Linux mmap分析
内核版本:linux-5.16
1. 虚拟内存概要及相关内容简介
内存映射是学习过操作系统的大家都耳熟能详的词,理解起来也很简单。所谓“映射”就是为一种事物与另一种事物建立起连接关系或是某种联系,从而使得通过一种事物可以间接的接触到另一种事物。而“内存映射”,就是将物理内存转换通过MMU转换为进程可访问的虚拟内存,而这段虚拟内存是被保存在进程的内存空间中(32位系统下的进程空间大小位4GB,即0x0000_0000到0xffff_ffff)。
因此使用虚拟内存地址的进程在操作系统中实现了与平台的无关性即与地址的无关,从而极大的提高了程序设计的便捷性以及程序的可移植性;
又由于每个进程的内存空间相互独立,每个进程在运行过程中无论访问任何一个地址都无法直接访问到另一个进程中的数据,从而保证了操作系统运行的可靠性;
再由于内存映射技术是将物理内存直接映射到进程的内存空间,用户态进程可以像操作常规内存空间一样来读写物理内存,在此过程中只会发生一次内存拷贝(具体发生在硬件驱动程序中的读写操作,mmap()中不会发生内存拷贝);而若使用文件IO的方式,即read()和write()系统调用的方式读写物理内存则会发生两次内存拷贝(第一次内存拷贝具体发生在read()和write()函数中,首先将用户态数据从用户空间拷贝进内核空间;第二次内存拷贝具体发生在硬件驱动程序中的读写操作)。因此使用内存映射的方式读写内存要比文件IO的方式效率来的高。([注]:效率具体差别不一定会正好是两倍的关系,这里与代码的具体实现有关)
1.1. mm_struct 和 vm_area_struct
struct mm_struct用于描述Linux系统下进程内存空间的所有信息,在Linux操作系统下,描述一个进程的结构体为task_struct,每一个进程对应一个task_struct结构体,而每个task_struct结构体中也只包含一个mm_struct描述进程空间。
struct vm_area_struct用于描述进程空间内的一段虚拟内存区域。其中包含虚拟内存的起始地址、大小等其它信息,同时还包含了一个对应虚拟内存的操作函数集vm_ops指针,该指针指向对应内存设备驱动的具体操作函数集,而进程最终也会调用到对应的具体内存驱动的操作函数。因此,进程需要对该段虚拟内存进行的任何操作都需要通过vm_area_struct中的成员来完成。而mmap()函数就是完成获取一段进程可用的虚拟内存,并对物理内存的映射,最终根据该段虚拟内存信息创建一个新的vm_area_struct结构体,提供给调用自己的进程使用。
// mm_struct 和 vm_area_struct 的简要成员
struct mm_struct {
unsigned long start_brk, brk, start_stack;
} __attribute__((preserve_access_index));
struct vm_area_struct {
unsigned long start_brk, brk, start_stack;
unsigned long vm_start, vm_end;
struct mm_struct *vm_mm;
} __attribute__((preserve_access_index));
//================================== struct mm_struct ==============================================
//# include/linux/mm_types.h ##------## mm_struct
struct mm_struct {
struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
u64 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES
/* Base addresses for compatible mmap() */
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
#endif
unsigned long task_size; /* size of task vm space */
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd;
#ifdef CONFIG_MEMBARRIER
/**
* @membarrier_state: Flags controlling membarrier behavior.
*
* This field is close to @pgd to hopefully fit in the same
* cache-line, which needs to be touched by switch_mm().
*/
atomic_t membarrier_state;
#endif
/**
* @mm_users: The number of users including userspace.
*
* Use mmget()/mmget_not_zero()/mmput() to modify. When this
* drops to 0 (i.e. when the task exits and there are no other
* temporary reference holders), we also release a reference on
* @mm_count (which may then free the &struct mm_struct if
* @mm_count also drops to 0).
*/
atomic_t mm_users;
/**
* @mm_count: The number of references to &struct mm_struct
* (@mm_users count as 1).
*
* Use mmgrab()/mmdrop() to modify. When this drops to 0, the
* &struct mm_struct is freed.
*/
atomic_t mm_count;
#ifdef CONFIG_MMU
atomic_long_t pgtables_bytes; /* PTE page table pages */
#endif
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some
* counters
*/
/*
* With some kernel config, the current mmap_lock's offset
* inside 'mm_struct' is at 0x120, which is very optimal, as
* its two hot fields 'count' and 'owner' sit in 2 different
* cachelines, and when mmap_lock is highly contended, both
* of the 2 fields will be accessed frequently, current layout
* will help to reduce cache bouncing.
*
* So please be careful with adding new fields before
* mmap_lock, which can easily push the 2 fields into one
* cacheline.
*/
struct rw_semaphore mmap_lock;
struct list_head mmlist; /* List of maybe swapped mm's. These
* are globally strung together off
* init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
atomic64_t pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long def_flags;
/**
* @write_protect_seq: Locked when any thread is write
* protecting pages mapped by this mm to enforce a later COW,
* for instance during page table copying for fork().
*/
seqcount_t write_protect_seq;
spinlock_t arg_lock; /* protect the below fields */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
struct user_namespace *user_ns;
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_subscriptions *notifier_subscriptions;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and
* migrate pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads setting pte_numa */
int numa_scan_seq;
#endif
/*
* An operation with batched TLB flushing is going on. Anything
* that can move process memory needs to flush the TLB when
* moving a PROT_NONE or PROT_NUMA mapped page.
*/
atomic_t tlb_flush_pending;
#ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH
/* See flush_tlb_batched_pending() */
bool tlb_flush_batched;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_PREEMPT_RT
struct rcu_head delayed_drop;
#endif
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
#ifdef CONFIG_IOMMU_SUPPORT
u32 pasid;
#endif
} __randomize_layout;
/*
* The mm_cpumask needs to be at the end of mm_struct, because it
* is dynamically sized based on nr_cpu_ids.
*/
unsigned long cpu_bitmap[];
};
//==================================== struct vm_area_struct ==============================================
//# include/linux/mm_types.h ##------## vm_area_struct
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
/*
* Access permissions of this VMA.
* See vmf_insert_mixed_prot() for discussion.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_lock &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifdef CONFIG_SWAP
atomic_long_t swap_readahead_info;
#endif
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
1.2. 内存访问流程简介
linux中对进程状态的控制由task_struct结构体描述,并通过进程控制块PCB管理,在每个task_struct中用于描述当前进程虚拟内存的结构体为mm_struct,其中pgd用于指向当前进程的页表。而一个进程访问内存的大致流程如下。
每个进程都拥有自己的页表,页表中的每一各条目称为页表项(PTE),页表项中存储的时虚拟地址(vm)与物理地址(pm)之间的映射关系,相同的虚拟地址经过MMU硬件转换后,每个进程的虚拟内存会分别映射到物理内存的不同区域,彼此相互隔离并独立。
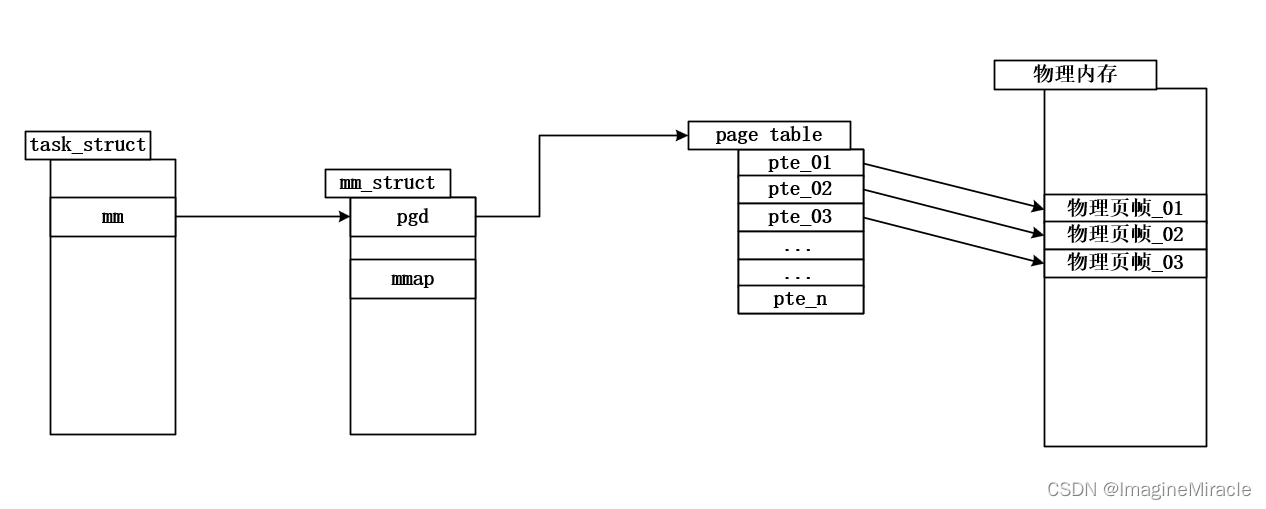
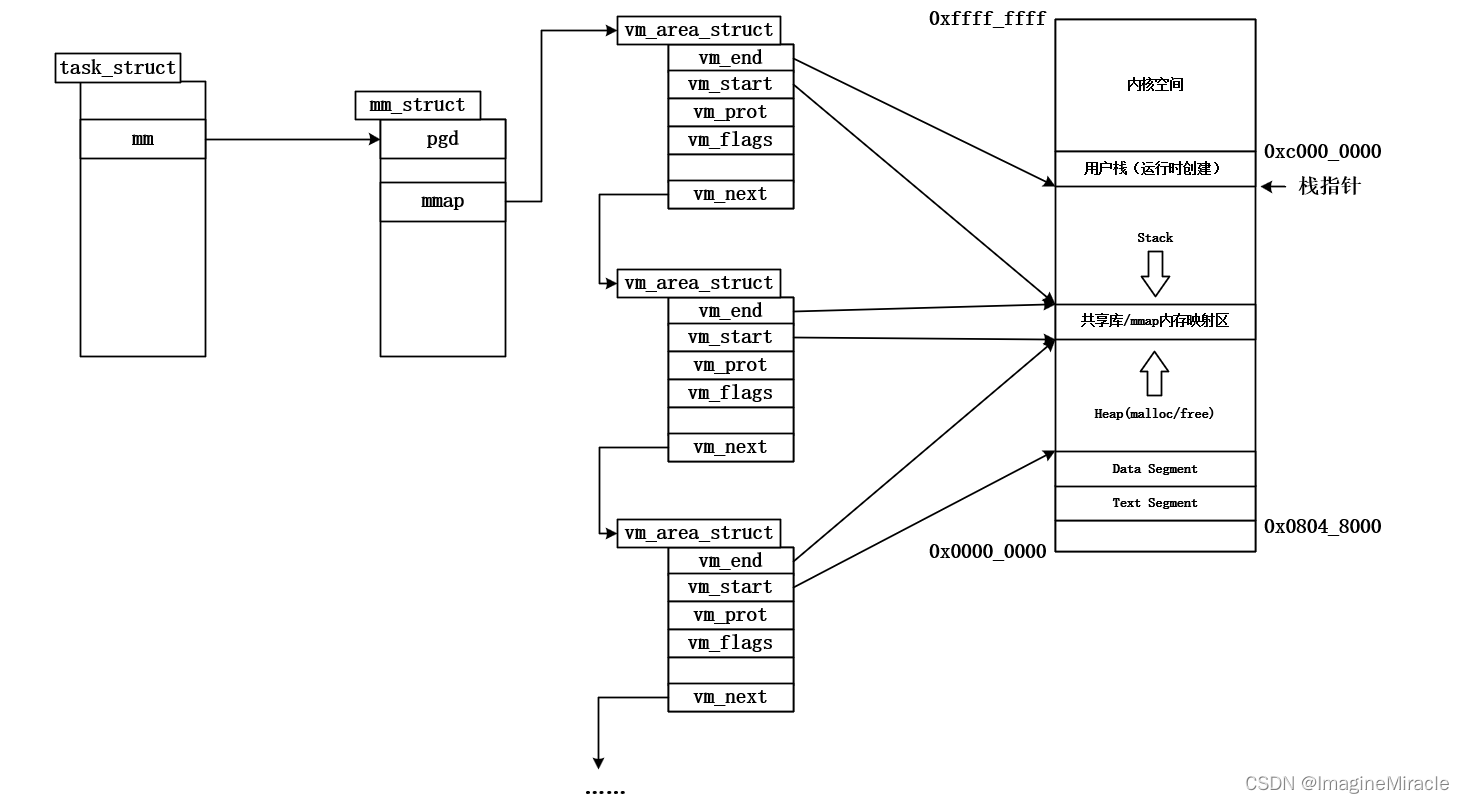
其中mmap用于指向描述进程虚拟内存的结构体链表头vm_area_struct。struct vm_area_struct,内核中使用该结构体管理虚拟内存。该结构体将虚拟内存划分为多个内存区,如数据段内存区、代码段内存区等。其描述的是一段连续的、具有相同访问属性的虚存空间,该虚存空间的大小为物理内存页面的整数倍。
2. mmap()函数的系统调用关系
x86架构下的mmap()系统调用表如下:
## arch/x86/entry/syscalls/syscall_32.tbl 32位系统下的mmap系统调用
90 i386 mmap sys_old_mmap compat_sys_ia32_mmap
91 i386 munmap sys_munmap
192 i386 mmap2 sys_mmap_pgoff
## arch/x86/entry/syscalls/syscall_64.tbl 64位系统下的mmap系统调用
9 common mmap sys_mmap
10 common mprotect sys_mprotect
11 common munmap sys_munmap
下面涉及到Linux内核的系统调用SYSCALL的原理,这再后面会专门发布一篇讲解内核中系统调用的实现。现在暂时不清楚的读者可以直接认为sys_mmap() 与 SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len, unsigned long, prot, unsigned long, flags, unsigned long, fd, unsigned long, off)这两个函数是等价的即可。
64位下mmap()即相关函数定义如下:
sys_mmap() == SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len, unsigned long, prot, unsigned long, flags, unsigned long, fd, unsigned long, off)
sys_mmap_pgoff() == ksys_mmap_pgoff() == SYSCALL_DEFINE6(mmap_pgoff,
//# mm/mmap.c ##------## sys_mmap_pgoff() == SYSCALL_DEFINE6(mmap_pgoff,
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
return ksys_mmap_pgoff(addr, len, prot, flags, fd, pgoff);
}
//# arch/x86/kernel/sys_x86_64.c ##------## sys_mmap == SYSCALL_DEFINE6(mmap
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
if (off & ~PAGE_MASK)
return -EINVAL;
return ksys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
}
64位mmap()函数的调用流程如下:
sys_mmap()
->SYSCALL_DEFINE6() //# arch/x86/kernel/sys_x86_64.c
->ksys_mmap_pgoff() //# mm/mmap.c
->vm_mmap_pgoff() //# mm/util.c
->do_mmap() //# mm/mmap.c
->get_unmmap_area()
->mmap_region()
->call_mmap()
3. do_mmap()函数分析
3.1. do_mmap()的主要流程
mmap()系统调用,主要执行到内核提供的do_mmap()中的mmap_region()函数,mmap_region()根据用户态程序的参数,将返回一个用于描述一段可用进程虚拟地址空间的VMA,再调用call_mmap()执行对应设备注册的mmap()函数实现,最终将映射的VMA插入到进程空间的红黑树中(mm_struct)。
//# mm/mmap.c ##------## do_mmap()
/*
* The caller must write-lock current->mm->mmap_lock.
*/
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
vm_flags_t vm_flags;
int pkey = 0;
struct timespec time_start, time_end; // +++Alter by wxn
*populate = 0;
if (!len)
return -EINVAL;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && path_noexec(&file->f_path)))
prot |= PROT_EXEC;
/* force arch specific MAP_FIXED handling in get_unmapped_area */
if (flags & MAP_FIXED_NOREPLACE)
flags |= MAP_FIXED;
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (IS_ERR_VALUE(addr))
return addr;
if (flags & MAP_FIXED_NOREPLACE) {
if (find_vma_intersection(mm, addr, addr + len))
return -EEXIST;
}
if (prot == PROT_EXEC) {
pkey = execute_only_pkey(mm);
if (pkey < 0)
pkey = 0;
}
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags = calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
if (mlock_future_check(mm, vm_flags, len))
return -EAGAIN;
if (file) {
struct inode *inode = file_inode(file);
unsigned long flags_mask;
if (!file_mmap_ok(file, inode, pgoff, len))
return -EOVERFLOW;
flags_mask = LEGACY_MAP_MASK | file->f_op->mmap_supported_flags;
switch (flags & MAP_TYPE) {
case MAP_SHARED:
/*
* Force use of MAP_SHARED_VALIDATE with non-legacy
* flags. E.g. MAP_SYNC is dangerous to use with
* MAP_SHARED as you don't know which consistency model
* you will get. We silently ignore unsupported flags
* with MAP_SHARED to preserve backward compatibility.
*/
flags &= LEGACY_MAP_MASK;
fallthrough;
case MAP_SHARED_VALIDATE:
if (flags & ~flags_mask)
return -EOPNOTSUPP;
if (prot & PROT_WRITE) {
if (!(file->f_mode & FMODE_WRITE))
return -EACCES;
if (IS_SWAPFILE(file->f_mapping->host))
return -ETXTBSY;
}
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
fallthrough;
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (path_noexec(&file->f_path)) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op->mmap)
return -ENODEV;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
get_current_time_im(time_start); // +++Alter by wxn
addr = mmap_region(file, addr, len, vm_flags, pgoff, uf); // 根据用户参数返回一个描述一段进程虚拟地址空间的VMA(vritual memory address)
get_current_time_im(time_end); // +++Alter by wxn
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
printk(KERN_NOTICE "use time[mmap_region]: %d ns\n", used_time_ns_im(time_start, time_end)); // +++Alter by wxn
return addr;
}
3.2. 返回一段进程虚拟空间函数——mmap_region()
//# mm/mmap.c ##------## mmap_region() // 根据用户参数,分配或找到一段可用的进程虚拟地址空间VMA,并插入到进程空间的红黑树中
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev, *merge;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
/* Check against address space limit. */
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) {
unsigned long nr_pages;
/*
* MAP_FIXED may remove pages of mappings that intersects with
* requested mapping. Account for the pages it would unmap.
*/
nr_pages = count_vma_pages_range(mm, addr, addr + len);
if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}
/* Clear old maps, set up prev, rb_link, rb_parent, and uf */
if (munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf))
return -ENOMEM;
/*
* Private writable mapping: check memory availability
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = vm_area_alloc(mm);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
if (file) {
if (vm_flags & VM_SHARED) {
error = mapping_map_writable(file->f_mapping);
if (error)
goto free_vma;
}
vma->vm_file = get_file(file);
error = call_mmap(file, vma); // 真正发生内存映射的地方,调用dax文件系统中具体设备实现的mmap函数
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);
addr = vma->vm_start;
/* If vm_flags changed after call_mmap(), we should try merge vma again
* as we may succeed this time.
*/
if (unlikely(vm_flags != vma->vm_flags && prev)) {
merge = vma_merge(mm, prev, vma->vm_start, vma->vm_end, vma->vm_flags,
NULL, vma->vm_file, vma->vm_pgoff, NULL, NULL_VM_UFFD_CTX);
if (merge) {
/* ->mmap() can change vma->vm_file and fput the original file. So
* fput the vma->vm_file here or we would add an extra fput for file
* and cause general protection fault ultimately.
*/
fput(vma->vm_file);
vm_area_free(vma);
vma = merge;
/* Update vm_flags to pick up the change. */
vm_flags = vma->vm_flags;
goto unmap_writable;
}
}
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
} else {
vma_set_anonymous(vma);
}
/* Allow architectures to sanity-check the vm_flags */
if (!arch_validate_flags(vma->vm_flags)) {
error = -EINVAL;
if (file)
goto unmap_and_free_vma;
else
goto free_vma;
}
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
unmap_writable:
if (file && vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
file = vma->vm_file;
out:
perf_event_mmap(vma);
vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if ((vm_flags & VM_SPECIAL) || vma_is_dax(vma) ||
is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm))
vma->vm_flags &= VM_LOCKED_CLEAR_MASK;
else
mm->locked_vm += (len >> PAGE_SHIFT);
}
if (file)
uprobe_mmap(vma);
/*
* New (or expanded) vma always get soft dirty status.
* Otherwise user-space soft-dirty page tracker won't
* be able to distinguish situation when vma area unmapped,
* then new mapped in-place (which must be aimed as
* a completely new data area).
*/
vma->vm_flags |= VM_SOFTDIRTY;
vma_set_page_prot(vma);
return addr;
unmap_and_free_vma:
fput(vma->vm_file);
vma->vm_file = NULL;
/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
free_vma:
vm_area_free(vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}
3.3. mmap()通用流程结束——call_mmap()
call_mmap()根据该设备在文件系统中实现的mmap()函数,将实际物理内存映射到由mmap_region()中产生的vma上,最后将该段vma添加到进程的mm_struct
//# include/linux/fs.h ##------## call_mmap()
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}
4. dax设备的mmap
4.1. dax_mmap内存映射流程即初次访问页映射过程
当用户程序初次访问映射地址/文件时,内存管理单元(Memory Managment Unit)检测到页表项(Page Table Entry, PTE)为空,此时将触发14号故障,即页故障(Page Fault),内核将会得到该故障并处理,开始执行请求调页(Demand Paging)。
此处具体分析dax设备的struct vm_operations_struct,下面为dax设备的通用mmap函数实现,其中主要为dax设备获取具体的虚拟内存操作函数集,即vma->vm_ops = &dax_vm_ops;,当发生页故障时,此时的异常处理例程(Exception Handler)将会调用此处的struct vm_operations_struct dax_vm_ops中相应的页故障处理函数。
//# drivers/dax/device.c ##------## dax_mmap()
static const struct file_operations dax_fops = {
.llseek = noop_llseek,
.owner = THIS_MODULE,
.open = dax_open,
.release = dax_release,
.get_unmapped_area = dax_get_unmapped_area,
.mmap = dax_mmap, // dax设备的mmap函数
.mmap_supported_flags = MAP_SYNC,
};
static int dax_mmap(struct file *filp, struct vm_area_struct *vma)
{
struct dev_dax *dev_dax = filp->private_data;
int rc, id;
dev_dbg(&dev_dax->dev, "trace\n");
/*
* We lock to check dax_dev liveness and will re-check at
* fault time.
*/
id = dax_read_lock();
rc = check_vma(dev_dax, vma, __func__);
dax_read_unlock(id);
if (rc)
return rc;
vma->vm_ops = &dax_vm_ops;
vma->vm_flags |= VM_HUGEPAGE;
return 0;
}
static const struct vm_operations_struct dax_vm_ops = {
.fault = dev_dax_fault,
.huge_fault = dev_dax_huge_fault,
.may_split = dev_dax_may_split,
.pagesize = dev_dax_pagesize,
};
4.2. dax设备的请求调页
发生请求调页时,dax_dev中的主要处理函数为dev_dax_fault()
//# drivers/dax/device.c ##------## dax_dax_fault()
static vm_fault_t dev_dax_fault(struct vm_fault *vmf)
{
return dev_dax_huge_fault(vmf, PE_SIZE_PTE);
}
dev_dax_fault()函数只调用了一个函数dev_dax_huge_fault()
//# drivers/dax/device.c ##------## dev_dax_huge_fault()
static vm_fault_t dev_dax_huge_fault(struct vm_fault *vmf,
enum page_entry_size pe_size)
{
struct file *filp = vmf->vma->vm_file;
unsigned long fault_size;
vm_fault_t rc = VM_FAULT_SIGBUS;
int id;
pfn_t pfn;
struct dev_dax *dev_dax = filp->private_data;
dev_dbg(&dev_dax->dev, "%s: %s (%#lx - %#lx) size = %d\n", current->comm,
(vmf->flags & FAULT_FLAG_WRITE) ? "write" : "read",
vmf->vma->vm_start, vmf->vma->vm_end, pe_size);
id = dax_read_lock();
switch (pe_size) {
case PE_SIZE_PTE: // PE_SIZE_PTE = 0
fault_size = PAGE_SIZE; // PAGE_SIZE = 4KB
rc = __dev_dax_pte_fault(dev_dax, vmf, &pfn);
break;
case PE_SIZE_PMD: // PE_SIZE_PMD = 1
fault_size = PMD_SIZE; // PMD_SIZE = 1MB
rc = __dev_dax_pmd_fault(dev_dax, vmf, &pfn);
break;
case PE_SIZE_PUD: // PE_SIZE_PUD = 2
fault_size = PUD_SIZE; // PUD_SIZE = 1GB
rc = __dev_dax_pud_fault(dev_dax, vmf, &pfn);
break;
default:
rc = VM_FAULT_SIGBUS;
}
if (rc == VM_FAULT_NOPAGE) {
unsigned long i;
pgoff_t pgoff;
/*
* In the device-dax case the only possibility for a
* VM_FAULT_NOPAGE result is when device-dax capacity is
* mapped. No need to consider the zero page, or racing
* conflicting mappings.
*/
pgoff = linear_page_index(vmf->vma, vmf->address
& ~(fault_size - 1));
for (i = 0; i < fault_size / PAGE_SIZE; i++) {
struct page *page;
page = pfn_to_page(pfn_t_to_pfn(pfn) + i);
if (page->mapping)
continue;
page->mapping = filp->f_mapping;
page->index = pgoff + i;
}
}
dax_read_unlock(id);
return rc;
}
常规使用的page_size应为4KB,这里的应该主要调用的函数为__dev_dax_pte_fault(),该函数主要通过dax_pgoff_to_phys()得到物理内存信息,phys_to_pfn_t()获取phys的PM页的物理页号(Physical Pgae Number, pfn)到pfn中,最后调用vmf_insert_mixed()将获取的pfn填写到对应虚拟页的PTE中。到此进程中的页表项PTE就有了对应物理内存映射到进程空间的虚拟内存索引,完成mmap过程。
//# drivers/dax/device.c ##------## __dev_dax_pte_fault()
static vm_fault_t __dev_dax_pte_fault(struct dev_dax *dev_dax,
struct vm_fault *vmf, pfn_t *pfn)
{
struct device *dev = &dev_dax->dev;
phys_addr_t phys;
unsigned int fault_size = PAGE_SIZE;
if (check_vma(dev_dax, vmf->vma, __func__))
return VM_FAULT_SIGBUS;
if (dev_dax->align > PAGE_SIZE) {
dev_dbg(dev, "alignment (%#x) > fault size (%#x)\n",
dev_dax->align, fault_size);
return VM_FAULT_SIGBUS;
}
if (fault_size != dev_dax->align)
return VM_FAULT_SIGBUS;
phys = dax_pgoff_to_phys(dev_dax, vmf->pgoff, PAGE_SIZE);
if (phys == -1) {
dev_dbg(dev, "pgoff_to_phys(%#lx) failed\n", vmf->pgoff);
return VM_FAULT_SIGBUS;
}
*pfn = phys_to_pfn_t(phys, PFN_DEV|PFN_MAP); // 获取phys的PM页的物理页号(Physical Pgae Number, pfn)到pfn中
return vmf_insert_mixed(vmf->vma, vmf->address, *pfn); // 将pfn填写到对应虚拟页的PTE中
}
//# drivers/dax/device.c ##------## dax_pgoff_to_phys()
__weak phys_addr_t dax_pgoff_to_phys(struct dev_dax *dev_dax, pgoff_t pgoff,
unsigned long size)
{
int i;
for (i = 0; i < dev_dax->nr_range; i++) {
struct dev_dax_range *dax_range = &dev_dax->ranges[i];
struct range *range = &dax_range->range;
unsigned long long pgoff_end;
phys_addr_t phys;
pgoff_end = dax_range->pgoff + PHYS_PFN(range_len(range)) - 1;
if (pgoff < dax_range->pgoff || pgoff > pgoff_end)
continue;
phys = PFN_PHYS(pgoff - dax_range->pgoff) + range->start;
if (phys + size - 1 <= range->end)
return phys;
break;
}
return -1;
}
//# include/linux/pfn_t.h ##------## phys_to_pfn_t()
static inline pfn_t phys_to_pfn_t(phys_addr_t addr, u64 flags)
{
return __pfn_to_pfn_t(addr >> PAGE_SHIFT, flags);
}
static inline pfn_t __pfn_to_pfn_t(unsigned long pfn, u64 flags)
{
pfn_t pfn_t = {
.val = pfn | (flags & PFN_FLAGS_MASK), };
return pfn_t;
}
觉得这篇文章对你有帮助的话,就留下一个赞吧 ^v^*
请尊重作者,转载还请注明出处!感谢配合~
[作者]: Imagine Miracle
[版权]: 本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
[本文链接]: https://blog.csdn.net/qq_36393978/article/details/124243364