《流浪地球2》中,我们看到了永生数字人丫丫,她不仅有丫丫本人的形象、记忆,还有与其本人一致的意识、性格。随着元宇宙的持续火爆,数字人技术近年来也取得了非常大的进步,但是目前的技术离电影中展现的数字人丫丫有多远呢?接下来我们将从数字人的感知、认知、意识、性格,以及孪生数字人的复刻、表达等方面简单介绍下当前的技术进展、面临的技术瓶颈以及未来的技术展望。
孪生数字人复刻、表达技术
孪生数字人的复刻一般指将现实中的人物形象以2D或者3D的形式复制并展现出来,而表达则是指数字人可以进行各种肢体动作和脸部动作等。其中,基于2D的孪生数字人复刻可以通过拍照或者录视频的方式简单完成,然而让2D数字人完成指定动作则需要优秀的生成算法模型来实现,目前流行的Talking Face任务研究已经可以通过语音驱动生成口型与语音对齐的嘴形动作,但如何生成高清且精准的2D肢体动作仍然面临很大挑战。另一方面,比较流行的生成技术如GAN、NeRF、Diffusion Model等,虽然可以完成基本的生成任务,但如何自然流畅地生成带有各种表情的数字人,研究上虽取得了一些进展,要想将这些技术应用在实际产品落地中,仍然面临生成视频不够高清、表情不够自然、动作不够丰富等问题。

△ 图片来自论文【1】
比如,最近比较流行的风格迁移式数字人合成的研究,可以通过输入一段音频、一个风格参考视频和一个人物照片,合成具有参考风格且音频嘴形对齐的视频。接下来,我们以论文StyleTalk【1】为例深入介绍此算法结构。
算法整体结构:
首先从风格参考视频中提取序列化的3DMM表情系数,然后将表情系数送入到风格编码器中获取风格码。同时采用音频编码器将音素标签转化为音频特征。然后用文章中设计的风格控制动态解码器生成带有风格和音频特征的风格表情系数,最后将风格表情系数和个人参考图像输入到图像渲染模型,完成带有参考视频风格且符合输入音频的个人视频驱动。
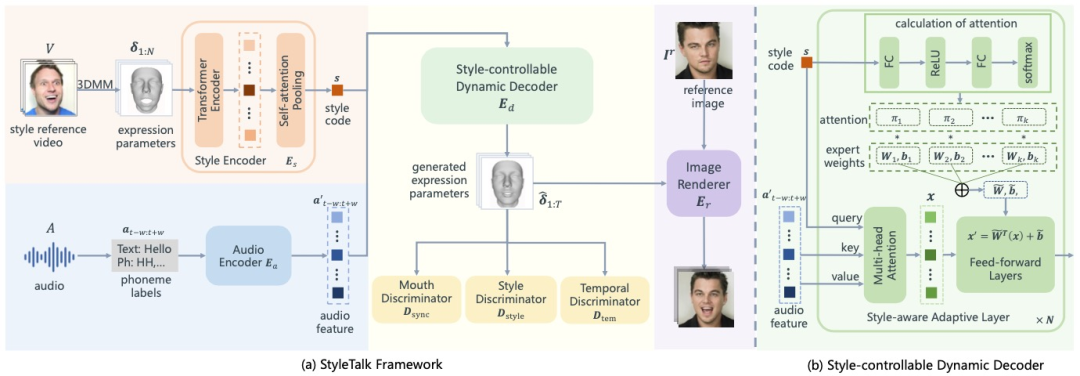
△ 图片来自论文【1】
上下半脸解耦:考虑到上半脸和下半脸有不同的动作模式。上半脸(眼睛、眼球)以低频率移动,而下半脸(嘴)以高频率移动。因此,此论文中将表情系数分成上半脸组和下半脸组,采用两个并列的风格控制动态解码器来进行训练。其中从64个表情系数中选出13个与嘴形动作高度相关的系数作为下半脸组,其余系数作为上半脸组。之后将生成的两组表情系数拼接起来获取最终的表情系数。
目标函数设计:文章中为了学习优秀的模型,采用了嘴形对齐判别器、时序判别器、风格判别器和一个三元组约束函数。
-
嘴形对齐判别器:文章中采用余弦相似性来表示嘴形映射(em )与音频映射(ea )的对齐度,

然后通过计算生成视频切片的每一帧的同步损失来最大化同步概率,

-
风格判别器:与PatchGAN结构类似,通过一个风格损失来指导模型生成生动的说话风格,

-
时序判别器:是为了学习区分输入3DMM 【2】 表情系数序列的真实性,同样参考PatchGAN 【3】 结构,采用了GAN 铰链损失Ltem 。
-
三元组约束:给定一个带有说话风格的视频切片,随机采样两个切片,其中一个切片风格与之相同,另一个切片风格与之不同。分别提取三个切片的风格码Sc ,Snc 和Spc ,则采用三元组损失来约束它们在风格空间中的距离,

最后,整体模型的损失函数融合了上述四个损失以及生成损失函数(L1损失)。
基于3D的孪生数字人本身就存在数字人复刻和数字人表达两个任务。目前就如何根据真实人物形象复刻3D数字人已经有很多研究,一些研究可以采用摄像技术围绕真人拍摄一圈,通过视频来复刻出3D虚拟人物,还有一些研究则依赖有多个摄像头的专业拍摄影棚,通过拍摄多个角度的照片来合成3D形象等等。虽然现有技术可以复刻出基本的3D人物形象,但与真人相比,仍然有很大差距。尤其在衣服、皮肤等细节上的复刻,还没有达到非常精细的程度。与2D表达相比,3D的表达更容易实现些,其主要原因是2D表达基本依赖于生成技术,而3D表达则更依赖于驱动技术。生成技术容易出现帧序列违和、失真、模糊、变形等问题,而3D驱动则可以根据人脸关键点以及肢体关键点完成指定的动作和表情,尤其动捕技术可以实时精准地驱动人脸表情和肢体动作。即便如此,如何摆脱人的控制,自动地驱动3D人物中各个关键点作出准确的动作,依然是热门的研究方向。
数字人的认知、意识及个性化
人的认知、意识本身就是非常复杂且未能完全解开的谜题,让数字人能够认知、具有意识,甚至有自己的性格是很多研究的主攻方向。并且,此类工作更多的是与脑科学相关联,使其研究更为复杂且更具挑战。当数字人具有某些意识或者个性化之后,通过何种形式表现出来,也是更加交叉综合的研究课题,比如以什么样的语言形式、什么样的语音语调、什么样的面部表情和肢体动作、各种表现形式融合到一起如何协调匹配等等。这些问题的存在,一方面促进了相关单个学科或领域的快速发展迭代,另一方面也对交叉学科、交叉领域的融合提出了更高要求和挑战。
在意识智能方面,目前已经开始有一些理论研究进展。比如,图灵奖获得者Manuel Blum教授于2022年提出了一种关于意识的形式化理论计算机模型—意识图灵机 (Conscious Turing Machine)【4】。意识图灵机旨在建立意识的数学模型,帮助我们理解意识的产生机制,并最终实现有意识的 AI。意识图灵机的思想起源于认知神经科学家Bernard Baars的全局工作空间理论 (Global Workspace Theory,GWT)。该理论假设意识与我们大脑中一个全局的“广播系统”相关联,这个系统会在整个大脑中广播资讯。在大脑处理各种输入信息时,一般情况下大脑中的各种专属信息处理器(视觉处理器、听觉处理器、触觉处理器等)会对信息进行自动处理,这个时候我们的大脑不会产生意识。但当大脑面对新的或者异常刺激信息时,各种专属信息处理器会透过合作或竞争方式,在全局工作空间中对新异刺激进行“聚焦式”分析处理,而意识正是在这个过程中得以产生。全局工作空间理论可以形象地用“剧院比喻”来解释,我们可以将意识比喻为戏剧演员在聚光灯下表演,他们的表演是在一群坐在黑暗中的观众(或者说是无意识处理器)的观察下进行的。在Blum的意识图灵机中,全局工作空间的舞台以短时记忆存储器为代表,观众则由处理器(processor)代表,每个处理器都有自己的专业知识,这些处理器组成了意识图灵机的长时记忆存储器。这些长时存储器和处理器对信息进行自动处理与预测,并从意识图灵机的世界获得反馈。每个处理器内部的学习算法会基于这个反馈改进处理器的行为。同时,每个处理器之间会相互竞争,竞争胜利者在舞台上以组块(chunk)的形式接收并处理信息,然后将处理结果通过广播机制传播出去。在意识图灵机模型中,正是长时记忆处理器对有意识信息接收的这个过程使得我们的大脑产生意识知觉(Conscious awareness)。
总的来说,意识图灵机包含一个从意识到无意识的树型结构:根节点上是短时记忆的意识处理器,子节点上是大量的长时记忆无意识处理器。短时记忆就像全局工作空间模型中的舞台,在舞台上的短时记忆信息就是意识中的信息。

左图:全局工作空间理论框架,右图:意识图灵机框架
作为首个意识的数学模型,意识图灵机有助于我们理解意识的产生机制,也为我们设计出真正具有意识的AI提供了一个理论方向。然而,就现有技术发展来看,要让数字人具有类似丫丫的认知、意识和个性化表达,仍然还有许多路要走。
总结
《流浪地球2》中的丫丫是数字人技术研究方向的具象化表现,虽然目前的技术在数字人复刻、表达、认知、意识及个性化方面都存在各种挑战。但我们依然相信,随着AI技术的快速迭代,会有越来越智能的数字人产品呈现在大家面前。
关于华院计算
华院计算技术(上海)股份有限公司(简称“华院计算”),成立于2002年,以算法研究和创新应用为核心、专注于认知智能技术的研究、应用和开发。公司基于数学应用与计算技术发展,聚焦认知智能技术、创新自研底层算法;基于认知智能引擎平台的场景应用,为数字治理、智能制造、数字文旅、零售金融 等行业提供AI+行业解决方案、实现全面赋能,从而推动行业智能化的转型和升级,让世界更智慧。
参考:
[1] Ma Y, Wang S, Hu Z, et al. StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles[J]. arXiv preprint arXiv:2301.01081, 2023.
[2] Blanz V, Vetter T. A morphable model for the synthesis of 3D faces[C]//Proceedings of the 26th annual conference on Computer graphics and interactive techniques. 1999: 187-194.
[3] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
[4] Blum, L., & Blum, M. (2022). A theory of consciousness from a theoretical computer science perspective: Insights from the Conscious Turing Machine. Proceedings of the National Academy of Sciences, 119(21), e2115934119.: 1125-1134.
作者:王晓梅 沈伟林