
Title:DINOv2: Learning Robust Visual Features without Supervision
Paper:https://arxiv.org/pdf/2304.07193.pdf
Code:https://github.com/facebookresearch/dino
导读
在上一篇中,我们详细地为大家地介绍了 DINO,还没看的小伙伴赶紧跳转过去看下吧!传送门:https://mp.weixin.qq.com/s/EGCAX51FTyZrO7-e4y9Egg
时隔两年半,Meta AI 团队再度为大家奉上了 DINO 的进阶版——DINOv2!这篇文章主要是借鉴最近在自然语言处理方面的一些技术和进展,如语言模型的预训练,可以使计算机可以更好地理解语言。这些技术相当重要,因为它们为计算机视觉领域的类似技术提供了新的思路和方法。
作者认为,计算机视觉任务中也可以通过类似的方法来训练模型。这样的模型可以生成一些通用的视觉特征,也就是说,这些特征适用于不同的图像分布和不同的任务,无需进行进一步的微调即可使用。而最重要的是,我们仅需使用已有的自监督学习方法便能够生成这样的特征,当然前提是要有足够多的不同来源的数据进行训练。
本文主要介绍了一些技术上的创新,以充分挖掘自监督学习的潜力。其中,包括自动化数据管道用于获取更好的数据集,以及训练包含 10 亿个可调参数的 ViT 模型,并通过无监督蒸馏方法,将其压缩成一系列能够应用于不同任务的小模型。这些技术可以让计算机视觉领域变得更加高效、精准,并且更好理解。

上图计算来自同一列的图像块之间的 PCA 可视化结果,并显示它们的前 3 个组件,每个组件都匹配到不同的颜色通道。可以看出,尽管姿势、风格甚至物体发生变化,但相关图像之间的相同部分是匹配的。(这里背景主要是通过阈值处理来屏蔽掉的)
数据处理
本文的主要贡献之一便是创建了一个大规模的数据集——LVD-142M。同以往的人工采集、标注和清洗流程不同,此数据集是通过从大量未标注的数据中检索出与几个经过精心整理过的数据集中存在相似度很高的那部分样本所组成的。下面我们一起遵循以下图例看看这个pipeline是如何构建起来的。

数据源
首先,LVD-142M 数据集的来源共包含两部分,即公开数据集和网络数据集。
公开数据集

网络数据集
网络数据集简单理解就是通过爬虫将网页的图片download下来。相信这也是绝大部分算法工程师的日常工作,想必很多人都会遇到同样的问题,那便是直接扒下来的数据很“脏”!DINOv2 的做法是分三步清洗:
首先,针对每个感兴趣的网页,从标签中提取出图像的 URL 链接;
其次,排除掉具有安全问题或受限于域名的 URL 链接;
最后,对下载的图像进行后处理,包括 PCA 哈希去重、NSFW 过滤和模糊可识别的人脸;
整合起来,我们便生成了 1.2 亿张独一无二的图像。
去重
经过第一个步骤,我们将一些质量太差或者格式破损的图像给剔除掉,然而这当中必然会存在许多冗余图像。本文采用《A self-supervised descriptor for image copy detection》这篇论文提出的copy detection pipeline进行图像查重,同样是 Meta 的工作,发表于 CVPR 2022,本质上也是通过深度学习的方法计算相似度,有兴趣的同学可以自行尝试下。

经过上述操作,可以有效减少冗余并增加了图像之间的多样性。此外,作者还删除了这项工作中使用的任何基准的测试或验证集中包含的重复图像。
自监督图像检索
这一步便是我们上面提到的,从大量未标注的数据中检索出与几个经过精心整理过的数据集中存在相似度很高的那部分样本,下面我简单总结下。
首先,当我们要从一个大型的未筛选数据集中挑选图像来用于预训练时,我们需要先对这些图像进行聚类,以便在检索时能快速找到与查询图像相似的图像。聚类算法会对所有的未筛选图像进行分组,使得同一组内的图像在视觉上非常相似。
那么,为了聚类过程能够顺利进行,我们需要先计算每个图像的嵌入。一个嵌入是指将一个图像转换成一个向量,使得这个向量包含了这个图像的信息。本文使用了一个在 ImageNet-22k 上进行预训练过的 ViT-H/16 的自监督神经网络来计算每个图像的嵌入。
一旦我们计算出了每个图像的嵌入向量,我们就可以使用聚类算法来将这些向量分组。原文直接采用了 k-means 聚类算法,它会将嵌入向量相似的图像放到同一个聚类中。
紧接着,给定一个查询图像,我们从与查询图像所在的聚类中检索N(通常为4)个最相似的图像。如果查询图像所在的聚类太小,我们会从聚类中抽样M张图像(M是由视觉检查结果后决定的)。最后,我们将这些相似的图像和查询图像一起用于预训练,那么便能够获得一个更加优质、精心筛选过的大规模预训练数据集。
需要注意的是,在这里, “视觉检查” 是指通过人工检查了一些从聚类中检索到的图像,以确保它们与查询图像在视觉上的相似度。例如,如果我们发现从聚类中检索到的图像与查询图像相似度较高,那么我们就可以增加 N 的值,或者减少 M 的值。反之,如果从聚类中检索到的图像与查询图像相似度较低,我们就可以减少 N 的值,或者增加 M 的值。这个过程是由人工进行的,因为只有人类才能够准确地判断图像之间的相似度。如此一来,我们就可以更好地确定哪些图像应该作为预训练数据集的一部分。
实现细节
总结成以下四点:
Faiss库:Faiss 是一个专门用于高维向量相似度搜索的库。在这个预训练数据集的去重和检索阶段中,我们可以采用 Faiss 库来高效地索引和搜索最近嵌入向量。
GPU加速:本文采用了 Faiss 库的GPU-accelerated indices,利用倒排文件索引(inverted file indices)和乘积量化编码(product quantization codes)进行处理。
集群计算:整个预处理过程是在一个由 20 个节点组成的计算集群上完成的。每个节点都配备了 8 个 V100-32 GB 的 GPU。这样的配置能够更快地进行嵌入向量的计算和搜索,只不过一般人谁玩得起?
通过以上操作,最终生成的 LVD-142M 数据集是一个包含 142 百万张图像的数据集。整个预处理过程只需要不到两天的时间就能够完成。呵呵,笑笑不说话~~~
方法
本文提到了一种用于学习特征的判别式自监督方法,它是 DINO 和 iBOT 损失的结合,并引入了 SwAV 的居中方法。此外,我们还添加了一个正则项来扩展特征,并进行了一个短的高分辨率训练阶段。
简单点理解就是,这种自监督方法是由多个损失函数组成的,包括 DINO(Transformers之间的局部信息最大化),iBOT(特征之间的相似度最小化)和 SwAV(样本中心化)。同时,添加了一个正则项,以使特征在特征空间中更加均匀地分布。此外,DINOv2 中还进行了一个短暂的高分辨率训练阶段,以进一步提高特征的鲁棒性。这些方法的详细实现可以在相关的论文或我们的开源代码中找到。
Image-level objective
这个方法被称为图像级目标,是一种用于学习特征的判别式自监督方法。其基本思想是将来自同一图像不同裁剪的视图作为正样本,将来自不同图像的视图作为负样本,使用交叉熵损失函数来衡量这些视图之间的相似性和差异性,从而训练一个学生网络。另外,我们使用指数移动平均方法构建一个教师网络,其参数是过去迭代的加权平均值,以减少训练中的波动。最终,我们使用这两个网络的类令牌特征作为特征表示。
Patch-level objective
这个方法是另一种用于学习特征的自监督方法,称为 Patch 级目标。在这种方法中,作者将输入的一些 Patch 随机地遮盖掉,只将未被遮盖的 Patch 提供给教师网络,然后使用交叉熵损失函数来衡量学生和教师网络在每个被遮盖的 Patch 上的特征表示的相似性和差异性,从而训练学生网络。同时,我们可以将 Patch 级别的损失与图像级别的损失相结合,以便在训练过程中兼顾整体和局部特征。
Untying head weights between both objectives
此方法是针对前两个方法的实验发现进行的改进。在前两个方法中,图像级别和Patch级别的损失函数都共享了一个网络的参数(权重)。但是经过实验观察发现,当两个级别的损失函数共享同样的参数时,模型在Patch级别会欠拟合,在图像级别会过拟合。因此,我们可以考虑将这些参数(权重)解绑,使得模型在两个级别都能够更好地学习特征表示。这个方法的优化目标是在两个级别都得到最佳的结果。
Sinkhorn-Knopp centering
这个方法是对 DINO 和 iBot 两种方法中的一些步骤进行改进。在原来的方法中,教师模型中的 softmax-centering 步骤在某些情况下可能导致不稳定性,因此本文采用了 Sinkhorn-Knopp(SK)批量归一化方法来代替。这个方法的核心思想是通过正则化来使学生和教师网络在特征表示上更加接近。在这个方法中,作者使用了 3 次 Sinkhorn-Knopp 算法迭代来实现归一化。对于学生网络,则仍然使用 softmax 归一化。通过这个方法,我们可以更好地训练学生模型,并获得更好的性能。
KoLeo regularizer
KoLeo regularizer 是一种正则化方法,它通过计算特征向量之间的差异来确保它们在批次内均匀分布。具体来说,它使用了一种名为 Kozachenko-Leonenko 差分熵估计的技术,这是一种估计随机样本密度的方法。在计算这个正则化器之前,特征向量会被进行“2-范数归一化”(将每个向量的所有元素平方和开根号并除以该和),以确保它们具有相同的长度。这个正则化器的作用是减少特征向量之间的差异,从而使它们在整个批次内均匀分布。
Adapting the resolution
这一步主要是涉及在预训练的最后一段时间内,将图像的分辨率提高到 518×518 ,便在下游任务中更好地处理像素级别的信息,例如分割或检测任务。高分辨率的图像通常需要更多的计算资源和存储空间,因此只在预训练的最后阶段使用这种方法,以减少时间和资源成本。
实现
下面介绍下几个训练模型的优化方法。本文方法采用的是最新发版的 PyTorch 2.0,同时在 A100 GPU 上进行训练,作者开放了包括预训练模型在内的代码。
关于模型细节可以在附录的表格17中查看。与 iBOT 实现相比,DINOv2 的代码在相同硬件下运行速度提高了2倍,内存使用量也只有 iBOT 的 1/3 。
Fast and memory-efficient attention
首先,为了提高自注意力层的速度和内存使用效率,作者基于 FlashAttention 实现了一个新的版本。由于 GPU 硬件的特殊性,每个 head 的嵌入维度是 64 的倍数时效率最佳,并且当整个嵌入维度是 256 的倍数时,矩阵运算效率更好。因此,为了最大化计算效率,本文使用嵌入维度为 1536 的 24 个头(64 dim/head),而不是使用嵌入维度为 1408 的 16 个头(88 dim/head)。实验结果表明,最终的准确率没有显著差异,整个 ViT-g 骨干网络包含 1.1B 个参数。
Nested tensors in self-attention
为了提高计算效率,本文实现了一个可以在同一个前向传递中运行全局裁剪和局部裁剪(它们具有不同数量的补丁标记)的版本,这种实现与之前的实现相比具有更好的计算效率。此外,还使用了 xFormers 库的一些低级组件。
Efficient stochastic depth
在传统的stochastic depth方法中,由于每个残差块在训练过程中可能会随机丢弃,因此需要在前向计算时对每个残差块的输出进行屏蔽(mask)以确保正确性。而在这里,实现了一种改进版本的stochastic depth方法,它跳过了被丢弃的残差的计算,而不是对结果进行屏蔽。这样可以节省内存和计算资源,并且在高丢弃率下具有更好的计算效率和内存使用率。具体地,实现方式是在批次维度上随机重排样本,并将第一个(1 - d)× B个样本用于块的计算。
Fully-Sharded Data Paralle
FSDP 技术的作用是使训练过程可以更加高效地扩展至多个 GPU 节点。具体地,在使用 AdamW 优化器进行训练时,需要使用4个模型副本,包括 student, teacher, optimizer 的一阶和二阶动量,对于一个类似于 ViT-g 这样动不动 10 亿参数的模型,这意味着我们至少需要 16GB 的内存。因此,为了降低每个 GPU 的内存占用,作者使用了 FSDP 技术,将模型副本分片放置在多个 GPU 上。
如此一来,模型大小不再受单个 GPU 的内存限制,而是受到整个计算节点的 GPU 内存总和的限制。FSDP 还具有第二个优点,即可以节省跨 GPU 通信成本,因为权重分片存储在 float32 精度中,而广播权重和减小梯度则使用 float16 精度进行计算。与其他自监督预训练方法中使用的 float32 gradient all-reduce operation 相比,这样做可以将通信成本降低约50%。因此,与 DDP 和 float16 自动类型转换相比,Pytorch-FSDP 混合精度在几乎所有情况下都更加优越。
Gradient AllReduce 是在分布式深度学习中,一种将梯度从不同 GPU 节点上的模型参数收集和组合成单个梯度张量的操作。通常,在使用梯度下降算法时,需要将所有 GPU 节点的梯度合并成单个梯度张量,以更新模型参数。此操作便是实现这一目的的一种并行算法,可以提高模型训练的速度和效率。
Model distillation
模型蒸馏是一种通过在小模型中复制大模型的输出来训练小模型的方法。这种方法旨在通过最小化大模型和小模型对一组给定输入的输出之间的距离来实现。对于该论文中的训练,研究人员利用了同样的训练循环,使用一个更大的模型作为冻结的教师模型,保留学生模型的 EMA 作为最终模型,并且移除了遮蔽和随机深度。
实验
定量分析

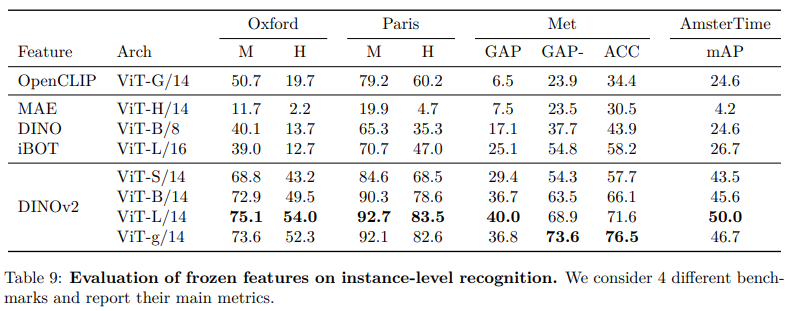

定性分析



总结
本文介绍了第一个基于图像数据的 SSL 工作——DINOv2,这是一种用于在大型图像数据集上预训练图像编码器,以获得具有语义的视觉特征。这些特征可用于广泛的视觉任务,无需微调即可获得与有监督模型相当的性能。该方法的关键是基于精心设计的数据流管道构建大规模的图像数据集,以及一些技术改进,如 Stochastic Weight Averaging、Efficient Stochastic Depth和Fully-Sharded Data Parallel等。此外,本文充分展示了这些模型的一些性质,如对场景几何和对象部分的理解。作者计划继续在模型和数据规模上进行扩展,并希望将这些视觉特征与简单的线性分类器相结合,用于创建一个语言-视觉联合系统,以处理视觉特征并提取所需的信息。
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!