关文章