前言
openGauss是一款开源的关系型数据库,其内核源自postgresql,采用客户端/服务器、单进程多线程架构,支持单机和一主多备部署方式,备机只读,支持双机高可用和读扩展。

文章目录
引语
理性且客观的看,国产数据库和全球主流数据库存在些许差距,但国产数据库的发展环境已经不可同日而语,生态建设、人才发展、技术演进正在紧锣密鼓的向前“奔跑”,国产数据库与全球主流数据库的差距正在迅速缩小,所以,我们对国产数据库未来的发展应该有绝对的信心和自信,中国的数据库从业者应该积极地投入国产数据库的使用当中。
一、主备HA搭建
openGauss的架构与oracle和mysql的架构基本一致,没什么大的区别,配置也比较简单。
安装流程
- 单节点部署:在一个主机部署一个或多个数据库实例,支持极简安装和xml方式安装
- HA 部署:支持一台主机或者多台备机的配置方式,仅支持xml方式安装
官方文档关于部署流程的描述
开始→安装前准备→获取并校验安装包→配置XML文件→上传安装包和XML→解压安装包→初始化安装环境→执行安装→(可选)设置备机可读→结束
硬件环境要求
| 项目 | 配置描述 |
|---|---|
| CPU | 功能调试最小1×8 核 2.0GHz。 性能测试和商业部署时,单实例部署建议1×16核 2.0GHz。 CPU超线程和非超线程两种模式都支持。 目前,openGauss仅支持鲲鹏服务器和基于X86_64通用PC服务器的CPU。 |
| 内存 | 功能调试建议32GB以上。 性能测试和商业部署时,单实例部署建议128GB以上。 复杂的查询对内存的需求量比较高,在高并发场景下,可能出现内存不足。此时建议使用大内存的机器,或使用负载管理限制系统的并发。 |
| 硬盘 | 至少需要1GB(openGauss的应用程序) + 300M(元数据存储) 预留70%以上的磁盘剩余空间用于数据存储 建议系统盘配置为Raid1,数据盘配置为Raid5,且规划4组Raid5数据盘用于安装openGauss。 硬件层面,设置Disk Cache Policy为Disable,否则机器异常掉电后有数据丢失风险。 |
| 网络要求 | 300M以上以太网 建议网卡设置为双网卡冗余 |
软件环境要求
| 软件类型 | 配置描述 |
|---|---|
| Linux操作系统 | ARM: openEuler 20.03LTS(推荐采用此操作系统) 麒麟V10 x86: openEuler20.03LTS CentOS 7.6 说明:当前安装包只能在英文操作系统上安装使用。 |
| Linux文件系统 | 剩余inode个数 > 15亿(推荐) |
| 工具 | bzip2 |
| python | openEuler:支持Python 3.7.X CentOS:支持Python 3.6.X 麒麟:支持Python 3.7.X 说明:python需要通过–enable-shared方式编译。 |
实践操作
获取安装包
获取路径: 软件包 | openGauss
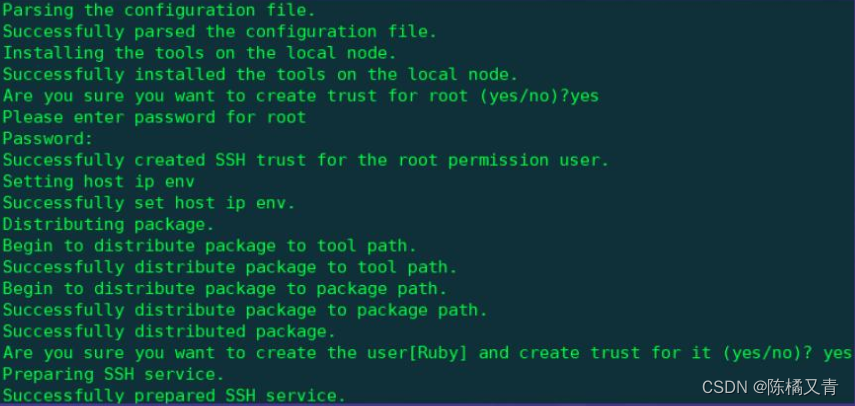
执行前置:
使用root用户执行gs_preinstall
gs_preinstall -U omm -G omm -X open_gauss_4node_casecade_cm.xml
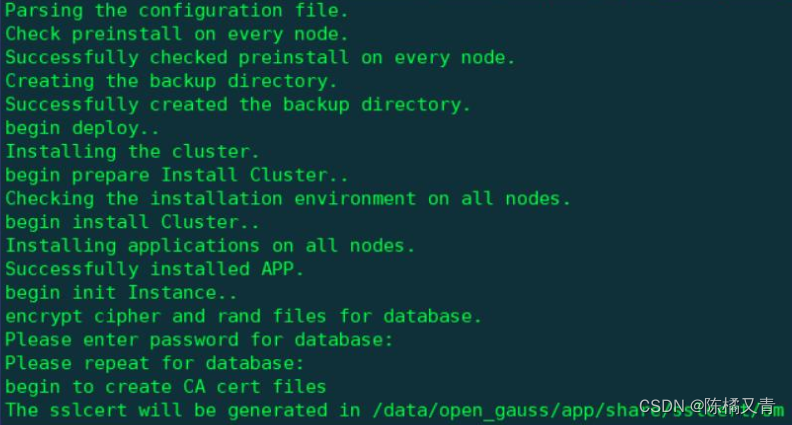
执行前安装:
使用omm用户执行安装
gs_install -X open_gauss_4node_casecade_cm.xml
二、主备HA日常操作
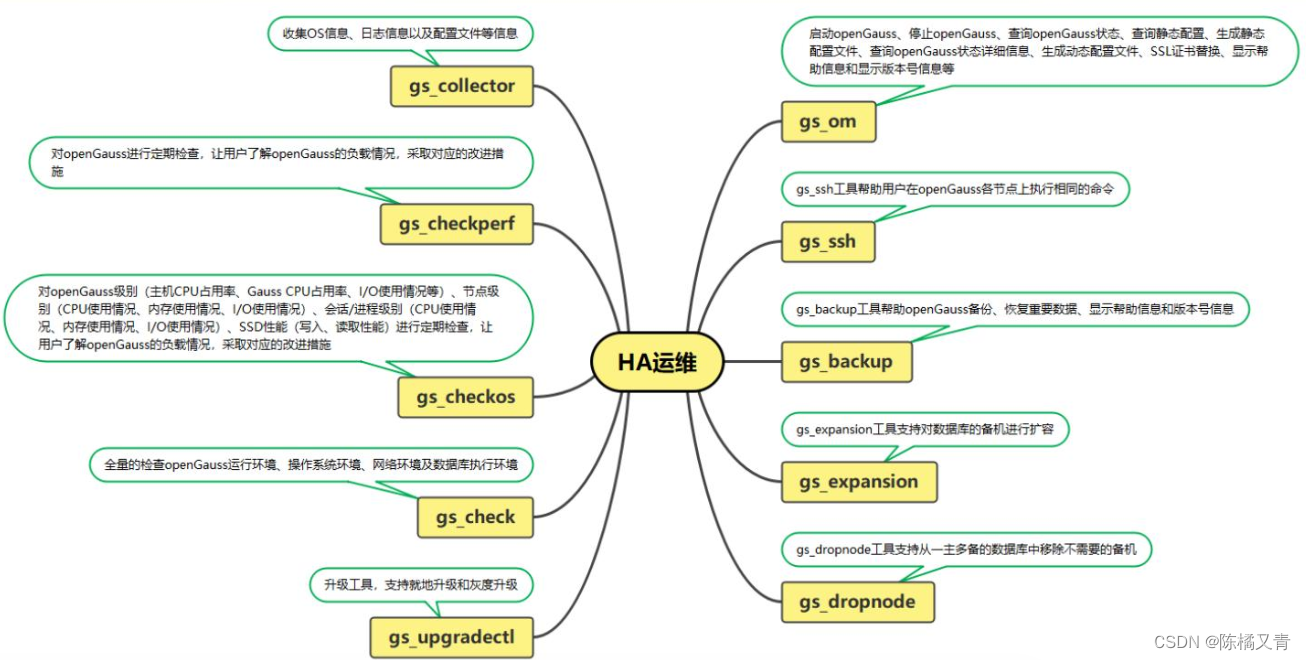
主备HA日常管理
常用的运维工具:gs_om、gs_expansion、gs_dropnode、gs_upgradectl
主备HA日常升级
用户在安装第一版数据库之后,若有新增的功能或业务逻辑,则为用户保证在保留原数据库拓扑及数据的情况下,为用户更新数据库。
| 升级方式 | 升级单位 | 原理 | 业务影响 | 适用场景 |
|---|---|---|---|---|
| 就地升级 | 集群 | 在升级过程中停止业务,更新系统对象,停集群切换二进制 | 升级全程断业务 | 对业务中断时间无要求的正常环境 |
| 灰度升级(一次性升级所有节点的灰度升级方式是目前最稳定可靠的) | 节点 | 对系统对象硬编码,在线更新系统对象(内核的),允许部分节点先升级(om) | 一次性升级全部节点,闪断时间为10s(版本的RTO时间)左右) | 对业务中断时间有要求且可一次性断掉所有业务的正常环境 |
三、主备HA技术拓展
openGauss是单机系统,支持一主多备,最多支持八个备机。
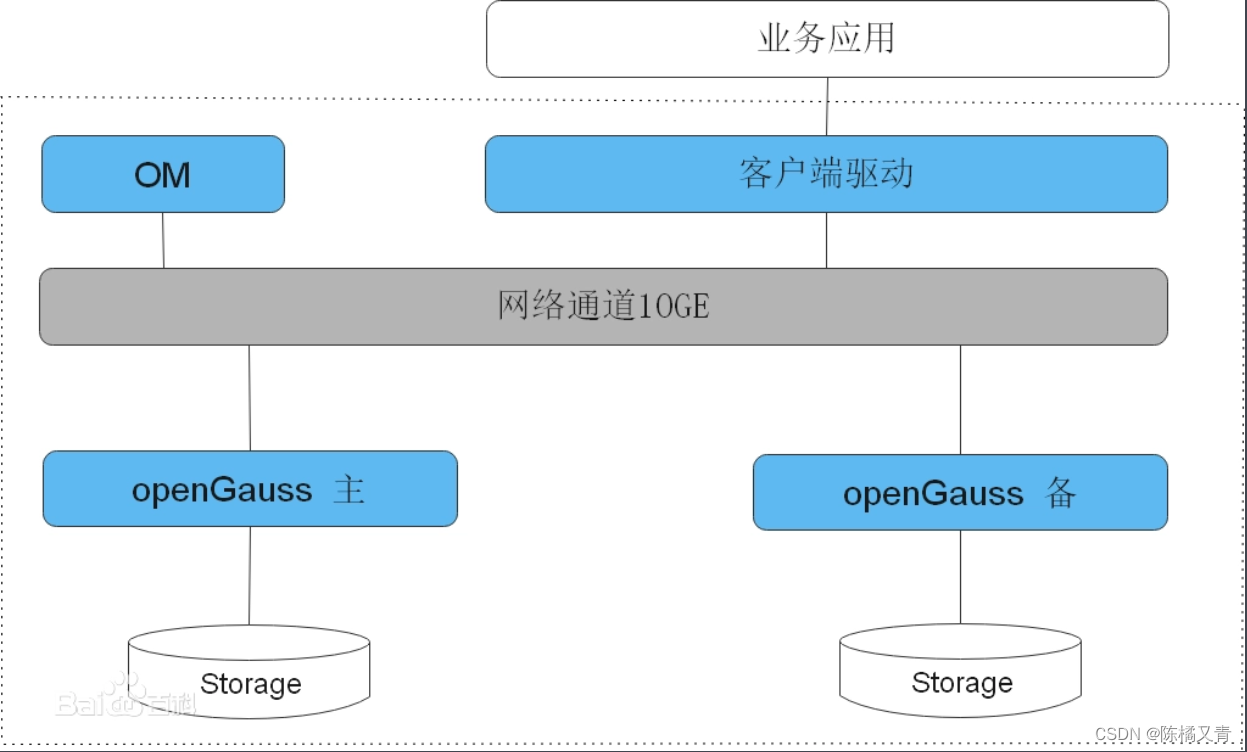
openGauss主备HA架构图

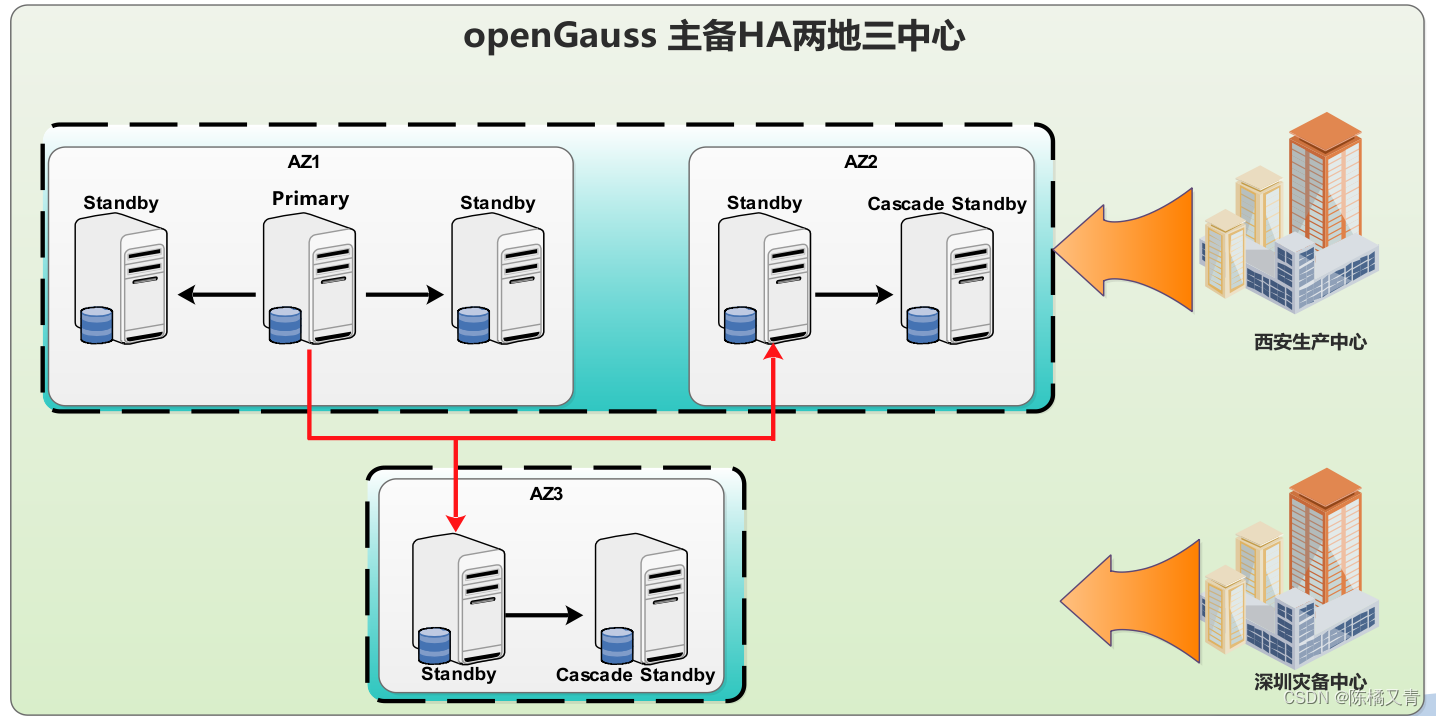
openGauss两地三中心部署
同步复制流程
on和local两种方式的事务提交时序图如下:
1、synchronous_commit = on(默认值)
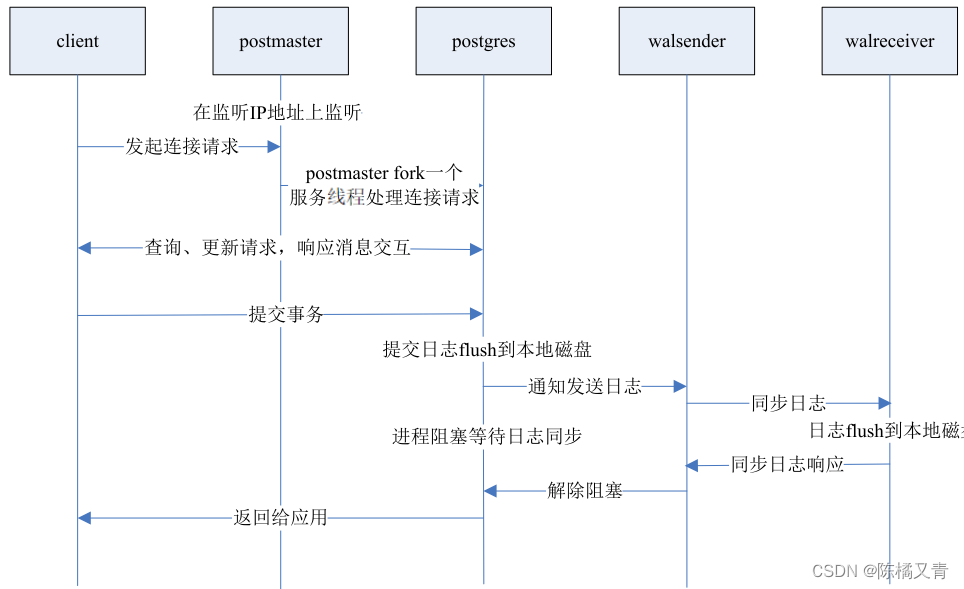
该方式有性能损耗,可靠性高。
2、synchronous_commit = local
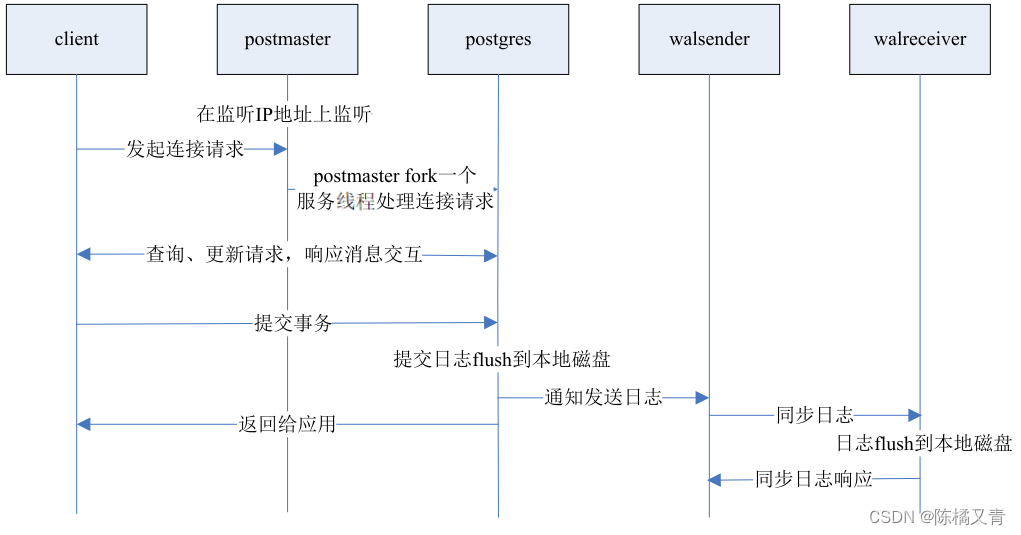
该方式性能高,可靠性差。
主备复制参数
replconninfo1 = 'localhost=192.168.0.1 localport=10001
localheartbeatport=12214 remotehost=192.168.0.2 remoteport=10002
remoteheartbeatport=10005’
remote_read_mode = authentication
replication_type = 1
most_available_sync = off
enable_stream_replication = on
synchronous_standby_names = 'ANY 1 (dn_6002,dn_6003)’
synchronous_commit = off
hot_standby = on
wal_receiver_timeout = 6s
wal_receiver_connect_timeout = 2s
wal_receiver_connect_retries = 1
hot_standby_feedback = off
recovery_min_apply_delay = 0
结语
对于数据库来说,稳定性压倒一切,其中包括核心功能,也包括用户生态和服务,所以国产数据库的稳定性验证周期还有待观察。同时数据库作为基础服务软件,过多的泛应用化会让数据库技术的基础沉淀不够扎实,而过度追求"ALL-IN-ONE"的设计理念,会让数据库技术难以聚焦,限制更大的发挥潜力。
目前国产数据库现在迎来了最好的发展机遇,我们已经看到了芯片,服务器、安全等领域都在这个机遇到来时显现出了勃勃生机。而在数据库领域,我们看到的只是一种表面的繁荣,并没有看到一种良性的发展趋势,希望这种局面很快会有所改观,希望国产数据库产业能够异军突起。
数据库作为一个非常重要的基础产业,不能完全受制于人。作为一个中国人,作为中国的数据库从业者,应该有这样的责任感,为国产数据库的产业发展,做出自己的贡献。
