
目录

1.CRUD
CRUD就是增删改查的几个sql语句的首字母即create(创建)、查询(retrieve)、更新(update)、删除(delete)。
2.增加数据
2.1创建数据
创建一个数据库,语法为:create database 数据库名; 如创建一个名为test的数据库:
mysql> create database test;
Query OK, 1 row affected (0.00 sec)当最后一行出现了Query Ok字段时,代表着这个数据库的创建成功。
创建一个表,语法为:create table 表名; 如创建一个名为student的表:
mysql> use test;
Database changed
mysql> create table student(
-> id int,
-> name varchar(20),
-> price decimal
-> );
Query OK, 0 rows affected (0.02 sec)我们在创建表的时,得先使用一个数据库。创建表成功后,最后一行语句会提示Query Ok..语句。
2.2插入数据
2.2.1单行插入
当我们创建表后,表内是没有信息的因此我们得插入一些数据来存储。我们使用 insert into 表名 values(字段1,字段2,....); 来插入一些数据,注意插入的数据应当与表的结构相同。我们来往student表中插入一行信息:
mysql> insert into student values(1,'张三',20);
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'name' at row 1我们可以看到,出现了ERROR(错误)。代表着张三这个字符串没有引入utf-8格式,因此我们在创建数据库时,得先声明utf8格式才能使数据的增添不发生错误,如下所示:
mysql> create database test charset utf8;
Query OK, 1 row affected (0.00 sec)这样我们在创建数据库的时候同时申明了字符集为utf-8类型,这样我们在创建表并新添数据的时候就不会出现错误。声明字符集语法:charset 字符集类型。
mysql> use test;
Database changed
mysql> create table student(
-> id int,
-> name varchar(20),
-> price decimal
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values(1,'张三',20);
Query OK, 1 row affected (0.00 sec)我们可以看到最后插入一行数据,提示Query OK了,这是单行插入操作,下面我们来看多行插入。
2.2.2多行插入
多行插入语法为:insert into 表名(类型1,类型2,类型3,...) values (字段1,字段2,字段3,...),(字段1,字段2,字段3,...);
mysql> insert into student(id,name,price) values
-> (2,'李四',24),
-> (3,'王五',30);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0以上代码为student又增添了两行数据,因此现在的student表中有三行数据。我们可以使用select * from student; 全列查询查看student表结构。
mysql> select * from student;
+------+------+-------+
| id | name | price |
+------+------+-------+
| 1 | 张三 | 20 |
| 2 | 李四 | 24 |
| 3 | 王五 | 30 |
+------+------+-------+
3 rows in set (0.00 sec)当然,以上的多行插入我把id、name、price这三个字段都增添了。你也可以任意增添这三个字段中的任意数量,如只增添id、name这两个字段等等。
3.查找数据
3.1全列查询
全列查询,即查询整个表里面的数据。语法格式为:select * from 表名; 其中*是一个通配符代表着所有的数据。如查询上文中student表中的所有数据:
mysql> use test;
Database changed
mysql> select * from student;
+------+------+-------+
| id | name | price |
+------+------+-------+
| 1 | 张三 | 20 |
| 2 | 李四 | 24 |
| 3 | 王五 | 30 |
+------+------+-------+
3 rows in set (0.00 sec)我们可以看到所有的数据都显示出来了 ,这就是全列查询。但注意,在我们实际开发过程中*号不得随意使用。当我们使用*号查询一个庞大的数据表或者其他类型的数据时,所有的内存都被占用,此时数据库就不会正常的更新或增加数据这样是非常危险的!因此,我们在自己电脑上尝试即可,因为我们的数据库是较小的大概率不会造成数据丢失这种风险。
3.2指定列查询
在上面我们知道了*号是非常的危险,那么指定列查询就比较安全了,我们可以直接查询某一列的数据,这样内存的占用量就很低,指定列查询语法为:select 字段1,字段2 from 表名; 如我要查找student表中的id和name这两列数据:
mysql> select id,name from student;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+------+
3 rows in set (0.00 sec)我们可以看到, 指定列查询非常的“人性化”,我们想要查询那一列就查询那一列数据,这样对内存的占用量也会很低,推荐这种查询方式。
3.3查询字段为表达式
首先,我们创建一个成绩表,并且插入两行数据:
mysql> create table grades(
-> chinese int,
-> math int,
-> english int);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into grades(chinese,math,english) values
-> (78,98,59),
-> (76,99,35);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0以上就很好的创建了一个成绩表,并且这个表有两行数据。那么创建表和插入表信息在上文中已经讲解到了,不熟练的伙伴可以再去看看。
3.3.1表达式不包含字段
表达式不包含字段的情况意为这个表达式中的任何信息不为表中的任何字段,如下标中查询一个名为10的字段:
mysql> select chinese,math,english,10 from grades;
+---------+------+---------+----+
| chinese | math | english | 10 |
+---------+------+---------+----+
| 78 | 98 | 59 | 10 |
| 76 | 99 | 35 | 10 |
+---------+------+---------+----+
2 rows in set (0.00 sec)我们可以看到,这个表达式列数都为10。这样的查询就是表达式不包含字段的一个查询,注意此处的字段是表中的每一列的列名。
3.3.2表达式包含一个字段
表达式中包含一个字段的情况,通常我们想使表中的某一列数据发生改变时会使用该操作。如我想使grades表中每个人的英语成绩增加10分:
mysql> select chinese,math,english+10 from grades;
+---------+------+------------+
| chinese | math | english+10 |
+---------+------+------------+
| 78 | 98 | 69 |
| 76 | 99 | 45 |
+---------+------+------------+
2 rows in set (0.00 sec)3.3.3表达式包含多个字段
表达式包含多个字段,一般我们在求一个表中的所有数据的总和时会使用该查询方式。如我要求grades表中所有数据的总和:
mysql> select chinese,math,english,chinese+math+english from grades;
+---------+------+---------+----------------------+
| chinese | math | english | chinese+math+english |
+---------+------+---------+----------------------+
| 78 | 98 | 59 | 235 |
| 76 | 99 | 35 | 210 |
+---------+------+---------+----------------------+
2 rows in set (0.00 sec)我们可以看到,这样的查询的非常方便的唯一的缺点就是,列名太长了。因此我们又有一个sql语句可以将这个冗长的列名给起一个别名,来简化一下。具体讲解请看下方:
3.4起别名
起别名我们所用的语法为 表达式或列名 as 别名;如我把上方冗长的chinese+math+english起别名为sum:
mysql> select chinese,math,english,chinese+math+english as sum from grades;
+---------+------+---------+------+
| chinese | math | english | sum |
+---------+------+---------+------+
| 78 | 98 | 59 | 235 |
| 76 | 99 | 35 | 210 |
+---------+------+---------+------+
2 rows in set (0.00 sec)当然也可以给单独的一列起别名:
mysql> select chinese as '中文' from grades;
+------+
| 中文 |
+------+
| 78 |
| 76 |
+------+
2 rows in set (0.00 sec)这样,我们在查询数据的时候看一些字段就不会太别扭,这就是起别名操作。 注意,as可以省略但为了代码的可读性建议加上!
3.5distinct(去重)
创建一个students表:
mysql> create table students(
-> id int,
-> name varchar(20),
-> chinese int,
-> math int,
-> english int);
Query OK, 0 rows affected (0.02 sec)插入四行数据:
mysql> insert into students(id,name,chinese,math,english) values
-> (1,'孙悟空',69,89,47),
-> (2,'沙悟净',77,99,60),
-> (3,'猪八戒',80,88,50),
-> (4,'白龙马',69,77,88);
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0我们发现孙悟空和白龙马的语文成绩相同了,当我要显示语文成绩并且每个成绩各不相同时可以使用distinct来去重:
mysql> select distinct chinese from students;
+---------+
| chinese |
+---------+
| 69 |
| 77 |
| 80 |
+---------+
3 rows in set (0.01 sec)我们可以看到,69只显示了一次,这就是distinct在表中的作用:去掉重复的数据。需要注意的是,distinct只是在我们显示的时候去掉了重复的数据,在实际的数据库中被去重的数据是未发生改变的!
3.6order by(排序)
3.6.1某字段默认排序
我们拿students这个表来进行操作,如我要按照英语成绩来进行默认排序:
mysql> select id,name,chinese,math,english from students order by english;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 1 | 孙悟空 | 69 | 89 | 47 |
| 3 | 猪八戒 | 80 | 88 | 50 |
| 2 | 沙悟净 | 77 | 97 | 60 |
| 4 | 白龙马 | 69 | 77 | 88 |
+------+--------+---------+------+---------+
4 rows in set (0.00 sec)通过观察,我们发现默认排序是按照升序进行排序的。那么默认排序的语法为:order by 字段名;语当然你也可以加上asc这个字段来强调你进行的排序是升序的,增强代码的可读性。
3.6.2某字段降序排序
例如按照english成绩降序进行排序:
mysql> select id,name,chinese,math,english from students order by english desc;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 4 | 白龙马 | 69 | 77 | 88 |
| 2 | 沙悟净 | 77 | 97 | 60 |
| 3 | 猪八戒 | 80 | 88 | 50 |
| 1 | 孙悟空 | 69 | 89 | 47 |
+------+--------+---------+------+---------+
4 rows in set (0.00 sec)观察发现,如果要进行降序排序的话,我们只需要在字段名后面加上desc关键字即可,因此降序排序语法为:order by 字段名 desc;
3.6.3使用表达式及别名排序
使用表达式进行查询,查询语数外三门成绩的总和按照降序进行排序:
mysql> select id,name,chinese + math + english as sum from students order by chinese + math + english desc;
+------+--------+------+
| id | name | sum |
+------+--------+------+
| 2 | 沙悟净 | 234 |
| 4 | 白龙马 | 234 |
| 3 | 猪八戒 | 218 |
| 1 | 孙悟空 | 205 |
+------+--------+------+
4 rows in set (0.00 sec)使用别名进行查询,查询语数外三门成绩的总和按照降序进行排序:
mysql> select id,name,chinese + math + english as sum from students order by sum desc;
+------+--------+------+
| id | name | sum |
+------+--------+------+
| 2 | 沙悟净 | 234 |
| 4 | 白龙马 | 234 |
| 3 | 猪八戒 | 218 |
| 1 | 孙悟空 | 205 |
+------+--------+------+
4 rows in set (0.00 sec)我们发现上述两个查询的结果是一样的,因此大家如果以后有类型的操作可以使用其中任意一种方式进行查询。
3.6.4对多个字段进行排序
例如,按照语文的降序,数学的升序进行查询:
mysql> select id,name,chinese,math,english from students order by chinese desc,math;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 3 | 猪八戒 | 80 | 88 | 50 |
| 2 | 沙悟净 | 77 | 97 | 60 |
| 4 | 白龙马 | 69 | 77 | 88 |
| 1 | 孙悟空 | 69 | 89 | 47 |
+------+--------+---------+------+---------+
4 rows in set (0.00 sec)这样的操作,适合混合排序,具体功能具体操作 。大家按照自己的需求选择自己的sql语句。
3.7where(条件查询)
条件查询使用的语句是where,它的语法格式为:select 字段1,字段2,... where 查询条件;
3.7.1比较运算符
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于就,小于等于 |
| = | 等于,NULL 不安全,例如NULL = NULL 的结果是NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=,<> | 不等于 |
| BETWEEN .. ADN .. | 在..和..之间,前闭后闭 |
| IN() | 在 |
| IS NULL | 是空 |
| IS NOT NULL | 不是空 |
| LIKE | 模糊查询,当LIKE后面为%号时代表0个或多个字段,当LIKE后面为_时根据_的个数来表示字段。 |
查找英语成绩不及格的学生:
mysql> select id,name,chinese,math,english from students where english<60;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 1 | 孙悟空 | 69 | 89 | 47 |
| 3 | 猪八戒 | 80 | 88 | 50 |
+------+--------+---------+------+---------+
2 rows in set (0.00 sec)查找英语成绩在60和90之间的学生:
mysql> select id,name from students where english between 60 and 90;
+------+--------+
| id | name |
+------+--------+
| 2 | 沙悟净 |
| 4 | 白龙马 |
+------+--------+
2 rows in set (0.01 sec)查找姓孙的同学:
mysql> select id,name from students where name like '孙%';
+------+--------+
| id | name |
+------+--------+
| 1 | 孙悟空 |
+------+--------+
1 row in set (0.00 sec)查找姓孙且姓名长度为2的学生:
mysql> select id,name from students where name like'孙_';
Empty set (0.00 sec)以上代码,最后显示Empty代表没有符合这个字段的学生。那么上述表格中有许多操作都是差不太多的,因此博主在这里就举三个例子,大家可以对照表格自行进行测试。
3.7.2逻辑操作符
| 运算符 | 说明 |
|---|---|
| AND | 多个条件都必须为TRUE,结果才为TRUE |
| OR | 任意一个条件为TRUE,结果为TRUE |
| NOT | 条件为TRUE,结果为FALSE |
查询语文成绩>=80且英语成绩>=80的学生:
mysql> select id,name from students where chinese>= 80 and math>=80;
+------+--------+
| id | name |
+------+--------+
| 3 | 猪八戒 |
+------+--------+
1 row in set (0.00 sec)查询语文成绩>80或则英语成绩<60的学生:
mysql> select id,name from students where chinese>80 or english<60;
+------+--------+
| id | name |
+------+--------+
| 1 | 孙悟空 |
| 3 | 猪八戒 |
+------+--------+
2 rows in set (0.00 sec)查询英语成绩不及格的学生:
mysql> select id,name from students where not english>=60;
+------+--------+
| id | name |
+------+--------+
| 1 | 孙悟空 |
| 3 | 猪八戒 |
+------+--------+
2 rows in set (0.00 sec)我们可以看到,逻辑操作符进行查询与我们的C、Java中的&&、|| 这种操作符表达的效果是一致的,只不过MySQL中使用的是英文。
3.8limit(分页)
分页查询是按照规定查询相应的数据,这个规定是根据你的需求来决定的,也就是你想查询哪一页或者哪几行的数据。它的语法格式是在指定列查询基础上加上limit语句,有三种格式:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
查询students表的前三条记录中的id和name信息,我之间在最后面加上limit 3即可:
mysql> select id,name from students limit 3;
+------+--------+
| id | name |
+------+--------+
| 1 | 孙悟空 |
| 2 | 沙悟净 |
| 3 | 猪八戒 |
+------+--------+
3 rows in set (0.00 sec)也可以指定从第几行开始查询,如我要从students表的第3行查询,查询两行记录:
mysql> select id,name from students limit 2,2;
+------+--------+
| id | name |
+------+--------+
| 3 | 猪八戒 |
| 4 | 白龙马 |
+------+--------+
2 rows in set (0.00 sec)我们看到达到了我所想要的效果,因此指定行数的分页查询语法为:limit n,s;其中s为起始位置,n为行数。 但这种方式不够严谨,正确的应该是 limit n offset s;其中s也为起始位置,n为行数。注意,行数是按照0为第一条数据往后自增的跟数组的下标是一致的。
4.修改数据
修改数据,使用的sql语句为update。它的语法为:update 表名 set 修改值 where 条件;如将students表中的猪八戒英语成绩置为0:
mysql> update students set english = 0 where name = '猪八戒';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0我们再来通过全列查询查看students表的所有信息:

我们可以看到,猪八戒的英语成绩已经置为0了。当然,我们也可以通过表达式进行修改数据。如将猪八戒的英语成绩通过表达式增加100:
mysql> update students set english = english+100 where name = '猪八戒';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0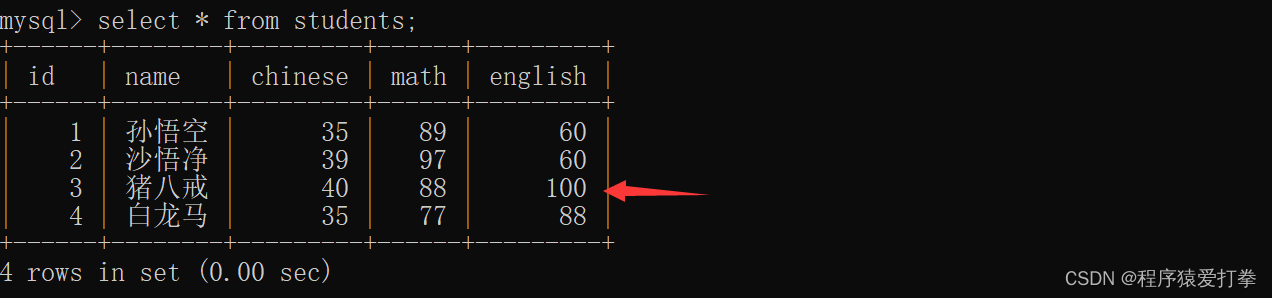
我们可以看到通过表达式进行修改也是可以的,但唯一要注意的是。如果我们要增加或者减少一个数据的话我们应该写成数据 = 数据+值,不能写成数据+ = 值同上述代码中的chinese = chinese + 100;
5.删除数据
删除数据使用的sql语句为delete,它的语法格式为:delete from 表名 where 删除目标;如将students表中的白龙马信息给删除掉:
mysql> delete from students where name = '白龙马';
Query OK, 1 row affected (0.00 sec)显示students表:

我们可以看到,students表已经剩下三条记录了。当然,我们也可以删除整张表的信息也是通过delete来删除:
Query OK, 3 rows affected (0.01 sec)
mysql> select * from students;
Empty set (0.00 sec)删除students整张表信息后,我们在使用全列查询显示为空。注意,delete删除表只是删除表中所有的数据并不删除表,而drop这个操作就比较危险了它把表以及表的数据全部都给删除了。因此我们在删库操作的时候一定要注意!
文章内容比较丰富,大家下来了一定要多加练习。只有实现了这些操作,我们才能更好的掌握这些知识点,另外在where条件查询中的比较操作符没有举到的例子大家也可以自行测试一番。本期博文到这里就结束了,感谢你的耐心阅读,如有收获还请点个小小的关注。
