
随着人形机器人行业的快速发展,其在现实生活中的应用也愈发变得可能。如何在适应不同的地面环境的同时,还能保证机器人的行走安全,是一个亟待解决的课题。
作者 | 优必选
优必选科技与代尔夫特理工大学丁加涛博士、香港中文大学(深圳)林天麟教授(兼任深圳市人工智能与机器人研究院智能机器人中心主任)、利兹大学黄艳龙教授合作,联合发表了论文《Safe and Adaptive 3-D Locomotion via Constrained Task-Space Imitation Learning》。该论文针对人形机器人安全步行,通过线性化3D捕获条件并结合任务空间的模仿学习,实现人形机器人在不需要大量示教数据的情况下,快速获得稳定、安全的行走步态。
论文地址:https://ieeexplore.ieee.org/document/10049251
目前,该论文被美国电子电气工程师协会(IEEE)和美国机械工程师协会(ASME)共同主办的机电工程顶级期刊《IEEE/ASME机电一体化汇刊》(IEEE/ASME Transactions on Mechatronics,简称“TMECH”)收录。

摘要概述
近年来,双足步行控制得到了广泛研究,其中被动安全(即双足快速制动而不会摔倒)是实现人形机器人走向实际应用必须要首先解决的关键问题。本文通过将安全性约束集成到模仿学习框架中,赋予人形机器人安全行走能力并使之具备环境适应性。
与之前基于非线性的、耦合的捕获动力学的方法不同,该论文通过选取适当的极值将 3D 捕获条件线性化,然后将它们整合到最新的受限模仿学习框架中。此外,文中提出了一种启发式规则来定义控制点,从而实现自适应步态的学习。所提出的框架不需要手动生成步行参考轨迹,允许机器人从少量示教轨迹中快速地学习运动技能,并能将学到的技能应用到新的3D场景中。
与深度强化学习不同,该框架避免了大量迭代优化,也避免了从模拟到真实迁移(sim-to-real transfer)的难题。由于在任务空间进行学习,所得到的步行控制策略可以快速迁移到不同的样机上。

背景简介
针对人形机器人安全步行,领域内已经从保持平衡和避免障碍等方面进行了研究。最近,被动安全概念引起了广泛关注。该任务不仅要求人形机器人在行走过程中能够保持平衡,还要能在迈出有限步甚至零步后紧急制动,即满足N步或零步捕获约束。
现有的工作大都假设机器人行走过程中保持竖直高度恒定,以此获得N步或零步捕获能力。而在3D步行任务(例如,爬楼梯或穿过不平地形)中,垂直高度的变化是不可避免的。针对此问题,现有一些工作从调整“运动的发散分量”(DCM) 角度出发,试图将2D的N/零步捕获拓展到3D。然而,这些工作通常涉及非线性或隐式约束,并且其中大多数需要对质心(CoM)或压力中心(CoP)轨迹进行额外的简化。
此外,为实现N /零步捕获步态的求解,现有的工作依赖于有约束的模型预测控制或者其他的非线性规划方法,但需要在事先通过手动获取参考轨迹。不同于数值优化方法,示教学习(也称为模仿学习)使得模仿人类/机器人现有的步态成为可能。比如,部分研究者使用动态运动基元 (DMP)和核化运动基元(KMP)生成鲁棒的步行模式。然而,他们都未能考虑安全性约束。

本文方法
为了在保证安全的情况下实现自适应 3D 双足步行,本文首先推导出满足安全行走要求的线性、解耦条件;其次,将可行性约束(包括安全性约束)与受限模仿学习相结合,提出一个能够在满足安全约束的同时模仿示教运动的步态学习框架;最后,借助线性倒立摆 (LIP)模型,定义任务空间中的控制点,以实现自适应步态的学习。
3D 捕获条件
3D DCM可表示为:

with
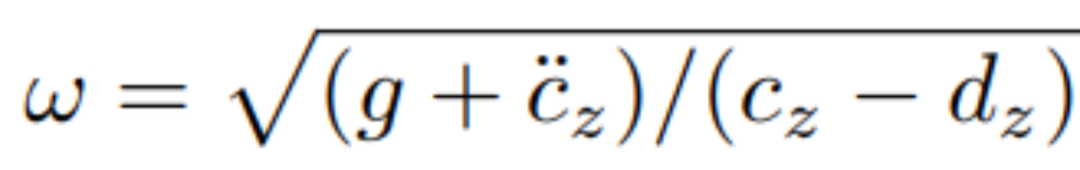 (1)
(1)
其中,![]() 表示DCM,
表示DCM,![]() 和
和![]() 表示质心位置和速度,
表示质心位置和速度,![]() 表示固有频率,
表示固有频率,![]() 是重力加速度,
是重力加速度,![]() 为质心高度,
为质心高度,![]() 为支撑腿高度,
为支撑腿高度,![]() 为质心竖直方向加速度。
为质心竖直方向加速度。
式(1)表明DCM运动跟质心的竖直方向上的运动呈非线性相关。通过选取适当的极值(![]() 和
和![]() ),可以简化上述关系。即通过限定:
),可以简化上述关系。即通过限定:
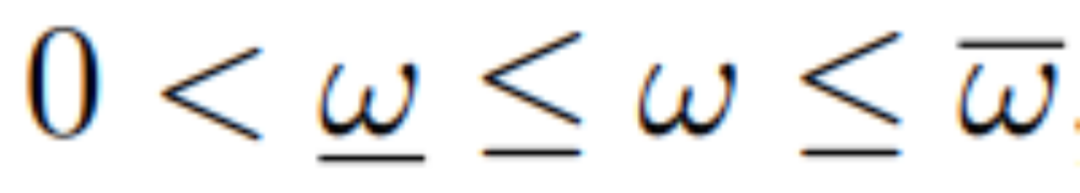 (2)
(2)
可以对DCM施加线性约束,即:
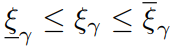 (3)
(3)
其中,![]() 和
和![]() 可以
可以![]() 和
和![]() 根据式(1)确定。
根据式(1)确定。
基于此,可以给出线性的捕获条件。以一步捕获为例,安全性条件可表示为:
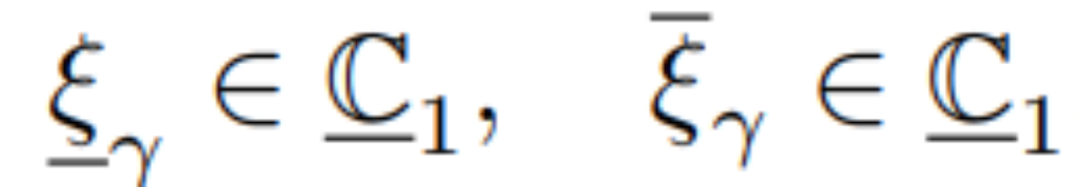
with
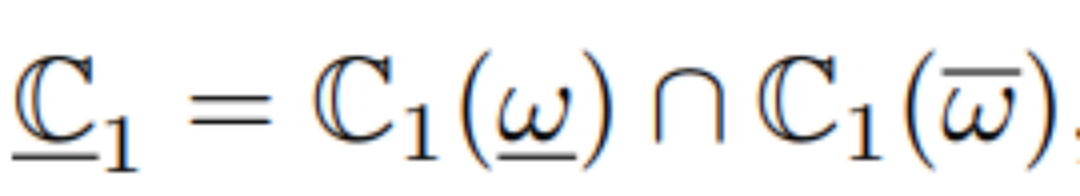 (4)
(4)
式(4)中所涉及的具体细节请参考全文和参考文献[1]。
图1展示了本文使用的线性化策略的基本思想。
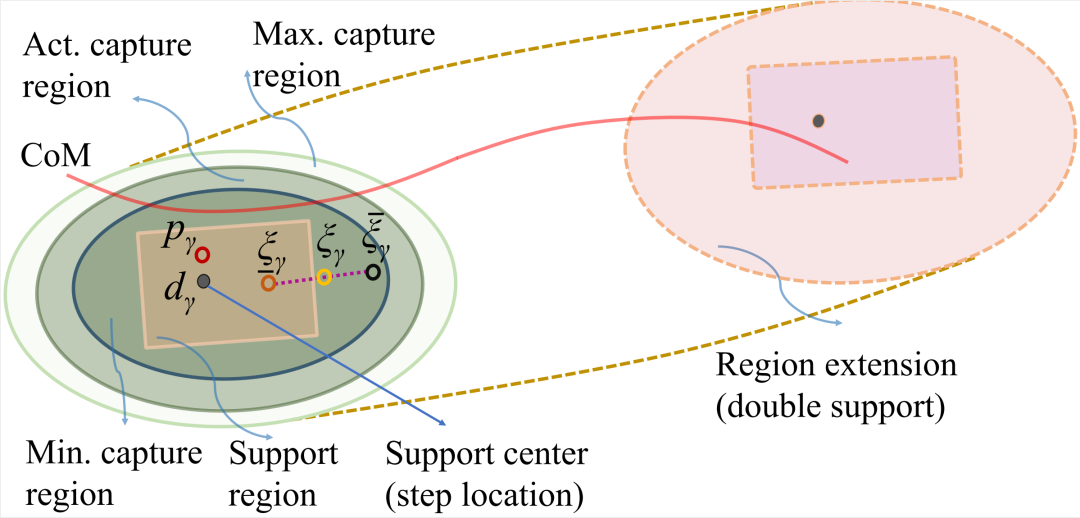
图1:安全行走所允许的捕获区域(capture region)的近似:“Act. Capture region”表示使用变化的自然频率计算的捕获区域。“Max.”和“Min.”对应的最大和最小捕获区域由固有频率的边界值计算得到。
考虑安全性约束的受限模仿学习
参考文献[2]提出了一种可以处理线性约束的模仿学习方法(LC-KMP)。该方法通过求解以下约束优化问题实现对示教轨迹的学习。
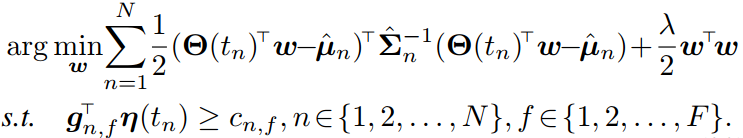 (5)
(5)
上式中各物理符号的意义参见论文全文和参考文献[2].
在本文中,为了获得一定的鲁棒性,我们使机器人同时学习未来两步的运动。其中在第一步中遵循一步捕获条件,在第二步中考虑零步捕获条件。与大多数忽略双足支撑阶段的工作不同,本文在构造公式(5)中的约束条件时,显性地考虑了单/双足支撑阶段的切换,如图2所示。此外,除捕获条件外,本文还考虑了质心运动等可行性约束。
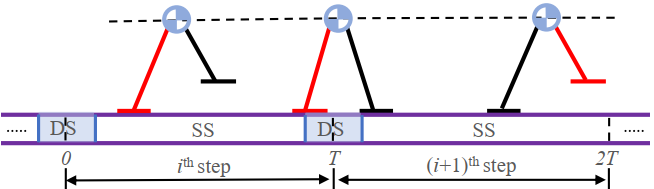
图2:考虑双足支撑的行走动作。在第二步的末尾,我们只考虑单腿支撑,行成更加严格的安全性保证。
基于启发式规则的控制点选取
LC-KMP的另一大特点是可以通过选取适当的控制点,从而生成满足不同任务需求的轨迹。本文针对双足步行学习任务,在两步运动中定义四个期望点,其中第一点和第四点用于确定开始和结束状态,而第二点和第三点用于满足任务需求。为了满足安全性约束,在每个时刻分别选取CoM位置、速度和加速度。对于水平运动,使用LIP模型确定参考运动状态,见图3。对于高度变化,采用启发式规则进行参考状态的选取,见图4。
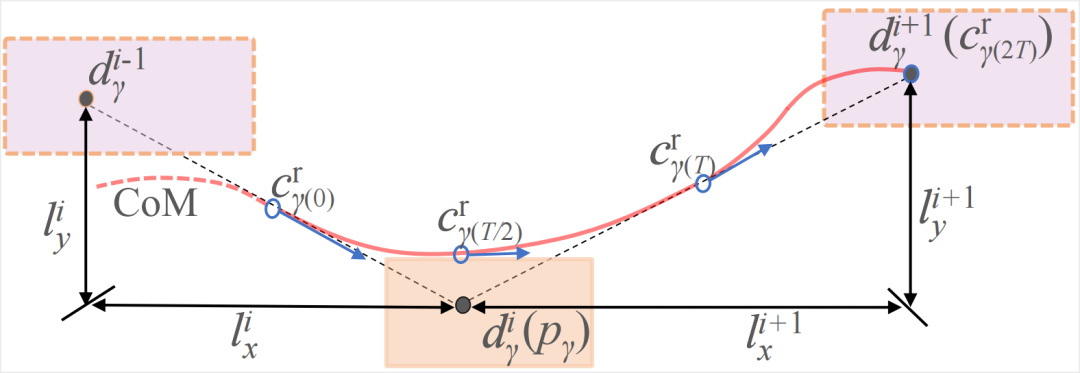
图3:水平面控制点的选取
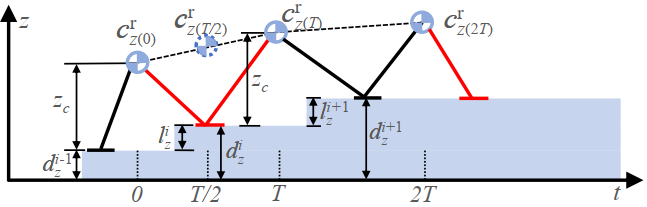
图4:高度方向控制点选取

优必选Walker2 真机实验
为验证方法的有效性,研究团队在优必选的Walker2人形机器人上进行了大量实验。首先采集Walker2机器人周期行走生成的步态数据作为示教。然后,使用上述的框架生成针对不同任务需求的3D步态。测试任务包括在非平整地面上行走(图5第二行)、上台阶(图5第三行)和直膝行走(图5第四行)等。实验数据表明,该算法能够满足不同任务需求,生成满足安全性需求的双足步态。并且,在不同的任务下,机器人都能够实现单腿急停。

图5:机器人平整地面上示教行走(第一行)和不同任务下安全行走:不平地面行走(第二行), 上台阶(第三行)和直膝行走(第四行)。机器人头顶上方的红色箭头指示运动方向。

小结
在本文中,我们为双足步行开发了一个考虑约束的模仿学习框架。该框架能够处理包括线性化的安全约束在内的大量可行性约束。实验表明,所提出方法可以从少量的2D(无竖直高度变化)场景演示中学习行走技能,并在严格遵守安全限制的前提下泛化到新的3D场景。
我们认为,这一方法未来还能够应用到人形机器人更复杂、更高维的动作中(如跑步或跳跃等),并在这个过程中确保机器人的动作安全。这也是提升人形机器人环境适应能力的一次正向尝试。
完整的结果和分析参见全文:
https://ieeexplore.ieee.org/document/10049251
参考文献
[1] T. Koolen, T. De Boer, J. Rebula, A. Goswami, and J. Pratt,“Capturability-based analysis and control of legged locomotion, part 1: Theory and application to three simple gait models,” Int. J. Robot. Res., vol. 31, no. 9, pp. 1094–1113, July 2012.
[2]Y. Huang and D. G. Caldwell, “A linearly constrained nonparametric framework for imitation learning,” in Proc. IEEE Int. Conf. Robot. Autom., 2020, pp. 4400–4406.
