一、优化器模块
torch.optim是一个具备各种优化算法的库,可以支持大部分常用的优化方法,并且这个接口具备足够的通用性,这使得它能够集成更加复杂的优化算法
1:optimizer的使用
构建一个optimizer对象
参数设置(需要优化的参数、设置学习率等)
![]()
另外,还可以单独设置每个参数值

表示model.base的参数都将使用0.001的学习率,model.regression的参数将使用0.0001的学习率
2:常见优化器简介
梯度下降法
批量梯度下降(batch gradient descent)
针对整个数据集,通过对所有样本的计算来求解梯度的方向;梯度方差小;需要较多计算资源,会导致训练过程很慢;BGD 不能够在线训练,也就是不能根据新数据来实时更新模型

∇L(θ)=1/N∑_n=1^N▒∇L(f(X^(n);θ),y^(n))
随机梯度下降(stochastic gradient descent)
当训练数据N很大时,通过计算总的损失函数来求梯度代价很大,所以一个常用的方法是每次随机选取一个样本的损失函数来求梯度,这就是随机梯度下降的方法(SGD)。虽然采用这种方法,训练速度快,但准确度也因此下降,梯度方差会变大,损失的震荡会比较严重;同时由于鞍点的存在可能导致局部梯度为零,无法继续移动,使得最优解可能仅为局部最优

小批量梯度下降(mini-batch gradient descent)
为了在提高训练速度的同时,保持梯度方差大小合适,以便于寻找全局最优解,提出了小批量梯度下降法:即把数据分为若干个批,按批量来更新参数,这样子,一个批量中的数据可以共同决定梯度的方向,下降时也不易跑偏,减少了梯度下降的随机性,也减少了计算量。该方法选择一个合适的学习率比较困难;且梯度容易被困在鞍点

动量优化算法(Momentum)
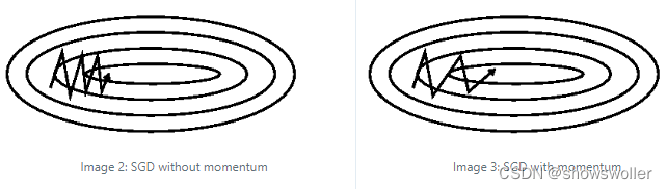
动量优化算法是一种有效缓解梯度估计随机的算法,通过使用最近一段时间内的平均梯度来代替当前时刻的随机梯度作为参数更新的方向,从而提高优化速度。使用该算法可实现惯性保持,主要思想是引入一个积攒历史梯度信息动量来加速SGD。 采用相关物理知识解释,沿山体滚下的铁球,向下的力总是不变,产生动量不断积累,速度也自然越来越快;同时左右的弹力不断切换,动量积累的结果是相互抵消,也就减弱了球的来回震荡。这样就说明了采用了动量的随机梯度下降法为何可以有效缓解梯度下降方差,提高优化速度。虽然使用该方法不能保证收敛到全局最优,但能够使得梯度越过山谷和鞍点,跳出局部最优。 由于动量优化算法是基于SGD算法所提出的,因此在PyTorch中的实现通过设置SGD函数的相关参数即可,具体实现可以由先前SGD函数讲解可知
逐参数适应学习率方法(Per-parameter adaptive learning rate methods)
AdaGrad
AdaGrad是一种逐参数自适应学习率的优化算法,可以为不同的变量提供自适应的学习率。该算法的基本思想是对每个变量采用不同的学习率,这个学习率在一开始比较大,用于快速梯度下降;随着优化过程进行,对于已经下降很多的变量,减缓学习率;对于还没怎么下降的变量,则保持较大的学习率。但其中的一个缺点是:在深度学习中单调的学习率被证明通常过于激进且过早停止学习

RMSProp
RMSProp(Root Mean Squre propogation,即均方根(反向)传播)是AdaGrad算法的一种改进。与AdaGrad算法不同的是累计平方梯度的求法不同:该算法不像AdaGrad算法那样直接累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少,即做了一个梯度平方的滑动平均

Adam
Adam算法即自适应时刻估计方法(Adaptive Moment Estimation),相当于自适应学习率(RMSProp)和动量法(Momentum )的相结合,能够计算每个参数的自适应学习率,将惯性保持和环境感知这两个优点集于一身。Adam 使用梯度的指数加权平均(一阶矩估计)和梯度平方的指数加权平均(二阶矩估计)来动态地调整每个参数的学习率
代码实现如下
![]()
二、训练和测试模块
我们在使用PyTorch框架搭建神经网络时总会看见在模型的训练前会加上model.train(),而在模型测试或者验证之前会加上model.eval(),那么这两者之间有什么区别呢
model.train()和model.eval()的主要区别
在使用PyTorch搭建神经网络时,model.train()主要用于训练阶段,model.eval()则用于验证和测试阶段,两者的主要区别是对于Dropout和Batch Normlization层的影响。在model.train模式下,Dropout网络层会按照设定参数p设置保留激活单元的概率(保留概率=p);Batchnorm层会继续计算数据的均值mean和方差var等参数并更新。相反,在model.eval()模式下,Dropout层的设定参数会无效,所有的激活单元都可以通过该层,同时Batchnorm层会停止计算均值和方差,直接使用在训练阶段已经学习好的均值和方差值运行模型
模型训练、测试框架
首先,需要将神经网络的运行模式设定为训练模式,只需要通过model.train()就可以将运行模式设置为训练模式
for epoch in range(0,epochs):
model.train()接着使用for循环遍历每个batch进行训练,注意enumerate返回值有两个,一个是batch的序号,一个是数据(包含训练数据和标签)。在开始训练以前,首先要梯度清零,通过optimizer.zero_grad()实现,其作用是清除所有优化的torch.Tensor(权重、偏差等)的梯度

在梯度清零以后就可以输入数据计算结果以及损失,接着需要对损失进行反向传播,即loss.backward()。具体来说,损失函数loss是由模型的所有权重w经过一系列运算得到的,若某个权重的requires_grads为True,则该权重的所有上层参数(后面层的权重)的.grad_fn属性中就保存了对应的运算,在使用loss.backward()后,会一层层的反向传播计算每个权重的梯度值,并保存到该权重的.grad属性中
在经过反向传播计算得到每个权重的梯度值以后,需要通过step()函数执行一次优化步骤,通过梯度下降法来更新参数的值,也就是说每迭代一次,通过optimizer.step()进行一次单次优化
 测试框架
测试框架
首先,需要将神经网络的运行模式设定为测试模式,只需要通过model.eval()就可以将运行模式设置为测试模式。其作用是保证每个参数都固定,确保每个min-batch的均值和方差都不变,尤其是针对包含Dropout和BatchNormalization的网络,更需要调整网络的模式,避免参数更新
同时为了确保参数的梯度不进行变化,需要通过with torch.no_grad()模块改变测试状态,在该模块下,所有计算得出的tensor的requires_grad都自动设置为False,不会对模型的权重和偏差求导

由于是测试模式,只需要输入数据得到输出以及损失即可,不需要对模型参数进行更新。因此此处也少了反向传播loss.backward()以及单次优化optimizer.step()的步骤。至于其他的步骤,与训练模块相似
 创作不易 觉得有帮助请点赞关注收藏~~~
创作不易 觉得有帮助请点赞关注收藏~~~