随着微服务和分布式架构的引入,各类应用和基础组件形成了网状的分布式调用关系,这种复杂的调用关系就大大增加了问题定位、瓶颈分析、容量评估以及限流降级等稳定性保障工作的难度。正是这样的背景,催生了全链路追踪的解决方案。
这里的一个核心技术点就是 TraceID,当请求从接入层进来时,这个 TraceID 就要被创建出来;或者是通过 Nginx 插件方式创建放到 http 的 header 里面;或者是通过 RPC 服务化框架生成。然后在后续的请求中,这个字段会通过框架自动传递到下一个调用方,而不需要业务考虑如何处理这个核心字段。
有了这个 TraceID,我们就可以将一个完整的请求链路给串联起来了,这也是后面场景化应用的基础。下面我们就一起来看会有哪些具体的技术运营场景。
1、问题定位和排查
我们做全链路追踪系统,要解决的首要问题就是在纷繁复杂的服务调用关系中快速准确地定位问题。
常见的问题场景,主要有两类:瓶颈分析和异常错误定位。
常见的问题就是某某页面变慢了,或者某个服务突然出现大量超时告警,因为无论是页面也好,还是服务也好,在分布式环境中都会依赖后端大量的其它服务或基础部件,所以定位类似的问题,期望能有一个详细的调用关系呈现出来,这样我们就可以非常方便快速地判断瓶颈出现在什么地方。
比如下图的情况,就是某个页面变慢。我们根据 URL 查看某次调用的情况,就发现瓶颈是在 RateReadService 的 query 接口出现了严重阻塞。接下来,我们就可以根据详细的 IP 地址信息,到这台机器上或者监控系统上,进一步判断这个应用或者这台主机的异常状况是什么,可能是机器故障,也可能是应用运行故障等等。

通过上面的案例,我们可以看到,在应用了全链路跟踪的解决方案后,复杂调用关系下的问题定位就相对简单多了。
2、服务运行状态分析
上面的问题定位,主要还是针对单次请求或相对独立的场景进行的。更进一步,我们在采集了海量请求和调用关系数据后,还可以分析出更有价值的服务运行信息。比如以下几类信息。
1. 服务运行质量
一个应用对外可能提供 HTTP 服务,也可能提供 RPC 接口。针对这两类不同的接口,我们可以通过一段时间的数据收集形成服务接口运行状态的分析,也就是应用层的运行监控,常见的监控指标有 QPS、RT 和错误码,同时还可以跟之前的趋势进行对比。这样就可以对一个应用,以及对提供的服务运行情况有一个完整的视图。
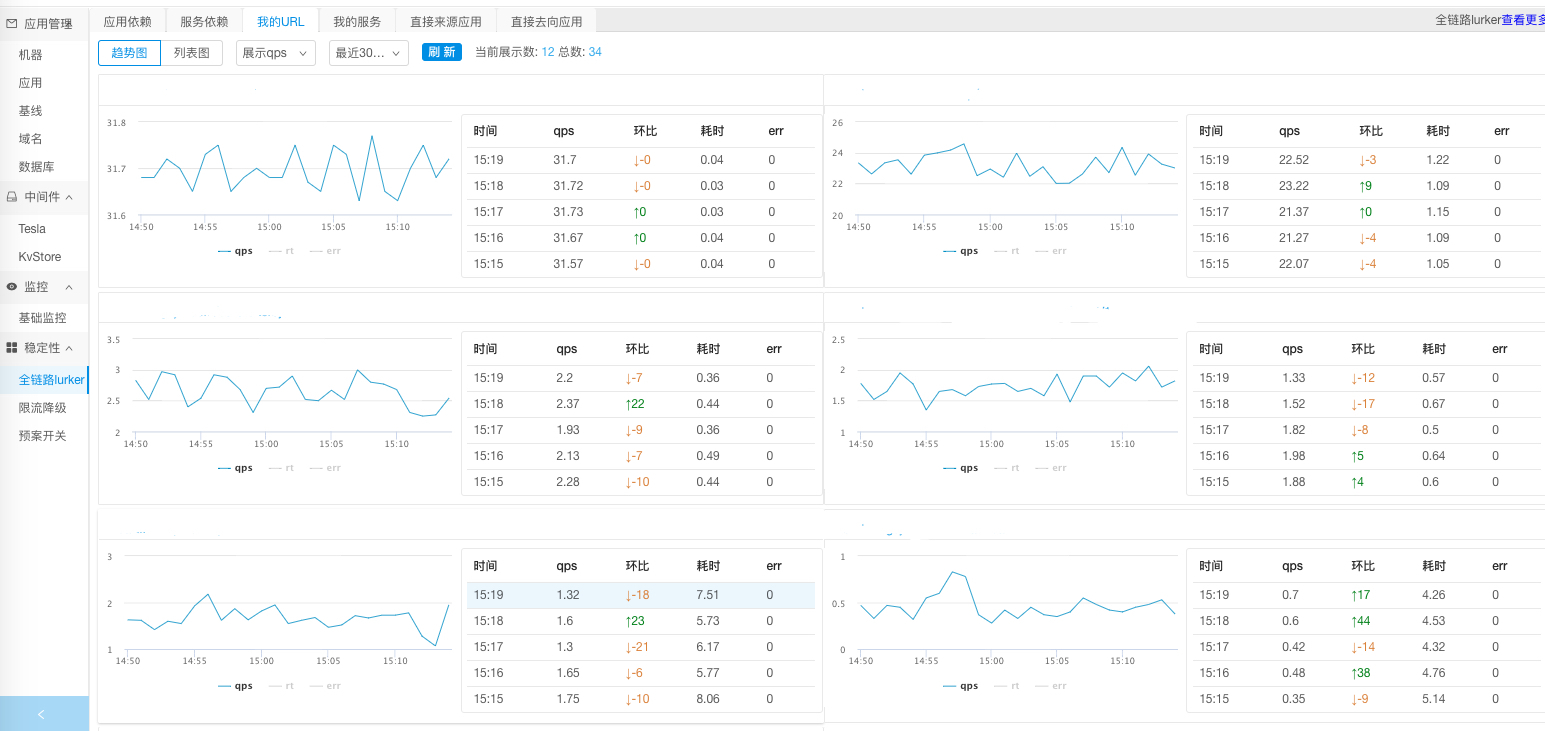
2. 应用和服务依赖
除了上述单个应用的运行状态,我们还可以根据调用链的分析,统计出应用与应用之间,服务与服务之间的依赖关系及依赖比例,如下图所示。
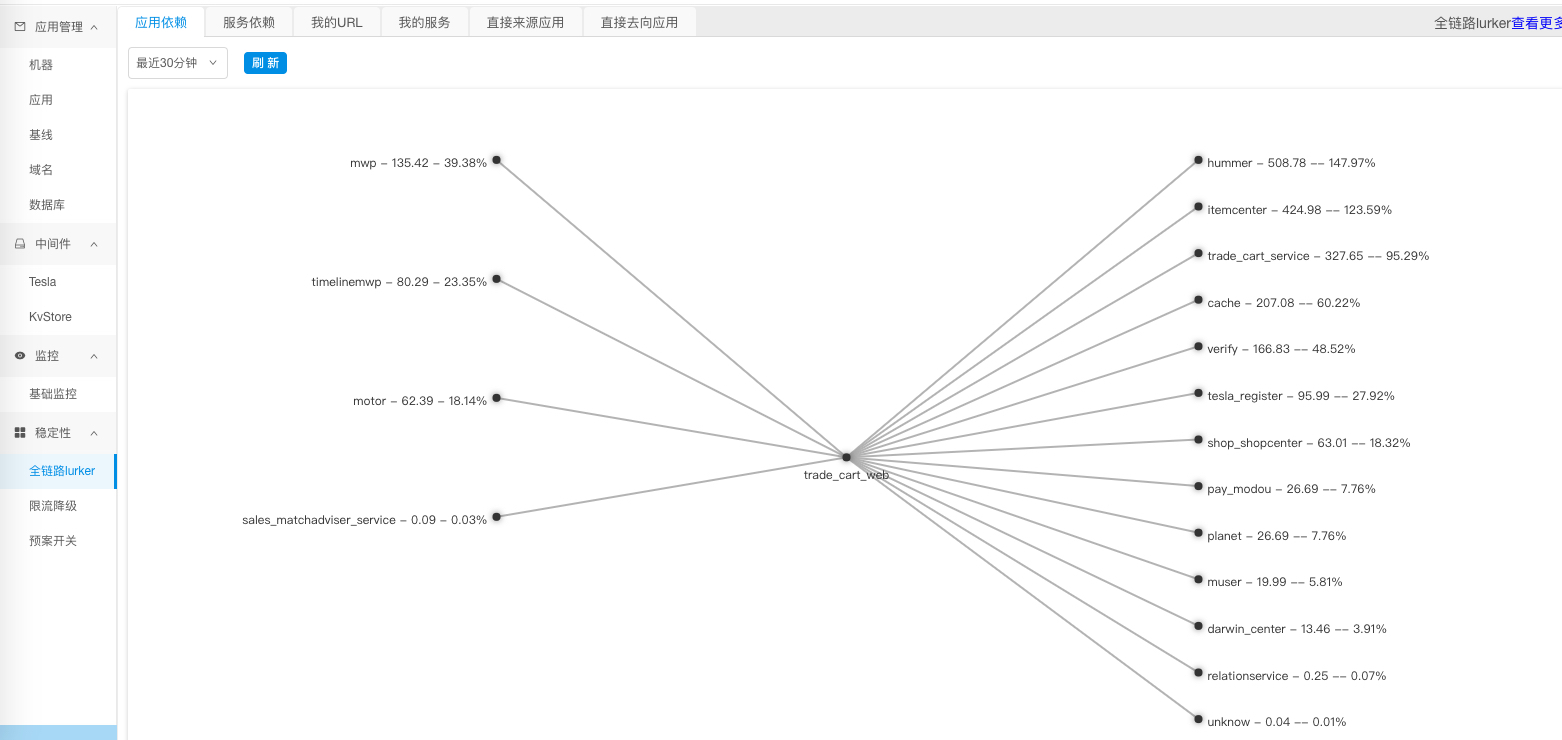
我们可以根据来源依赖和比例评估单链路的扩容准备;同时根据去向依赖进行流量拆分,为下游应用的扩容提供依据,因为这个依赖比例完全来源于线上真实调用,所以能够反映出真实的业务访问模型。
同时,因为我们的业务场景和需求在不断变化,应用和服务间的调用关系和依赖关系也是在不断变化中的,这就需要我们不断地分析和调整强弱依赖关系,同时也要关注各种调用间的合理性,这个过程中就会有大量的可优化的工作。
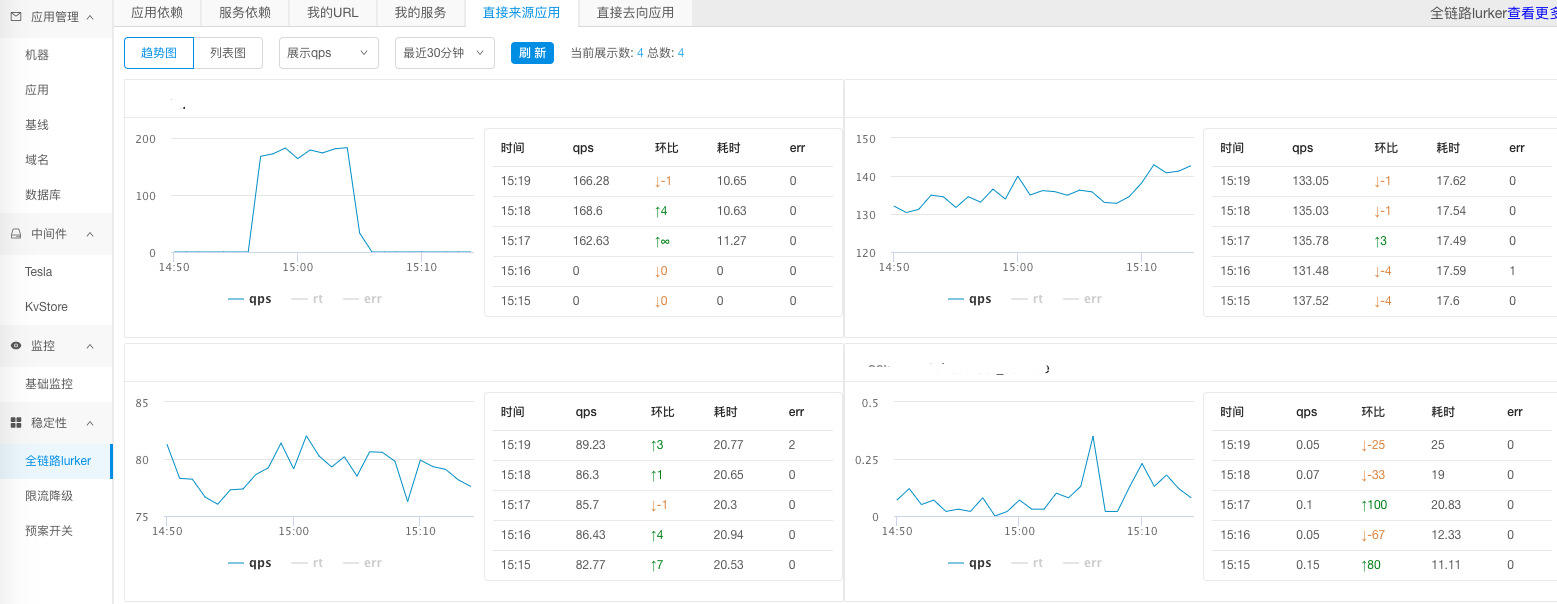
3. 依赖关系的服务质量
也会关注被依赖的应用或服务的实时运行状态和质量,这样就可以看到应用间实时的调用状态。是不是有的应用调用 QPS 突然增加了,或者 RT 突然暴涨,通过这个依赖关系就可以快速确认。
3、业务全息
业务全息就是全链路追踪系统与业务信息的关联。全链路追踪系统的应用更多的还是在技术层面,比如定位“应用或服务”的问题,应用或服务间的依赖关系等等。
但是现实中,我们也会遇到大量的业务链路分析的场景,比如可能会有针对某个订单在不同阶段的状态等。假设一个情况是用户投诉,他的订单没有享受到满 100 元包邮的优惠,这时我们就要去查找用户从商品浏览、加购物车到下单整个环节的信息,来判断问题出在哪儿。其实,这个场景和一个请求的全链路追踪非常相似。
所以,为了能够在业务上也采用类似的思路,可以将请求链路上的唯一 TraceID 与业务上的订单 ID、用户 ID、商品 ID 等信息进行关联,当出现业务问题需要排查时,就会根据对应的 ID 将一串业务链整个提取出来,然后进行问题确认。这就会极大地提升解决业务问题的效率。
全链路追踪系统在技术方案的广泛应用,提供了大量可分析处理的线上运行数据,从这些数据中,我们又能提炼出对线上稳定运行更有价值的信息。
此文章为4月Day10 学习笔记,内容来源于极客时间《赵成的运维体系管理课》,推荐该课程。