本文首发至微信公众号:CVHub,不得以任何形式转载或售卖,仅供学习,违者必究!

Title: Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
Paper: https://arxiv.org/pdf/2304.12620.pdf
Code: https://github.com/WuJunde/Medical-SAM-Adapter
导读
SAM 模型在图像分割领域内具有卓越的性能和优秀的交互,已经成为一个备受关注的模型。许多从业人员认为,SAM 已经“完成”了图像分割任务。然而,医学图像分割似乎不在 SAM 的分割范围之内。
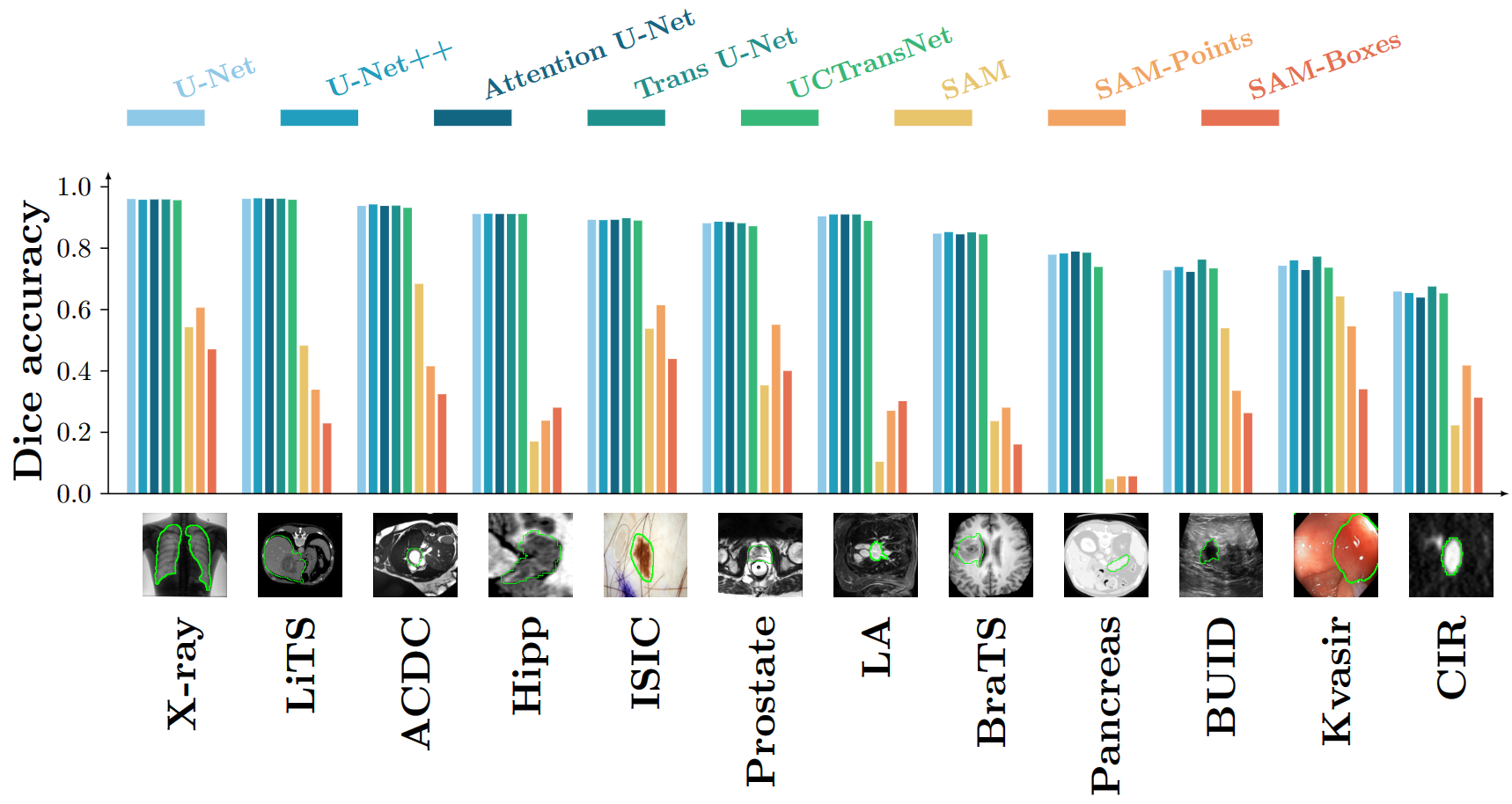
最近的研究表明,如图1所示,SAM 在医学图像分割方面的表现不尽如人意。因此,需要寻找缺失的部分来扩展 SAM 的分割能力。本文提出了 Medical SAM Adapter (MSA),将医学特定领域知识通过简单而有效的适应技术集成到分割模型中,而不是仅对 SAM 模型微调。
MSA 在 19 个医学图像分割任务中展现了卓越的表现,包括 CT、MRI、超声图像、眼底图像和皮肤镜像。与 nnUNet、TransUNet、UNetr、MedSegDiff 等各种先进的医学图像分割方法相比,MSA 表现出色,甚至超越了完全微调的 MedSAM。
创作背景
SAM 无法有效应用在医学图像分割领域最主要的一个原因即是,缺乏足够的训练数据。为了扩展 SAM 到医学图像分割任务中,本文采用了一种名为 Adaption 的参数高效微调技术,通过微调已经预训练好的 SAM 模型以实现事半功倍的效果。
::: block-1
为什么需要 SAM 模型来进行医学图像分割任务?
交互式分割是所有分割任务的范式,而
SAM提供了一个很好的框架,使其成为实现基于提示的医学图像分割的一个完美起点。
为什么需要对模型进行微调?
SAM已经在最大的分割数据集上训练过,预训练模型是有价值的,因为许多研究表明,在自然图像上预训练也对医学图像分割有益,至少在收敛速度上。
为什么选择 Adaption 技术?
Adaption技术是一种高效的微调策略,可以在特定用途的基础模型上微调少量的参数,避免灾难性的遗忘和在低数据情况下更好的泛化。Adaption技术已经在自然图像处理领域中被广泛使用,并且在计算机视觉中也被证明是一种有效的工具,能够轻松地应用于各种下游计算机视觉任务中。
:::
在实验验证中,MSA 表现出了出色的性能,表明使用这种技术可以在最小的工作量下扩展 SAM 模型到医学领域,实现高质量的医学图像分割。
本文主要贡献包括:
-
将流行且强大的
SAM模型扩展到医学领域,这是朝着“分割任何东西”的终极目标迈出的重要一步。 -
首次提出将适应性方法用于医学图像分割。我们在设计适配器时考虑了领域特定的知识,例如医学数据的高维度 (
3D) 和解码器的点击和目标框提示的独特设置。 -
在
19个医学图像分割任务中评估了MSA模型,包括 MRI、CT、眼底图像、超声图像和皮肤镜图像等不同的图像模态。结果表明,MSA在性能上显著优于以前的最先进方法。
方法
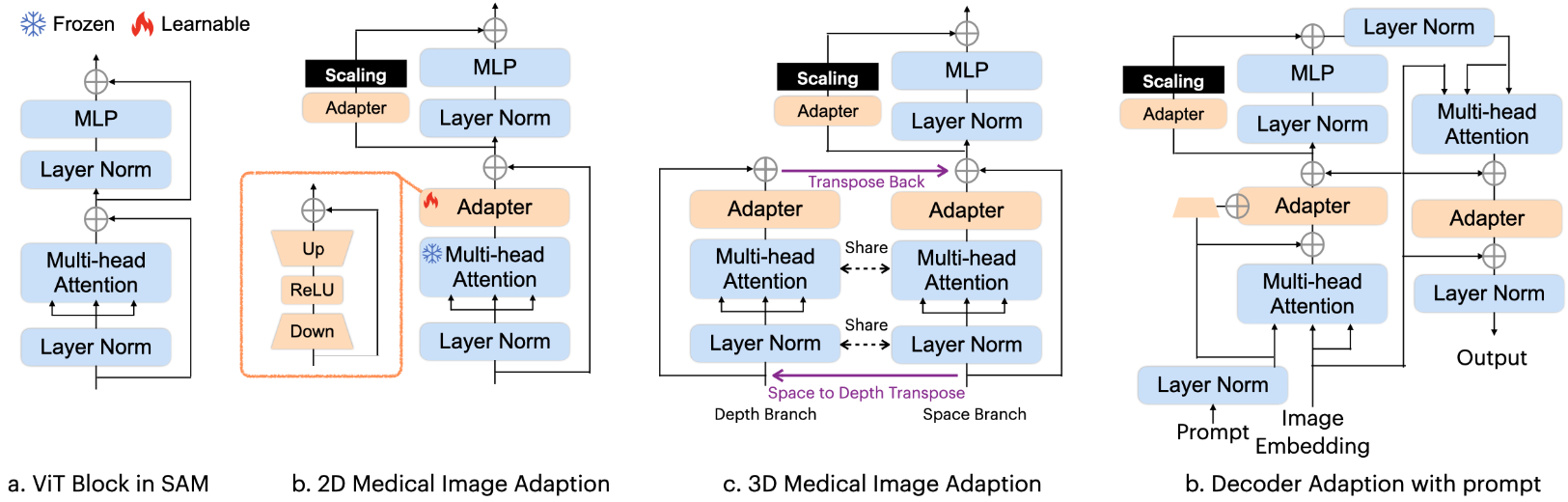
MSA 网络架构
我们在 SAM 网络架构的特定位置插入了一个 Adapter 模块,来实现 fine-tune。
Adapter 是一个瓶颈模型,如图2(b)所示,组合顺序为下投影、ReLU 激活和上投影。下投影使用简单的 MLP 层将给定的嵌入压缩到较小的维度。上投影使用另一个 MLP 层将压缩的嵌入扩展回其原始维度。
在 SAM 编码器中,如图2(b)所示,每个 ViT 块部署了两个适配器,第一个适配器位于多头注意力后,第二个适配器位于 MLP 层的残差路径上。
在 SAM 解码器中,如图2(d)所示,每个 ViT 块部署了三个适配器,分别是 prompt-to-image 嵌入的多头交叉注意力后、MLP-enhanced 嵌入后和图像嵌入到 prompt 交叉注意力的残差连接后。
为了适应医学图像中的三维特点,我们提出了一种基于图像到视频适应的新颖方法,如图2©所示,在每个块中将注意力操作分为空间分支和深度分支。
训练策略
编码器预训练
数据方面,我们采用了四个医学图像数据集,包括包含 135 万张放射学图像 (CT、MRI、US) 的 RadImageNet 数据集、包含 88702 张彩色眼底图像的 EyePACSp 数据集、包含约 3 万张具有黑色素瘤或痣的皮肤镜图像的 BCN-20000 和 HAM-10000 数据集。
训练方面,我们使用多种自监督学习方法进行预训练,包括对比嵌入混合 (e-Mix) 和洗牌嵌入预测 (ShED) 以及掩码自编码器 (MAE)。
e-Mix 是一种对比目标,将一批原始输入嵌入混合,加权它们以不同的系数。它然后训练一个编码器,使其产生一个混合嵌入的向量,该向量与按比例加权的原始输入嵌入接近。
ShED 对一部分嵌入进行洗牌,并使用分类器训练编码器以预测哪些嵌入被扰动。
此外,我们还使用了 SAM 原始实现中的掩码自编码器(MAE),它屏蔽了一定比例的输入嵌入,并训练模型对其进行重构。
Training with Prompt
在图像处理中,prompt 通常是一种辅助训练的方法,它可以提供额外的信息来帮助模型更好地理解图像或文本。
我们使用了两种 prompt 策略来训练模型,分别是 click prompt 和 text prompt。
click prompt 是基于点击标注的策略,正点击表示前景区域,负点击表示背景区域。我们采用了随机采样和迭代采样的方式进行训练。
随机采样是为了初始化模型,而迭代采样则模拟了真实用户的交互过程。在迭代采样中,每个新的点击都会放置在之前预测错误的区域,这样模型就可以通过不断调整来逐渐逼近真实结果。
text prompt 是基于文本信息的策略,我们使用 ChatGPT 随机生成包含目标定义的多个自由文本,并提取这些文本的嵌入作为 prompt 进行训练。
由于 CLIP 几乎没有在医学图像数据集上进行过训练,因此它很难将图像上的器官/病变与相应的文本定义联系起来。因此,使用自由文本作为 prompt 可以提供更多的有关目标的定义和描述,从而更好地辅助模型进行训练。
实验
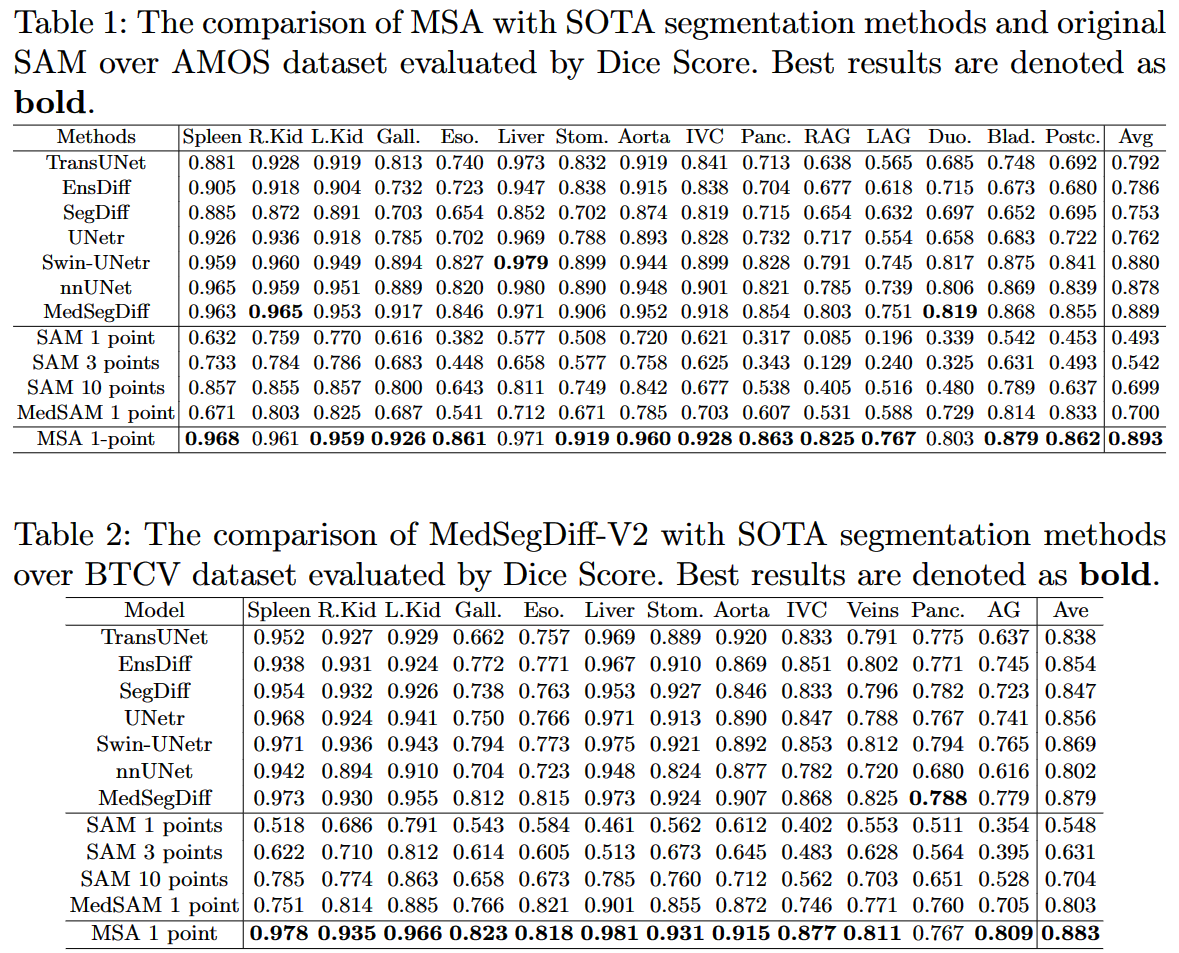
相比于在自然图像数据集中的表现,
SAM的零样本迁移能力在医学图像上表现较差。MSA使用正确的微调技术和优秀的预训练模型,取得了很好的效果,在AMOS和BTCV数据集上的表现甚至优于专门针对医学图像优化的模型。
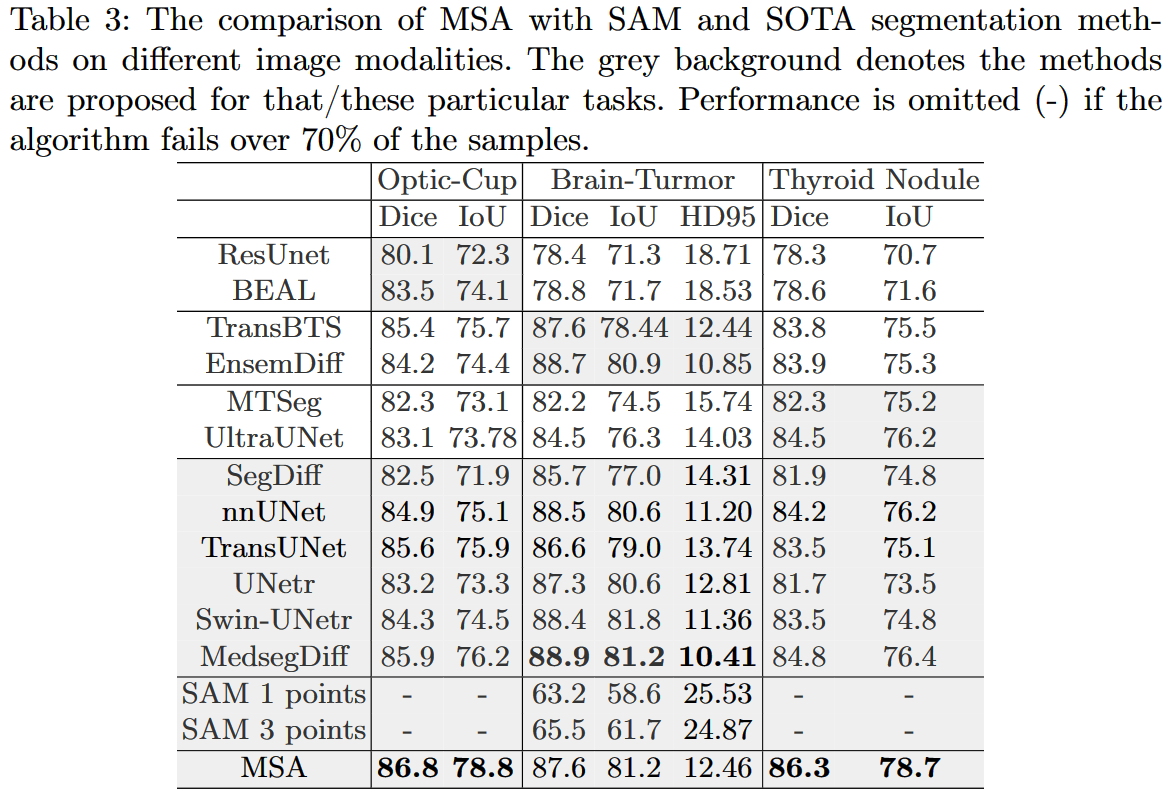
通过使用适当的微调技术和预训练模型,
MRA取得了比SAM更好的结果,超过了许多针对特定医学图像分割任务的优化模型。此外,MRA在一些特定任务上表现优异,展示了它对不同的医学图像分割任务和图像模态具有很好的泛化能力。

MSA在难以被人眼识别的部位进行了准确的分割,而SAM则在一些器官其实很清晰的情况下失败了。这再次说明了,在医学图像分割中,对于一个通用分割模型进行精细调整是非常必要的。
总结
本文将通用分割模型 SAM 扩展到医学图像分割领域,并命名为 MSA。通过采用参数有效的适应性技术,一种成本效益的微调技术,我们在 19 个医学图像分割任务中实现了显著的改进,并在 5 种不同的图像模态下取得了 SOTA 性能。这些结果证明了我们的适应性方法对于医学图像的适应性是有效的,同时也表明了将通用的分割模型用于医学应用的潜力。我们希望本文可以成为推进通用医学图像分割的起点,并激发新的微调技术的发展。