通俗的讲内连接只会查出满足on条件下的记录,外连接则是会查出(tab a left join tab b),不管tab a的记录与tab b的记录是否匹配,tab a都会有记录,只是tab b的记录为不为空而已,
右连接则相反
在使用left join (或 right join )时,应该清楚的知道一下几点:
1.on与where的执行顺序
on 条件(A left join B on 条件表达式中的on)用来决定如何从B表中检查数据行。如果B表中没有任何一行数据匹配ON的条件,将会额外生成一行所有列作为NULL 的数据,在匹配阶段Where子句的条件都不会被使用.仅在匹配阶段完成之后,where子句条件才会被使用。ON将从匹配阶段产生的数据中检索过滤。
所以我们要注意:在使用Left(right)join 的时候一定要先尽可能多的给出匹配满足条件,减少where的执行。
效率一般:
select * from A inner join B on B .name = A.name
left join C on C.name = b.name
left join D on D.id = C.id
where C.status >1 and D.status = 1;
效率较好的:
select * from A
inner join B on B.name = A.name
left join C on C.name = B.name and C.status>1
left join D on D.id = C.id and D.status = 1
从上面的例子可以看出,尽可能满足On 的条件,而少用where的条件,从执行性能;来看第二个显然更加省时。
2. 注意On子句和where子句的不同
select * from product left join product_details on (product.id = product_deals.id) and product_deals.id = 2;
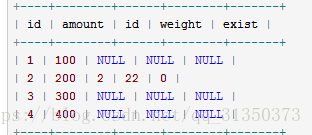
select *from product left join product_details on (product.id = product_details.id) where product_details.id = 2;
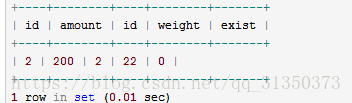
从上可知,第一条查询ON条件决定了从left join 的 product_details表中检索符合的所有数据行。第二条查询做了简单的LEFT JOIN,然后使用 WHERE 子句从 LEFT JOIN的数据中过滤掉不符合条件的数据行。
3. 尽量避免子查询,而用join
性能更多时候是体现在数据量大的时候,此时,我们应该避免复杂的子查询。
效率一般的:
insert into t1(a1) select b1 from t2 where not exists(select 1 from t1 where t1.id = t2.r_id);
效率较好的:
insert into t1(a1) select b1 from t2 left join (select distinct t1.id from t1)t1 on t1.id = t2.r_id where t1.id is null;