SimCSE 对比学习方法
某厂四面技术面面试过程问到了这个,遂记录一下,补个漏
早期计算句子相似性的方法
之前写过一篇博客,记录的是比较早期的文本相似性计算方法,感兴趣可以移步 文本相似性计算。
在很多 NLP 任务中都会用到句子向量,例如文本检索、文本粗排、语义匹配等任务。现在有不少基于 Bert 的方式获取句子向量,一些比较改进的方法:例如 Bert-flow 和 Bert-whitening 等。
- 使用预训练好的 Bert 直接获得句子向量,可以是 CLS 位的向量,也可以是不同 token 向量的平均值。
- Bert-flow,Bert-flow 出自论文《On the Sentence Embeddings from Pre-trained Language Models》,主要是利用流模型校正 Bert 的向量。
- Bert-whitening,用预训练 Bert 获得所有句子的向量,得到句子向量矩阵,然后通过一个线性变换把句子向量矩阵变为一个均值 0,协方差矩阵为单位阵的矩阵。
SimCSE
SimCSE: Simple Contrastive Learning of Sentence Embeddings
对比学习的思想就不过多赘述了,其好处之一就是可以利用大量未标注的数据对模型进行训练,同时拉近正样本的距离,使得负样本远离。这篇论文提出了两种SimCSE,有监督和无监督,下面仔细介绍一下这篇论文。
这篇文章重点提出了一个非常有效且simple的无监督对比学习方法来学习句子之间的相似性。

模型整体结构如图所示:包含无监督方法和有监督方法。
无监督
无监督模型,一个句子通过encoder得到sentence embedding,而其他句子得到的sentence embedding是作为负例。
正例的设置,对于同一个句子采用两个不同 Dropout Mask,得到两个不同的句向量作为正样本,通过不同的drop mask机制得到的sentence embedding。
dropout层在训练时是会随机drop一些输入的,具有一定的随机性,但是总体来说可以当做是同类样本(感觉mask一些词也是可以的)
训练目标为:
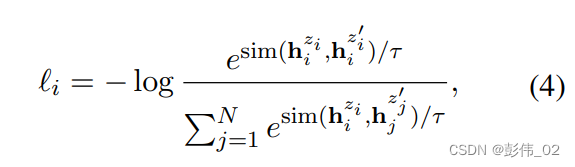
其中,sim()是余弦距离;
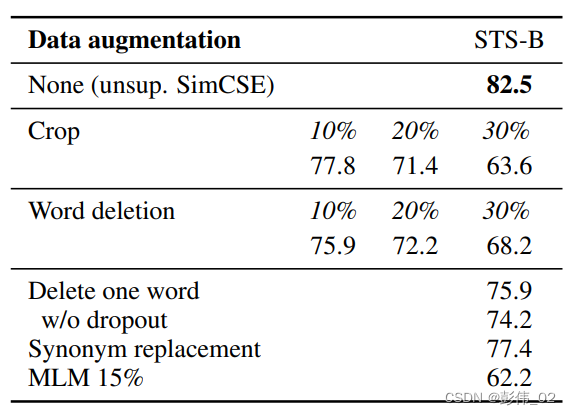
作者对比了 Dropout 和其他数据增强方法的效果 (评价指标是 Spearman 相关系数),结果如下表所示,其中 None 表示 SimCSE 用到的 Dropout 方法,可以看到通过 Dropout 生成正样本的效果比其他数据增强方式好。
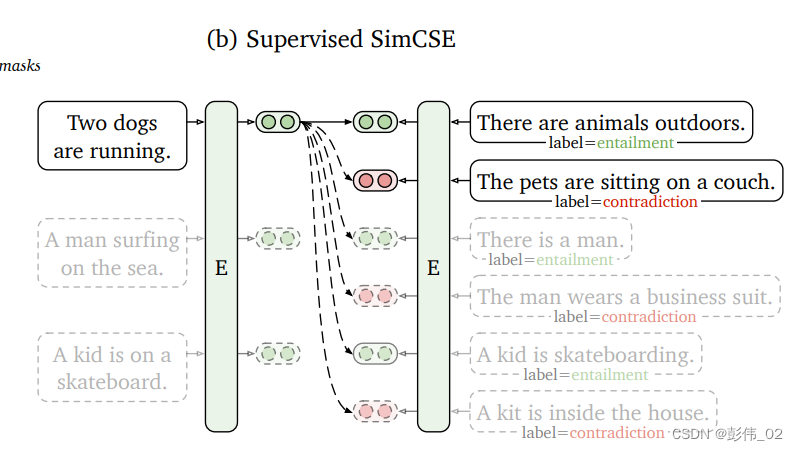
有监督
SimCSE 也可用于有监督训练,例如可以使用自然语言推理数据集 (SNLI 和 MNLI) 进行有监督学习,自然语言推理数据集包含很多句子对,句子对有三种关系: 蕴含 (entailment), 中性 (neutral), 矛盾 (contradiction)。可以把蕴含和中性的句子对作为正样本,矛盾的句子对作为负样本进行训练。
训练目标:
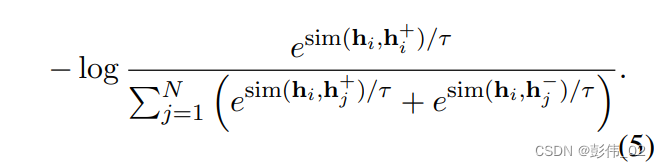
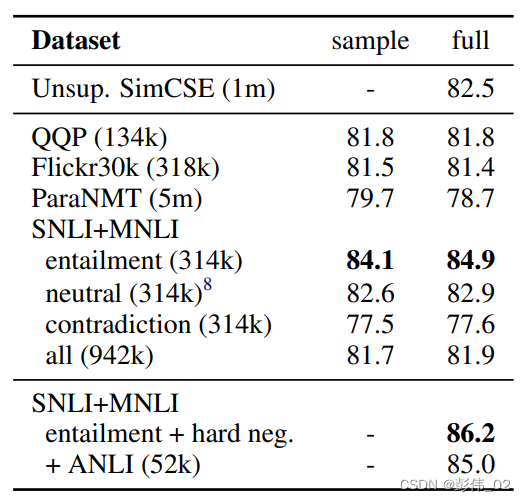
下面是各种常见句子向量算法的对比,可以看到 SimCSE 的效果最好。

总结:
用了一个非常简单的方法,但是效果很好,可以广而用之,网上也有很多复现的开源代码可以学习。
感兴趣的可以参考 github