意外发现
前两天打算迁移一份数据,自然而想到了Apache Sqoop,遂打开Apache官网寻找下载链接,但是竟然没有找到他的踪影。

这不科学啊,前几个月还看到过来着,有点不死心,直接尝试登陆直接https://sqoop.apache.org/
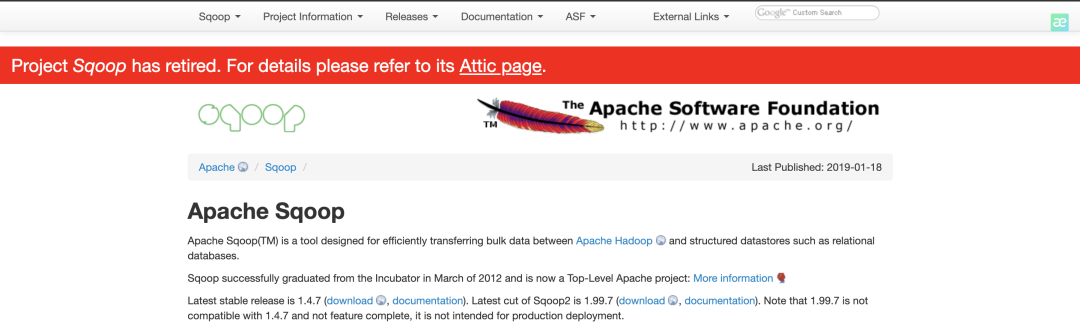
Aapche Sqoop官网
Project Sqoop has retired. For details please refer to its Attic page.
Apache基金会里竟然还有项目退役一说,仔细看了下,原来Apache Sqoop在2021年6月就已经进入Attic了,就是最近的事情。不过,「Attic」是啥啊?并没有听说过;进入到Attic的项目会咋样?,我们继续探索下。

Apache Attic介绍
Apache Attic原来就相当于Apache的小黑屋,如果Apache托管的项目长时间不活跃(超过2年没有release新版本,没有committer、contributer并且没有未来roadmap),就会选择将项目移动到Attic中,这也就相当于Apache的项目管理了,掌管整个项目的生命周期。
Sqoop移动到Attic的项目对咱们有啥影响呢?
目前将Sqoop做数据迁移工具公司不在少数,当Sqoop移动到Attic后,单单使用来说是完全不受影响的;Apache Attic依旧会提供代码库的下载;但是不会再修复任何的bug,release新版本了,并且也不会再重启社区。
看到这里其实就没有这么慌了,我们还能继续用,不过如果遇到问题,我们只能自己建个分支去fix了,从侧面来说,也能说明Sqoop在某个角度是成功的,毕竟曾经成为Apache顶级项目,如果真的是长时间没有release,有可能是他确实已经够成熟了。
准备关闭Attic页面的时候,顺便扫了一眼在Attic中的项目,基本都不认识,但也看到几个熟悉的身影,如Chukwa,Sentry,Eagle。相信也有不少公司在使用,比如我们公司还在使用Sentry。换个角度,现在技术快速更迭太迅速了,随着时间流逝,没准过些年Hadoop、Spark也有可能没落呢。以后的事情又谁知道呢?没辙,继续学吧,今天我们先来聊聊Sqoop。
Sqoop定位和现状
简单来说Sqoop的定位就是Hadoop生态存储和结构化存储之间的数据迁移。我们比较常见的场景就是HDFS/HBase/Hive和MySql/Oracle之间的数据互导。Sqoop作为数据传输的桥梁,通过定义MapReduce的InPutFormat和OutPutFormat来对接源存储和目的存储。
注意在Sqoop中上只会涉及MapReduce中的Map阶段,而不会有Reduce阶段
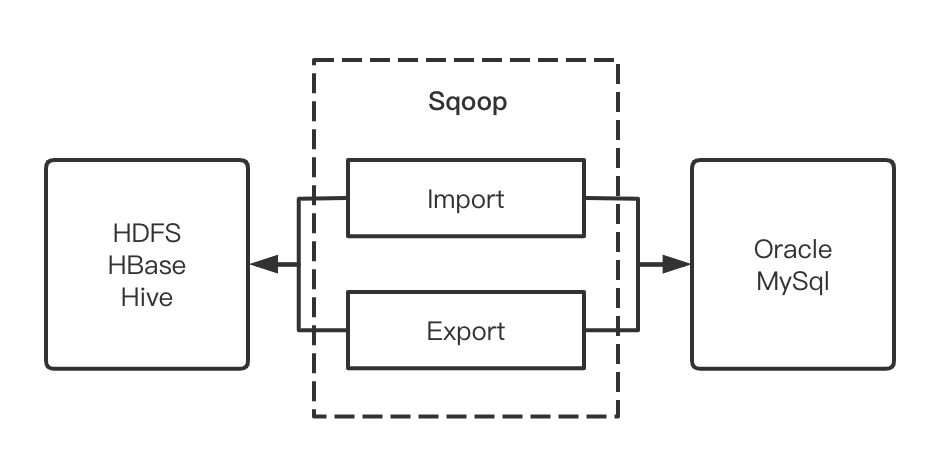
Sqoop架构简图
目前Sqoop总体有两大版本分为Sqoop1和Sqoop2,Sqoop1的最新release是1.4.7;Sqoop2的最新release是1.99.7;这里如果大家使用的话推荐使用Sqoop1,而Sqoop2虽然增加了CLI和Rest api,但实际上是一个半成品,跟Sqoop1也完全不兼容,并且无论是CDH还是之前Apache都是不建议生产使用的,自己随便玩玩还可以。本篇主要介绍的版本还是基于Sqoop1.
Sqoop迁移原理
核心逻辑
整个Sqoop的迁移过程,都会对应着一个MapReduce作业,实际上只有Map阶段,而迁移大致分为5个部分,如下所示。
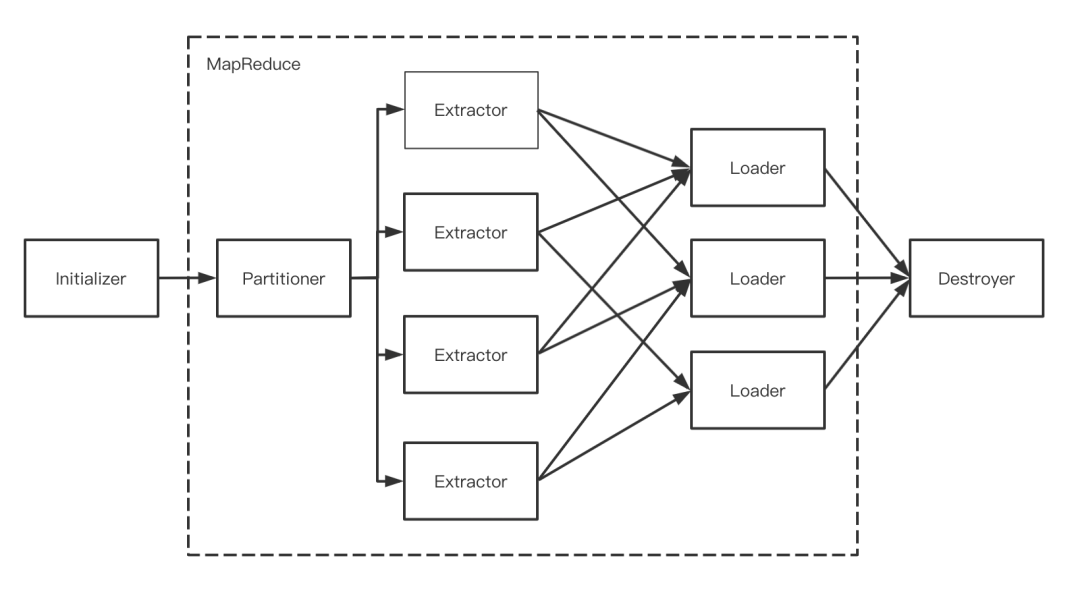
Sqoop逻辑简图
「Initializer」:整个Sqoop迁移的初始化阶段,完成迁移前的准备工作,如连接数据源,创建临时表,添加依赖的jar包等。
「Partitioner」:源数据分片,根据作业并发数来决定源数据要切分多少片。
「Extractor」:开启extractor线程,内存中构造数据写入队列之中;
「Loader」:开启loader线程,从队列中读取数据并写入对应后端;
「Destroyer」:整个迁移的收尾工作,断开sqoop与数据源的连接,完成资源回收;
流程解析
当迁移任务启动后,首先会进入初始化部分,使用JDBC检查导入的数据表,检索出表中的所有列以及列的数据类型,并将这些数据类型映射为Java数据类型,在转换后的MapReduce应用中使用这些对应的Java类型来保存字段的值,在每次Sqoop的任务执行时,代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录,即xxxx.java文件。紧接着Partitioner会根据--split-by或者-m指定整个任务的分片数量,如不指定默认是4个分片(每一个partition对应着一个Mapper),然后编译成一个本地Jar包用于提交MapReduce作业。当任务提交到集群后,每个Mapper会分别启动一个Extractor线程和Loader线程,整个MapReduce的InputFormat实际上是通过JDBC读取原端数据写入到Context中,而Loader线程将从Context中读出写入对应的数据作为OutPutFormat迁移的目的端。当任务执行完成后,yarn资源释放,随之Destroyer回收所有与数据源的连接。这里主要讲述的是Import的过程,而export流程与import十分相似,是把数据解析为一条条insert 语句,在此不过多解析。
Sqoop迁移实战
恰逢本人正在做Doris到Hive的迁移测试(Doris是一个基本兼容MySQL协议的OLAP引擎),实战围绕Doris的进行展开
迁移前准备
-
JDK/ZooKeeper/HDFS/Yarn/Hive的部署不是本篇重点,网上文档很多,可以自行参考部署。
-
本片讲述的是Sqoop1,附下载地址http://archive.apache.org/dist/sqoop/。注意Sqoop部署的的时候需要导入mysql-connector-java.jar,其他正常修改sqoop-env.sh即可,总体Sqoop的部署比较简单。
-
我们先来看看Doris源端数据表格式。该表有3497079条数据
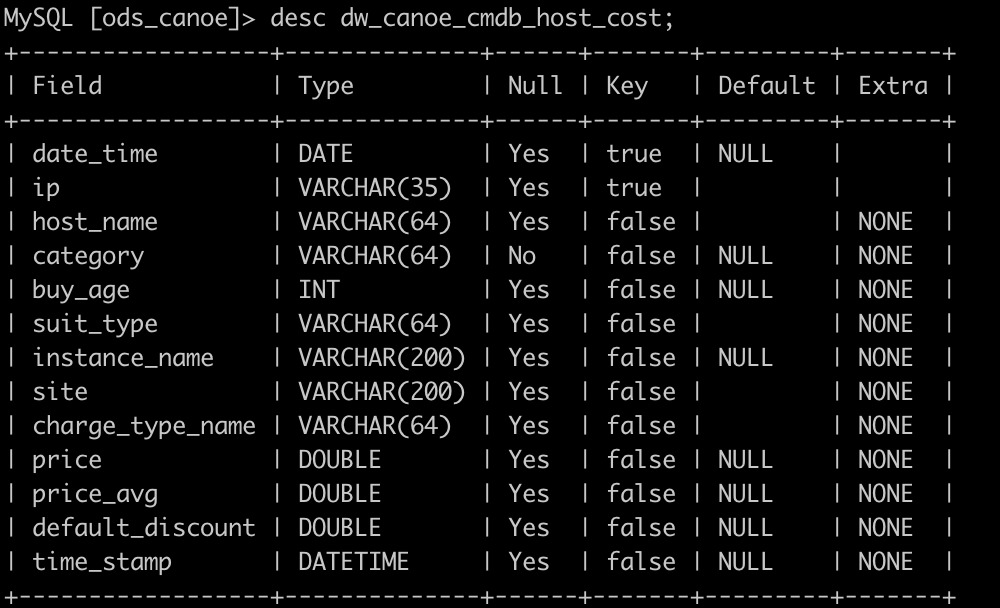
开始迁移
-
启动Sqoop任务开始迁移,会提交MapReduce作业到Yarn上,我们最终的目的是将数据落地到HDFS上。
sqoop import \
--connect jdbc:mysql://Host:IP/ods_canoe # jdbc连接地址
--username user # 用户
--password password # 密码
--delete-target-dir # 删除对应HDFS目录下的数据
--target-dir /Canoe # 对应HDFS的目录位置
--table dw_canoe_cmdb_host_cost # 源端的表名
--split-by buy_age # 根据buy_age字段进行切分,注意是Int类型
--compress # 启动压缩
--compression-codec org.apache.hadoop.io.compress.SnappyCodec # 使用Snappy压缩
-m 10 # 10个分片即10个Map
-
当然我们可以使用Sqoop将Doirs中的数据直接导入到hive中,但由于Doris数据格式DATETIME,在Hive中是不兼容的,因此本次没有使用这种方法。如果数据类型匹配,可以使用如下参数直接导入hive。
--hive-import # 数据导入到hive中
--hive-table testSqoop # hive中的表名
--hive-database default # hive中的库名
-
MapReduce任务执行完成后,我们检查下HDFS是否有数据生成。
hadoop fs -ls /Canoe
Found 11 items
-rw-r--r-- 3 work supergroup 0 2021-06-16 19:58 /Canoe/_SUCCESS
-rw-r--r-- 3 work supergroup 11978345 2021-06-16 19:58 /Canoe/part-m-00000.snappy
-rw-r--r-- 3 work supergroup 11694631 2021-06-16 19:58 /Canoe/part-m-00001.snappy
-rw-r--r-- 3 work supergroup 6726724 2021-06-16 19:57 /Canoe/part-m-00002.snappy
-rw-r--r-- 3 work supergroup 14511453 2021-06-16 19:58 /Canoe/part-m-00003.snappy
-rw-r--r-- 3 work supergroup 10708857 2021-06-16 19:58 /Canoe/part-m-00004.snappy
-rw-r--r-- 3 work supergroup 4459765 2021-06-16 19:57 /Canoe/part-m-00005.snappy
-rw-r--r-- 3 work supergroup 1289616 2021-06-16 19:57 /Canoe/part-m-00006.snappy
-rw-r--r-- 3 work supergroup 94095 2021-06-16 19:57 /Canoe/part-m-00007.snappy
-rw-r--r-- 3 work supergroup 999 2021-06-16 19:57 /Canoe/part-m-00008.snappy
-rw-r--r-- 3 work supergroup 42111 2021-06-16 19:57 /Canoe/part-m-00009.snappy
HDFS结果验证
-
由于我设置的使用Snappy格式进行压缩,我们来检查下实际的行数是否与Doris中相同。
hadoop fs -text /Canoe/*|wc -l
21/05/16 19:58:54 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
3497079
数据导入Hive
-
验证了HDFS数据后,我们来创建Hive表,注意这里有两种选择,
-
创建Hive普通表,然后将数据Load到表中
-
创建Hive外部表,制定到之前导出的/Canoe路径下
「hive普通表方式」
hive> CREATE TABLE `test_sqoop` (
> `date_time` date ,
> `ip` varchar(35) ,
> `host_name` varchar (64) ,
> `category` varchar (64) ,
> `buy_age` int COMMENT ,
> `suit_type` varchar(64) ,
> `instance_name` varchar(200) ,
> `site` varchar(200) ,
> `charge_type_name` varchar(64) ,
> `price` double ,
> `price_avg` double ,
> `default_discount` ,
> `time_stamp` date ) # 注意hive中只有date类型,没有datetime类型
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
hive> load data inpath '/Canoe' overwrite into table test_sqoop;
「2.hive外部表方式」
hive> CREATE external TABLE `test_sqoop` (
> `date_time` date ,
> `ip` varchar(35) ,
> `host_name` varchar (64) ,
> `category` varchar (64) ,
> `buy_age` int COMMENT ,
> `suit_type` varchar(64) ,
> `instance_name` varchar(200) ,
> `site` varchar(200) ,
> `charge_type_name` varchar(64) ,
> `price` double ,
> `price_avg` double ,
> `default_discount` ,
> `time_stamp` date ) # 注意hive中只有date类型,没有datetime类型
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ","
> location '/Canoe';
Hive结果验证
hive> select count(*) from test_sqoop;
Query ID = work_20210816200848_acbb8c1a-b114-4872-9e76-45f5420d02ba
Total jobs = 1
Launching Job 1 out of 1
Starting Job = job_1595742917056_0028, Tracking URL = http://testjie01:23188/proxy/application_1595742917056_0028/
Hadoop job information for Stage-1: number of mappers: 10; number of reducers: 1
2021-06-16 20:08:56,677 Stage-1 map = 0%, reduce = 0%
2021-06-16 20:09:02,938 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 22.88 sec
2021-06-16 20:09:03,975 Stage-1 map = 90%, reduce = 0%, Cumulative CPU 37.03 sec
2021-06-16 20:09:05,010 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 39.51 sec
2021-06-16 20:09:08,131 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 42.16 sec
MapReduce Total cumulative CPU time: 42 seconds 160 msec
Ended Job = job_1595742917056_0028
MapReduce Jobs Launched:
Stage-Stage-1: Map: 10 Reduce: 1 Cumulative CPU: 42.16 sec HDFS Read: 61581414 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 42 seconds 160 msec
OK
349707
其他有意思的功能
「增量同步」可以通过sqoop job创建、执行一个sqoop任务:根据增量字段,记录上一次的最大值,每次同步大于该值的数据增量同步数据至hive,创建任务后每次执行会自动更新--last-value的值。
--incremental append # 增量同步
--check-column abc # 检查的的字段
--last-value 'xxxx-xx-xx xx:xx:xx'
「自定义导入内容」使用 --query参数,用户可以根据需求,自定义所需的内容。
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
「迁移加速」如果迁移MySQL的数据,可以添加--direct参数,使用MySQL的mysqldump去优化JDBC连接数据库部分。
「未提交数据查询」Sqoop 提供读取 read-uncommitted 事务的能力,只需要带上参数 --relaxed-isolation 即可,功能挺有意思,但这个我还没测试过,如果有试过的同学,可以文末留言。
Sqoop的遗憾
总体来说,整个迁移实战的结果是符合预期,Doirs迁移Hive完成。虽然Sqoop功能还强大的,但也有一些小遗憾,如果某个任务失败重试的话,会存在数据重复的问题,这时如果要保证一致性语义,需要通过额外去重操作完成;此外Sqoop迁移过程中,数据实时写入兼容性还不太好。虽然Sqoop2看着规划是挺香的,很遗憾不了了之了,由衷希望Sqoop的社区可以再续往日辉煌。
Bash wishes!!!
「往期原创推荐」
「往期最佳实践」