点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:桃子 好困
【导读】ICML 2023终于放榜了!今年共有1827篇论文被接收,录用率27.9%。网友纷纷晒出了自己成绩单。
ICML 2023放榜啦!
就在刚刚,ICML公布了今年录取情况,共有6538份论文提交,1827篇论文被接收,录用率27.9%。
从网友的统计中可以看到,2023年总论文提交量,以及论文接收量创历史新高,同时接收率也是近年来之最。
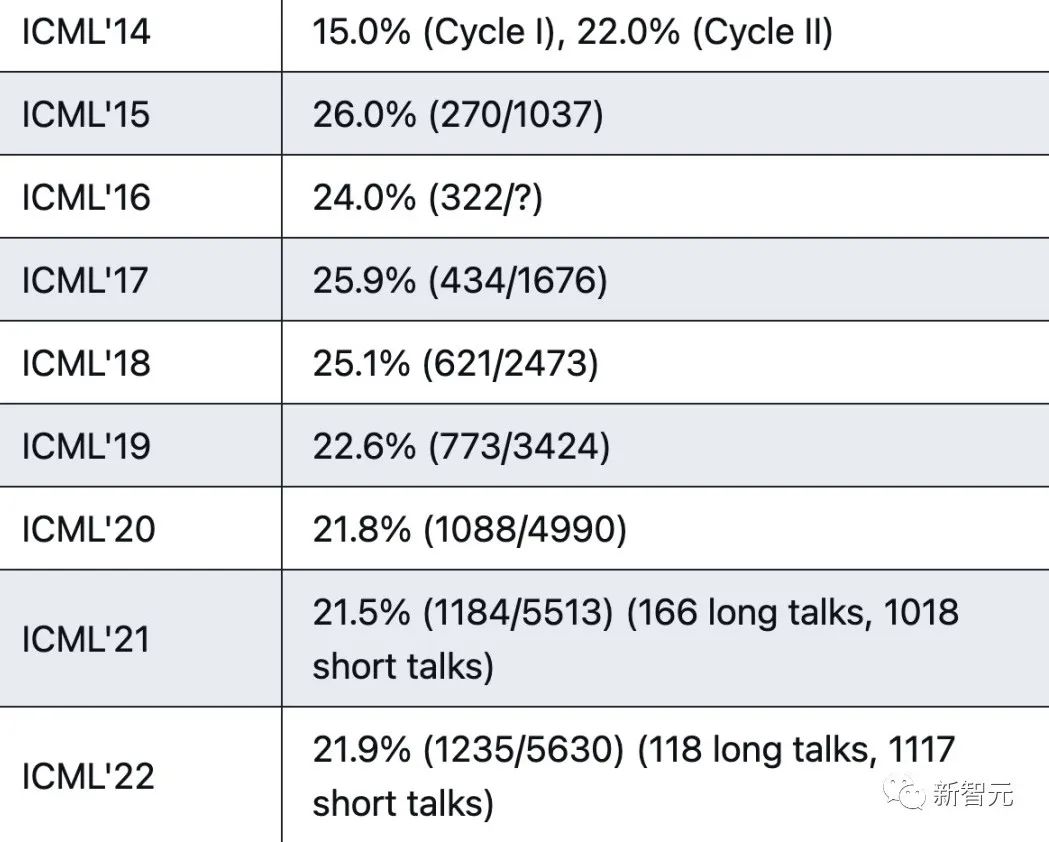
过去的一年,是生成式AI爆发的一年,各种生成模型、大型语言模型不断涌现,今年在ICML 2023提交的论文主题也与此紧密相关。
值得一提的是,第40届机器学习顶会ICML 2023将在7月23-29在夏威夷召开。

许多童鞋在得知中奖后,纷纷晒出自己的成绩单,准备去夏威夷冲浪。
网友晒中奖
来自港中文的余备教授在朋友圈中分享道,自己中了人生第一篇ICML,感谢徐鹏同学带飞。
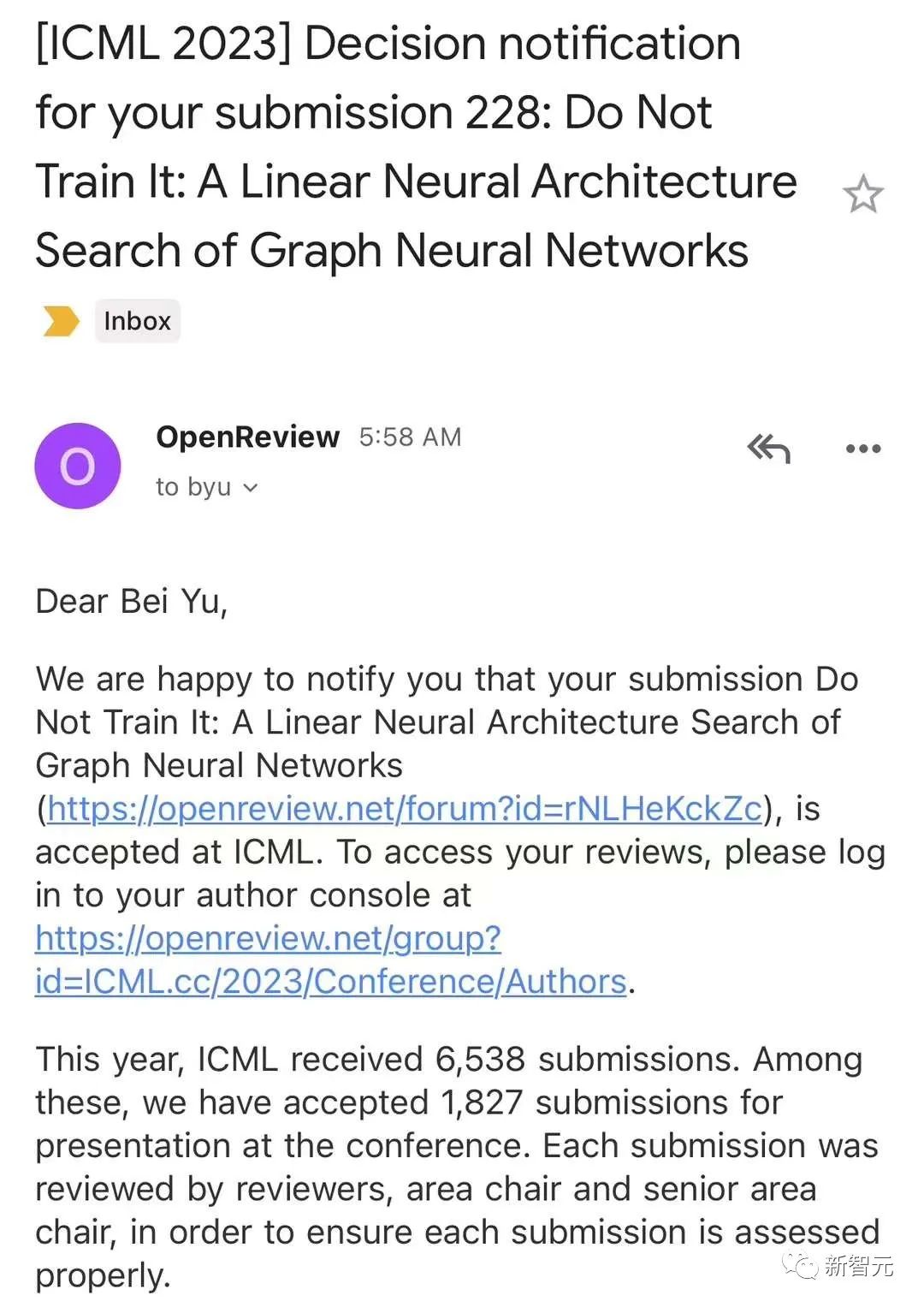
而麻省理工EECS的副教授韩松还是在健身房举铁的时候,得知自己中奖了。
「在gym里和同学们举铁的时候听说SmoothQuant中了ICML!一年的努力终于有了结果,七月夏威夷见了。」
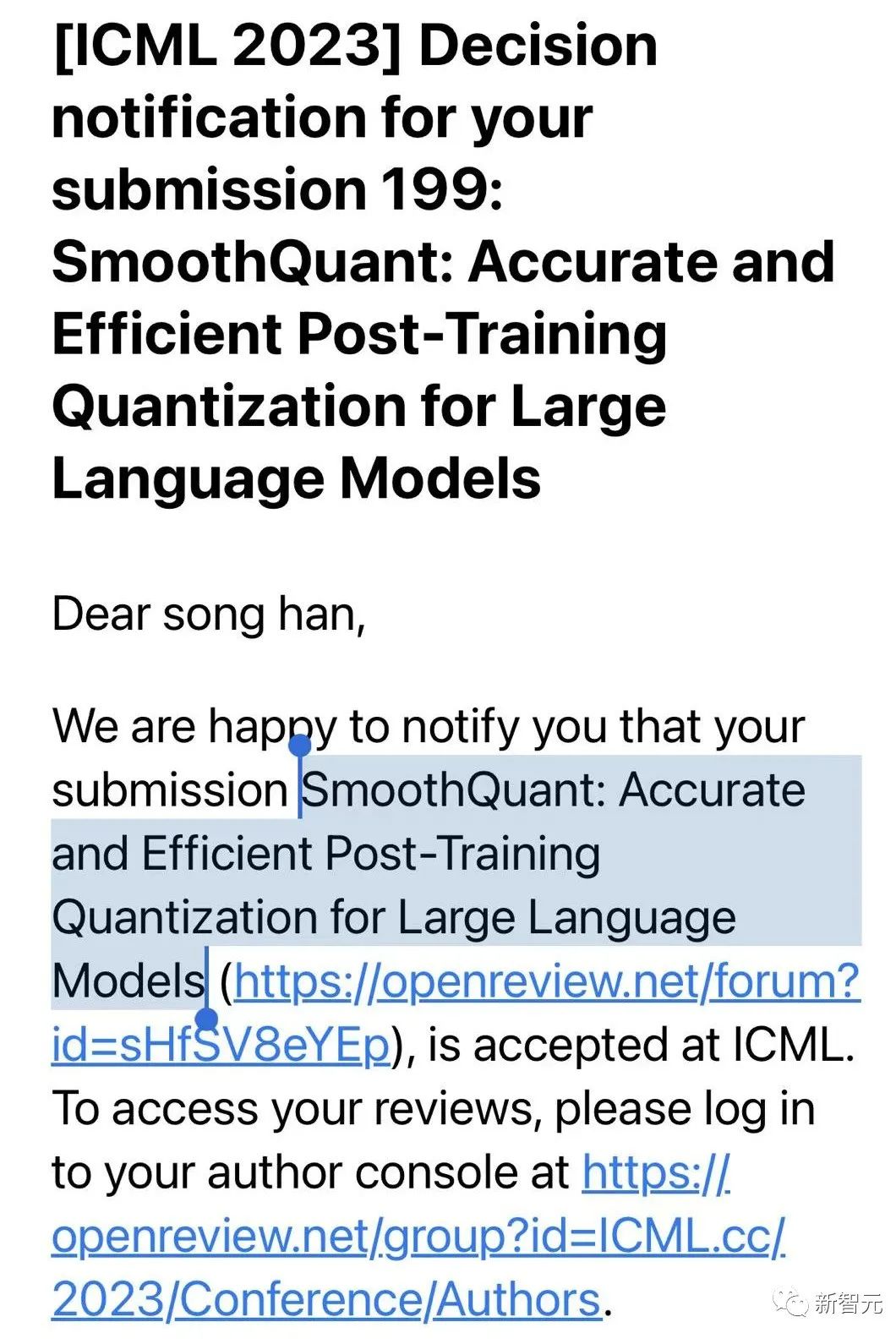
此外,北大张铭发文庆祝校友罗霄博士领衔的论文被ICML接收。

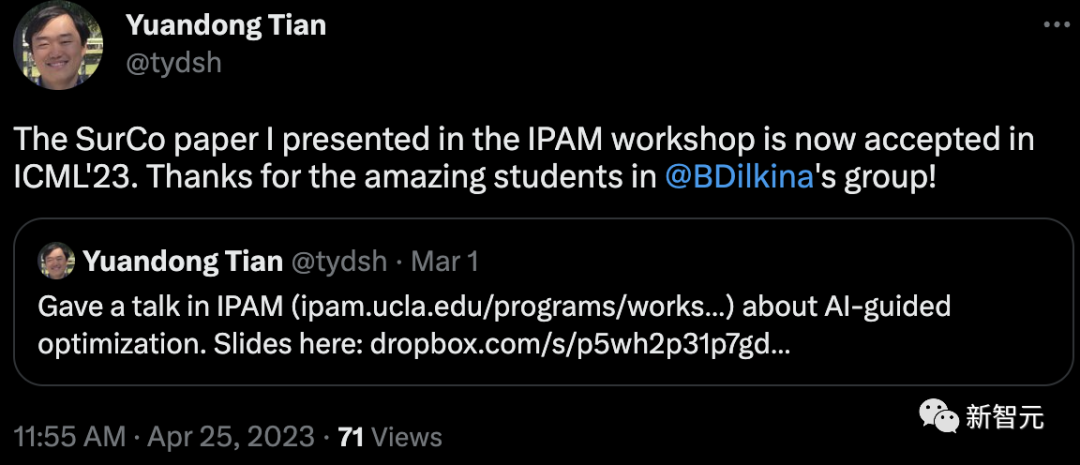
Meta AI的田渊栋表示,自己参与的5篇ICML论文中,有4篇被接收了。
其中一篇还是Oral,是关于通过上下文稀疏性加速LLM推理的。另外3篇则是关于AI引导优化的。
至于被拒的那篇论文,审稿人也喜欢其中的最佳方案,但认为不适合ICML。

他还称,其中一篇还是自己3月份在IPAM workshop上展示的SurCo的论文。
生成模型领域部分中奖论文
加州大学圣巴巴拉分校(UCSB)计算机系的Kexun Zhangt提出的扩散采样框架ReDi的论文被ICML接收。
其中,论文的共同作者还有UCSB助理教授李磊。2021年,曾是字节跳动人工智能实验室总监的李磊,选择离职重返学术界时,引起了不小的反响。

这篇论文就当前扩散模型推理速度慢的问题提出了新的框架。尽管扩散模型生成质量高,但需要大量采样迭代,导致模型推理耗时。
最新提出的ReDi是一个基于检索的扩散采样框架,能够将模型推理速度提升2倍。

论文地址:https://arxiv.org/abs/2302.02285
此外,曾获北大图灵班学士学位,现MIT博士二年级的学生Yilun Xu提出的PFGM++被ICML 2023接收。
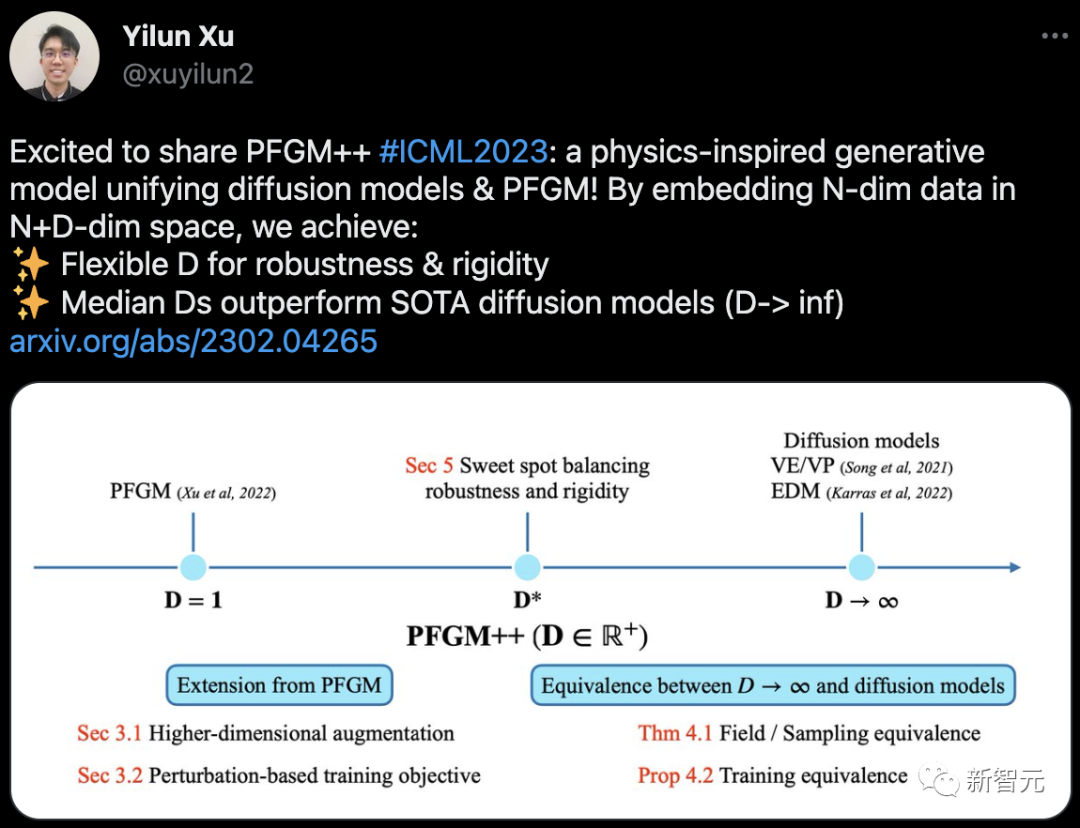
这篇论文提出了一个受物理学启发的生成模型,也就是PFGM++。它统一了扩散模型和「泊松流」生成模型(PFGM)。
通过将N-dim数据嵌入N+D-dim空间,实现了:灵活的D,具有鲁棒性和刚性;中位数D的表现优于SOTA扩散模型(D-> inf)。

论文地址:https://arxiv.org/abs/2302.04265
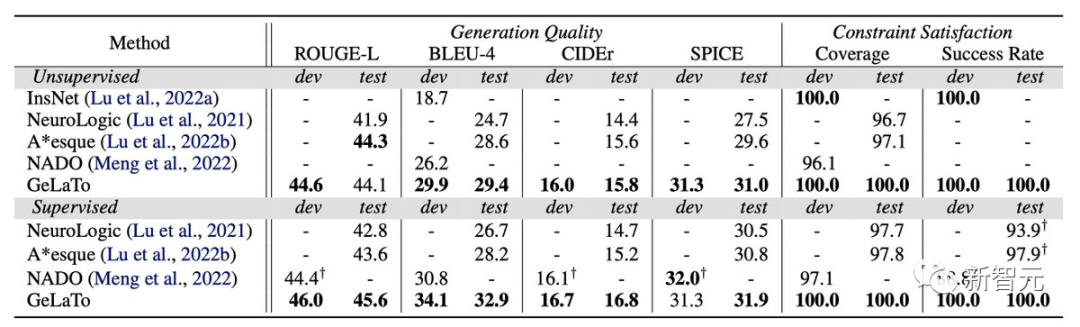
来自UCLA StarAI实验室的张宏华就大型语言模型的可靠控制问题,提出了GeLaTo(易处理约束的生成语言)。
这是一个神经符号框架,允许LLMs以100%保证生成遵循逻辑/词汇约束的文本。

在GeLaTo中,作者首先在从LM采样的数据上训练一个可操作的概率模型(TPM),以近似其分布,然后用TPM计算 p (next-token | prefix, constraints),以指导LM自回归生成。
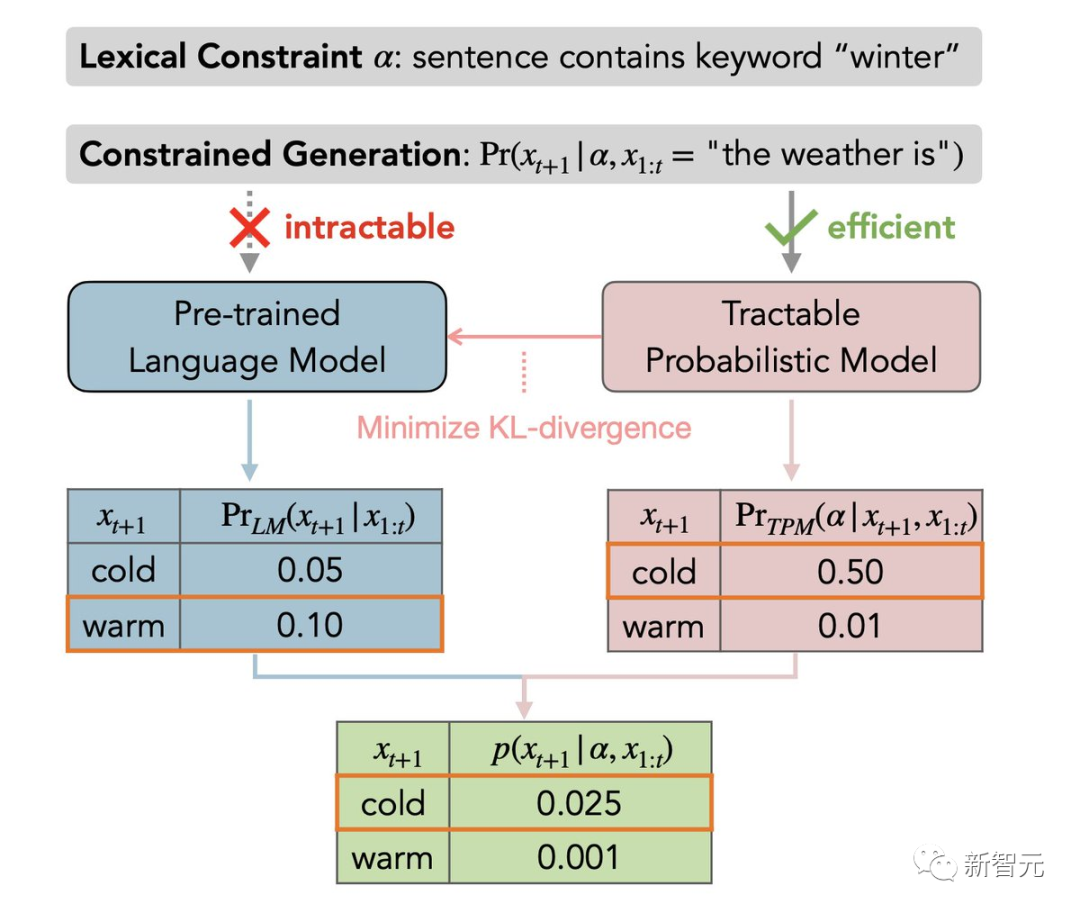
作者者在CommonGen基准上评估了GeLaTo,其目标是使用一些给定的关键词生成文本。
GeLaTo不仅达到了SoTA的生成质量(如BLEU分数),而且还保证了所有的关键词都被使用,战胜了各种强大基线。
Oral论文
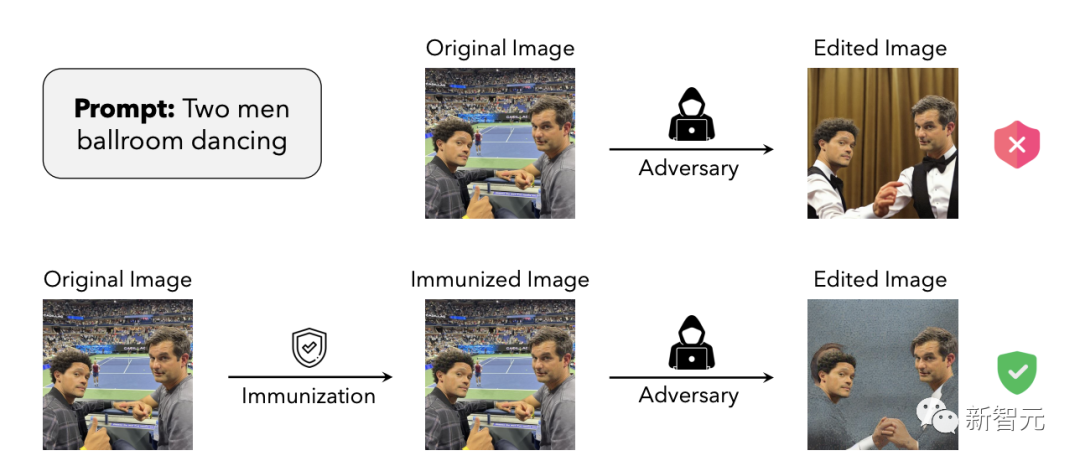
MIT团队的Oral论文提出了一种减轻大型扩散模型所带来的恶意图像编辑风险的方法——图像免疫(image immunization)。


项目地址:http://gradientscience.org/photoguard/
比如,原始图像可以经过DELL-E2、还有Stable Diffusion等方法恶搞让两个人跳舞,在原始照片上添加小的(不易察觉的)噪音,可以对这样的恶搞做了一个「保护层」。
由港大、UC伯克利和天大合著的AdaptDiffuser,也入选了今年ICML的Oral论文。
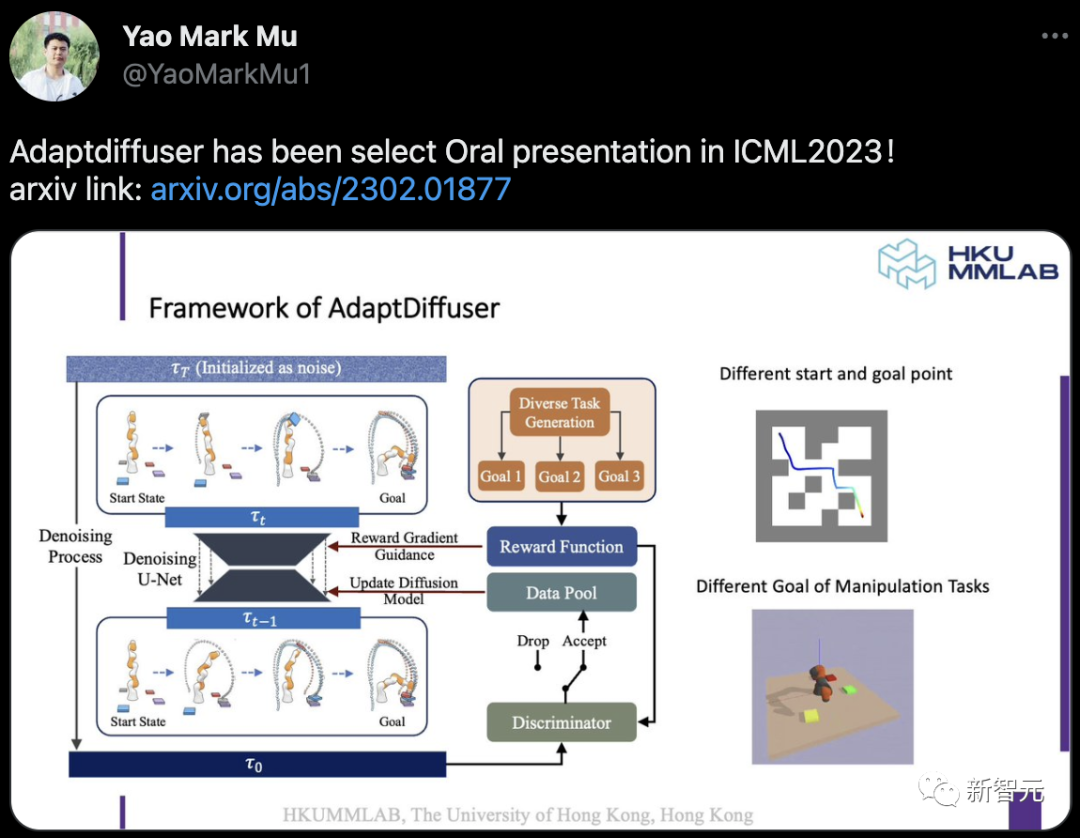
其中,研究人员提出一种名为AdaptDiffuser的进化规划方法,它可以通过自我演化来改进扩散模型,进而更好地进行规划。AdaptDiffuser不仅适用于已知的任务,而且也可以适应没见过新任务。
相比于前一代模型,AdaptDiffuser不仅在Maze2D和MuJoCo运动上,分别提升了20.8%和7.5%的性能,而且在不需要额外专家数据的情况下,能够更好地适应了新任务,例如在KUKA拾取和放置中提高了27.9%。

论文地址:https://arxiv.org/abs/2302.01877
在知乎上,有一位还在读本科的知友称这还是自己本科的第一篇中奖了。
网友「daddyitsme」投了两篇都中奖了,有一篇还是oral。

网友「球球夜神」也投了两篇,但只有一篇被接收了。

网友「Jiapeng Zhang」对ICLM审稿质量提出了批评。他表示,本来抱着去夏威夷旅游的心态投稿ICML,但是在rebuttal后,感觉审稿人和AC基本上没有看。

我审自己
的确,投稿量的激增,审稿人水平的下滑,审稿时间的减少,审稿人利益冲突,审稿报酬低下……这一系列问题造成了如今糟糕的同行评议质量。
有人戏称说现在的审稿在某种意义上甚至不如随机审稿,说得也不无道理。

那么,在同行评议仍无法避免的今天,有什么办法挽救这一正危及整个科学界的现状呢?
为了进一步改善审稿质量问题,在2021年,来自宾夕法尼亚大学的苏炜杰教授提出了一种让投稿人自己「审稿」的方法,该论文已发表在NeurIPS 2021中。
值得一提的是,该方法并不是真的让投稿人去审稿自己的论文,而是让投稿人提供一个对自己投稿文章的质量排序,并使用保序回归(Isotonic Regression)帮助审稿人提高审稿质量。

论文地址:https://arxiv.org/abs/2110.14802
自提出以来,该方法便受到了学界的广泛关注。而在今年的ICML 2023会议上,更是被应用到了实验之中。
随后,在今年四月,来自普林斯顿的Yuling Yan、Jianqing Fan以及宾大的苏炜杰教授,进一步将保序机制(Isotonic Mechanism)拓展到了更为广泛的指数分布族的情况。
在审稿分数遵循大部分指数分布族的情况下,投稿人通过汇报真实排序可以提高自身效用函数以及大幅提高审稿精度,这一延拓使得将作者排序与审稿分数结合的机制更加契合实际场景。

论文地址:https://arxiv.org/abs/2304.11160
为什么作者的信息可以被利用?
对于一位审稿人来说,他在一次会议中可能被要求在短短十几天内审稿十余篇互不相关的文章,如果缺乏相关背景知识,这无疑是一项巨大的挑战。
相对于审稿人,作者对于自己的文章的了解度肯定是更高的。如果有一种方案可以让作者告诉审稿人自己对于自己的文章的真实看法,这些有效的信息无疑会给审稿过程提供一个另一维度的帮助。
保序机制(Isotonic Mechanism)
假设投稿人投出了n篇论文,其真实分数为R1, R2, …, Rn,假设投稿人知道这些真实分数的排序(数学上表示为1, 2, …, n的置换)。
那么,机制要求投稿人汇报自己对这n篇论文打分的排序π,再结合审稿人给出的原始平均分数y1, y2, …, yn,解一个凸问题并给出最终分数。
形式上,这个凸优化问题为:
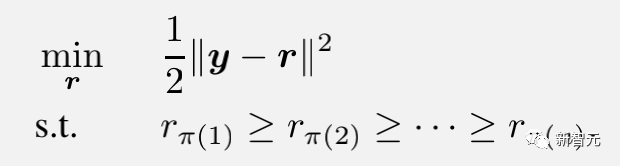
另外,该机制还假设投稿人是理性的。即投稿人汇报排序π的最终目的是让自己的利益最大化。数学上,表现为投稿人希望机制得出的最终分数可以最大化如下效用函数:
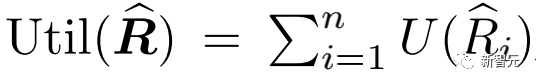
这里假设U是一个不减凸函数。
保序机制的理论保证
我们先将对假设的介绍和对合理性的讨论稍稍后放,以便于突出文章的主要结果,也就是保序机制相对于原始分数在理论上的优越性:

1. 投稿人的最佳策略是如实报告他/她的论文原始分数的真实排序;甚至在投稿人不能完全确定所有真实分数排序时,报告所知道的所有真实信息也是其最优选择。

2. 机制所提供的调整后的最终分数确实严格地比审稿人提供的原始分数要准确。
仅仅是汇报分数的排序,就会提高准确度,其实用性不言而喻。不仅如此,文章作者还进一步对更一般的情况做了推广,文章对投稿人只知道真实分数的分块排序、机制的稳健性(鲁棒性)、效用函数不能表示成n个论文各自效用之和的三种情况进行拓展讨论,充分的展示了保序机制强大的校正功能,以及丰富的现实意义。
到这里,我们再回头看一下假设。除了对函数U的要求,还要求投稿人自己对真实信息必须有一定的了解(这样才能进行协助),以及审稿人打分相对真实分数的噪声在置换下的分布是不变的(可交换性)。这些假设也都是比较实际的。
需要格外注意函数U是凸的假设,对以上结论的成立是至关重要的。这里效用衡量的不是「量」的大小,而是决定了论文是否会被作为海报、口头报告,甚至是全会报告的分数。对很多研究者,追求会议论文更大的影响力反映了他们真实的需求,因此效用函数的凸性有其合理性。
最后,如果该实验取得了成功,它将成为学术会议同行评议制度的一个里程碑,并为审稿制度开拓了作者评审这一全新的维度。
对于如何让作者的意见与价值观加入审稿过程,比如是否有除了排序以外其他的形式,未来也会有更多的可能性值得被探索。
参考资料:
https://www.zhihu.com/question/597314456
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()