Towards Continual Knowledge Learning of Language Models
1 发展背景和要解决的问题是什么?
- QA is a complex problem that requires a wide variety of reasoning skills. In addition to basic reading comprehension (RC), models must connect multiple pieces of information.
多跳问答是个复杂的问题,需要广泛的推理技能。除了基本的阅读理解(RC)之外,模型还必须连接多个信息片段。 - However, even though questions in multihop datasets often cover a broad range of interesting reasoning patterns, the datasets are dominated by only a few patterns, which is what trained models naturally focus on.
但是,尽管多跳数据集中的问题经常涵盖了广泛的有趣的推理模式,数据集只被少数模式所主导,这是训练模型自然关注的。 - The contexts occurring in existing RC datasets often contain artifacts and reasoning shortcuts. Such contexts allow models to find the answer while bypassing some reasoning steps, in turn preventing models from learning the intended reasoning skills.
出现在现有RC数据集中的上下文通常包含人工制品和推理捷径。这样的上下文允许模型在绕过一些推理步骤的同时找到答案,阻止了模型学习预期的推理技能。 - Can we teach models broad multihop reasoning skills?
作者发问:基于上面出现的问题,那么能不能教模型广泛的多跳推理技能呢?这也就是本文要解决的核心问题。
2 为什么重要?
- 如上面的内容所说,QA问题是个需要广泛推理技能的复杂问题,而现有的datasets可能允许model在绕过一些推理步骤的同时找到answer,这并不是我们所期望的,我们期望模型能学习到广泛的推理技能。这因为这个问题,所以本文所提出的问题及解决方案如此重要。
3 为什么有挑战性?
- The challenge is to teach these reasoning patterns robustly, even when they are relatively rare in multihop datasets.
解决上述问题的方法之一是:对训练过程中所看到的输入上下文模型的类别拥有更好的控制——涵盖了各种各样的推理模式的上下文,同时不允许模型通过捷径方式轻松实现。发现现有数据集中的questions已经包含了广泛的推理模式,但是最大的挑战是:即使它们在多跳数据集中相对少见,我们如何稳健地教授这些推理模式?
4 方法的核心insight是什么?
本文用合成上下文来可靠教广泛技能受启发于三点:
- 通过合成数据学到的技能确实可以转移到真实数据集上 (Geva et al., 2020; Yang et al., 2021; Yoran et al., 2022; Pi et al., 2022);
- 以目标的方式干扰RC实例的现有(自然)上下文可以减少基于人工制品的推理 (Jia and Liang, 2017; Trivedi et al., 2020);
- 仔细构建上下文(对于合成问题)以有足够的干扰物,可以减少当前模型可利用的人工制品 (Trivedi et al., 2022; Khot et al., 2022)
正是基于上面三项研究结论,本文引入TEABREAC这个教授数据集。
5 方法主体是什么?(Overview)
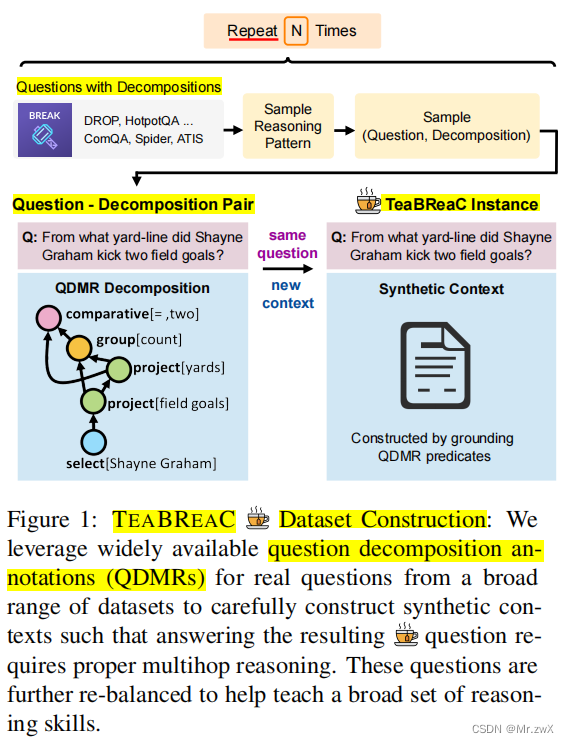
Create a teaching dataset: (a) with broad reasoning skills covering a wide range of multihop reasoning patterns; (b) leveraging existing QDMR annotations to carefully construct contexts that require true multi-hop reasoning.
一种创建教学数据集的新方法,具有广泛的推理技能,涵盖了广泛的多跳推理模式;利用现有的QDMR注释来仔细地构建需要真正的多跳推理的上下文。
Teaching Broad-Coverage Reasoning Skills in a Robust Fashion One
- Way to surface the reasoning needed for answering these questions is to look at their decomposition into smaller reasoning steps that can be composed together in order to arrive at the correct answer.
一种展示这些问题所需的推理的方法是将它们分解为更小的推理步骤,可以组合在一起得到正确答案。

- Problem: the context associated with the questions often allows models to cheat by taking shortcuts. E.g., if the context mentions field goals only by Shayne Graham and no one else, models can ignore the player name and still succeed.
多跳数据集就是针对这种分步推理的,但是存在一个问题!与这些问题相关的上下文通常允许模型通过采取捷径来作弊,比如:如果下问下中只提到了Shayne Graham进球,而没有别人进球,那么模型会忽略球员的名字,仍然成功。 - The key observation is that the decomposition of a question can be leveraged to carefully design a synthetic context for this question that avoids cheating, thereby allowing us to teach models a broad range of reasoning skills in a robust fashion.
本文的关键观察结果是:可以利用问题分解来为问题仔细设计一个合成的上下文,以避免作弊发生,从而允许我们以一种健壮的方式教授模型广泛的推理技能。 - To achieve this, we procedurally create a large pretraining RC QA dataset, TEABREAC, by using real multihop questions (from existing datasets) and their decomposition annotations (already available in the form of QDMRs), and carefully constructing synthetic contexts.
为了实现上面说的,通过使用真实的多跳问题(来自现有数据集)及其分解注释(已经以QDMRs的形式可用了),程序地创建一个大型预训练RCQA数据集——TEABRAC,并仔细构建合成上下文。 - QDMR or Question Decomposition Meaning Representation (Wolfson et al., 2020):reasoning in many types of multihop questions -> sturctured decomposition graph. QDMR有标准操作(被表示为nodes),比如select, project, group, comparative.
Four main steps(will be described in more detail in section 6):
- Making QDMRs more precise
由于QDMR用自然语言编写,并没有指定输入和输出的数据类型,不够精细化。所以,将把QDMRs转换为具有超过44个可执行的原始操作及其输入/输出类型的正式程序。 - Teaching robust compositional skills
我们的QA实例必须使模型不绕过推理步骤,所以从问题-程序对去创建一个合成QA实例问题,问题是原来的问题,但是上下文是通过建立QDMR中的谓语来程序地构建的,这样模型不能欺骗正确的答案。 - Teaching a broad range of reasoning patterns
虽然QDMR覆盖了广泛的推理模式,但是推理模式的自然分布更倾向于流行的推理模式。所以,我们确保我们的合成数据集在推理模式方面更加平衡。 - Teaching a broad range of reasoning primitives
除了前面说的构造数据集以帮助模型学习多种推理技能,还观察到如果我们教模型的原始推理技能,它也有帮助。所以,我们基于固定模板为正式程序中出现的44个原语中的每一个进行程序化地生成QA实例。
6 关键技术点和解决方法?
TEABREAC Dataset Construction
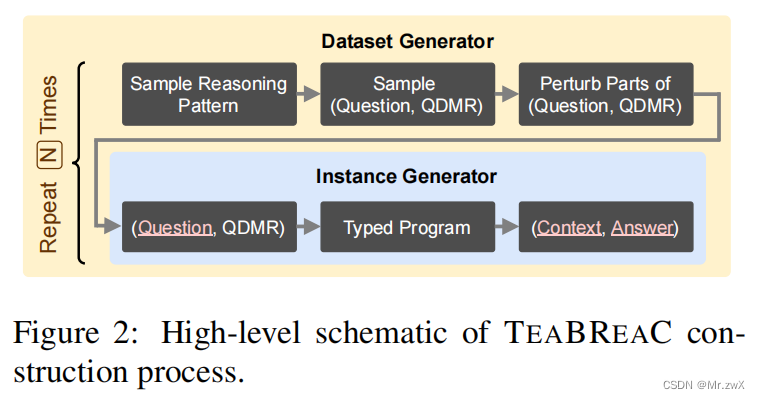
6.1 Instance Generator
- Step 1: QDMR to Typed Program
input: a question Q and its QDMR decomposition D
output: generated synthetic context C and the corresponding answer A
QA instance: tuple (Q, C, A)
要实现这个过程,直接采用QDMRs是不可行的,因为虽然是结构化的,但它们是用自然语言写的,在自然语言中有固有的变化;另外,它们没有输入和输出类型信息,例如不清楚project操作是应该生成dict、list还是scalar,这使得完整的程序难以执行。
为解决这个问题,需要更精细化的设计,本文中定义了一系列的程序,例子如下:

QDMR将一个问题分解为多跳的推理过程,然后定义相关函数,将这个过程转化为Program,最后定义输出格式,得到最终的Typed Program。
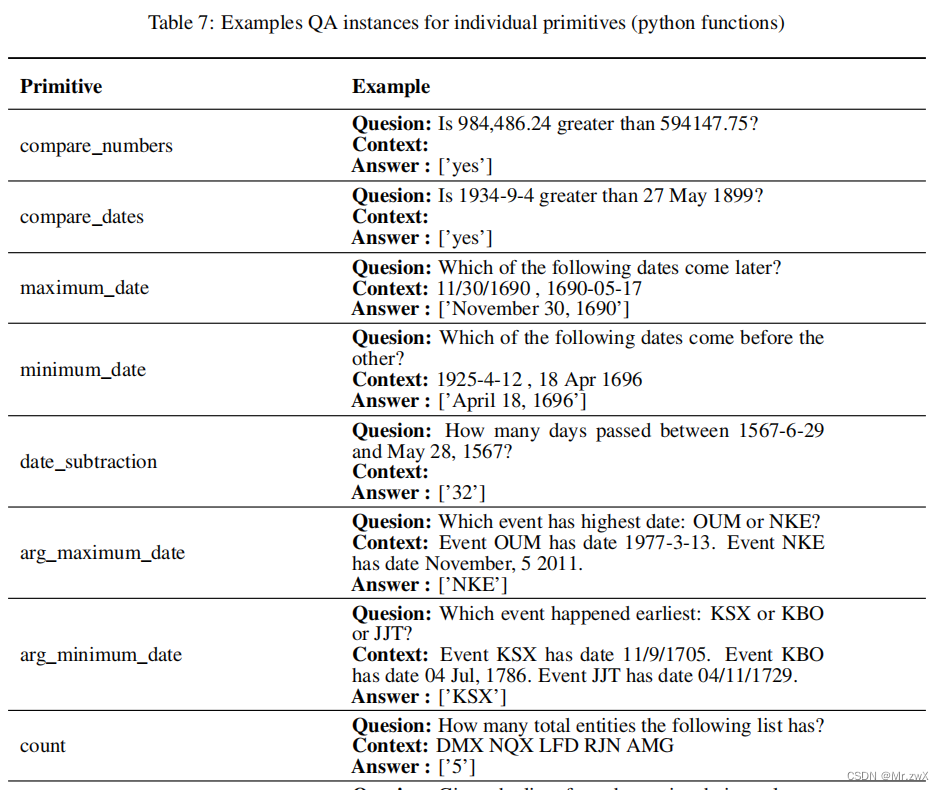
在本文的表示中,采用了44种Python函数(原语)去操作各种类型(number, date, named entity)和结构(scalar, list, dict)的输入输出。举一些例子如下(Appendix Table 6):

- Step 2: Synthetic Context + Answer
这一步,从Typed Program中生成合成上下文C和问题答案A。
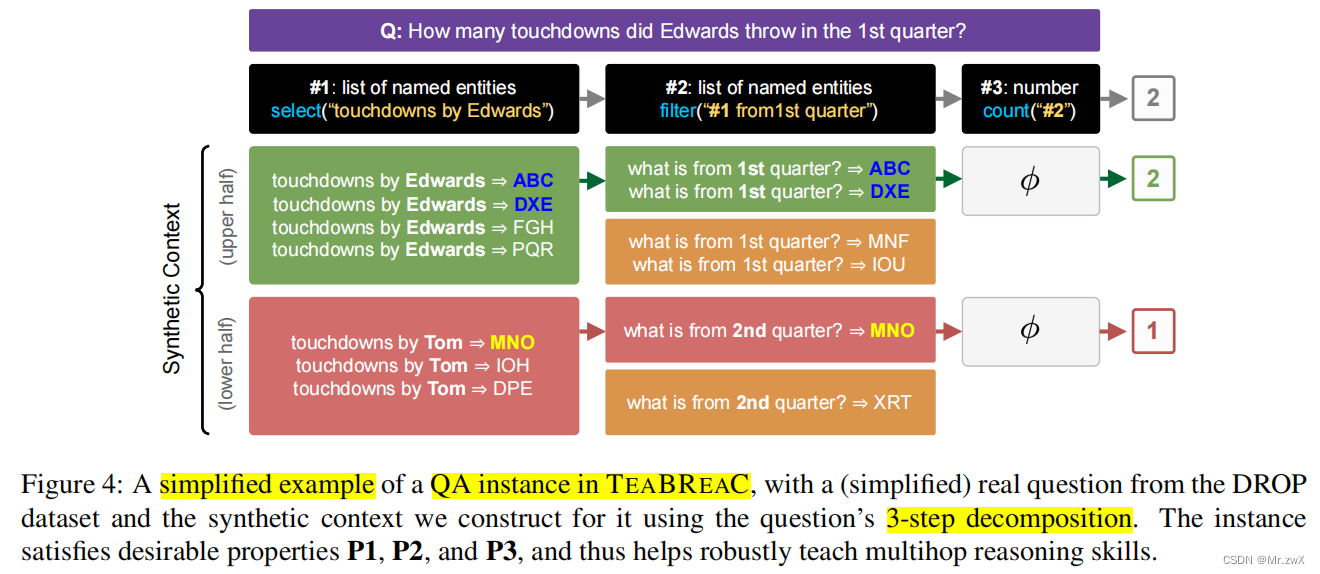
Minimizing reasoning shortcuts
上文有提到,如果直接采用QDMR会导致推理的捷径,从而绕过一些必要的推理过程。例子如下:

实例会满足如下的三个属性:- Answers to dependent steps can’t be ignored (upper half)
比如,step #2的推理过程不可能在不知道step #1的情况下完成。 - Steps can’t be no-op (upper half)
每一个step的输入输出不能相同,否则这一步的推理就被绕过了。比如,step #2不做任何操作,最终的结果就会出错。 - Context also supports a different answer to a contrastive question (lower half)
引入了干扰链(distractor chain)去潜在地干扰谓词(比如Edwards => Tom, 1st => 2nd),要保证能导致答案不同的最低限度的修改。
- Answers to dependent steps can’t be ignored (upper half)
6.2 Dataset Generator
我们已经拥有了从(question, QDMR) pair中生成QA实例的方法,现在开始生成一个数据集。然而,我们发现在这些数据集中,推理模式的自然分布是非常长尾(long-tailed)的,我们将推理模式定义为程序中存在的一个唯一的原语序列(比如上文例子中出现的select, filter, count操作)。
如果直接去生成数据集,我们得到的是一个非常倾向于流行推理模式的QA数据集。后果就是,在这样的数据集上的预训练模型,只会少数推理模式上过拟合,并阻止模型学习广泛的推理技能。
于是提出以下的策略:
- Sample a reasoning pattern
- Sample a question-QDMR pair from that reasoning pattern
- Possibly perturb the entities in the question with a closely similar entity of the same type
6.3 Additional QA Instances for Primitives
除了上述合成的多跳实例外,还采用简单的模板构造了实例来教44种独立的原语。例子如下:

上面例子的最终答案是:[‘RQX’]。
更多例子如下(Appendix Table 7):
6.4 Final Dataset
- Final TEABREAC: 525K and 15K train and dev multihop QA instances respectively, and has about 900 reasoning patterns.
- Source Datasets
Use QDMRs from QA and semantic parsing datasets, DROP, ComplexWebQuestions, HotpotQA, SPIDER, ComQA, ATIS.
7 关键发现是什么?
- Pretraining standard language models (LMs) on TeaBReaC before fine-tuning them on target datasets improves their performance on more complex questions.
微调之前在TeaBReaC数据集上预训练语言模型可以提高他们在复杂问题上的性能。 - The resulting models also demonstrate higher robustness.
提出的模型能表明更高的鲁棒性。 - TeaBReaC pretraining substantially improves model performance and robustness even when starting with numeracy-aware LMs pretrained using recent methods.
用TeaBReaC数据集进行预训练能提高模型的性能和鲁棒性,即使用numeracy-aware语言模型作为起始。 - This paper show how one can effectively use decomposition-guided contexts to robustly teach multihop reasoning.
本文展现了当采用分解引导上下文的方式去稳健地教授多跳推理时到底有多有效。 - The key observation is that the decomposition of a question can be leveraged to carefully design a synthetic context for this question that avoids cheating, thereby allowing us to teach models a broad range of reasoning skills in a robust fashion.
本文的关键观察结果是:可以利用问题分解来为问题仔细设计一个合成的上下文,以避免作弊发生,从而允许我们以一种健壮的方式教授模型广泛的推理技能。
8 主要实验结论是什么
8.1 Experiment Setting
- Compare models directly fine-tuned on target datasets with models first pretrained on TEABREAC and then fine-tuned on target datasets.
- Metric
Exact match metric (EM) for all evaluations - Datasets
- In-domain performance: DROP, TAT-QA, IIRC
- Robustness: DROP contrast set, DROP BPB contrast set
- Model
Evaluate TEABREAC pretraining on two kinds of (language) models:- Plain language models
- T5-Large (Raffel et al., 2020)
- Bart-Large (Lewis et al., 2020)
- Numeracy-aware language models
- NT5 (Yang et al., 2021)
- PReasM-Large
- Tokenization
- A trick adopted from NT5 significantly improves model performance
- So we use this tokenization as a default for all models across all our experiments

- Plain language models
8.2 Main Results
- Learnability of TEABREAC

- Demonstrat the limitations of vanilla LM-based neural models
- On primitives instances models get 92-99 accuracy, and on multihop instances, models get 82-86 accuracy
- TEABREAC improves model performance
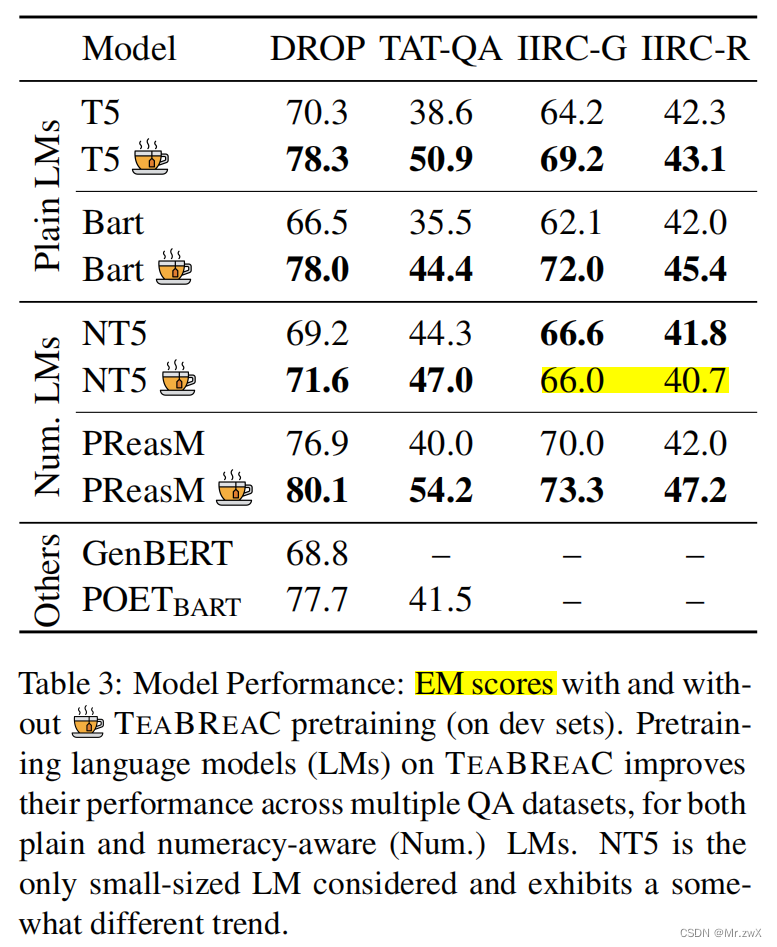
- TEABREAC pretraining doesn’t improve NT5 performance on IIRC-G and IIRC-R
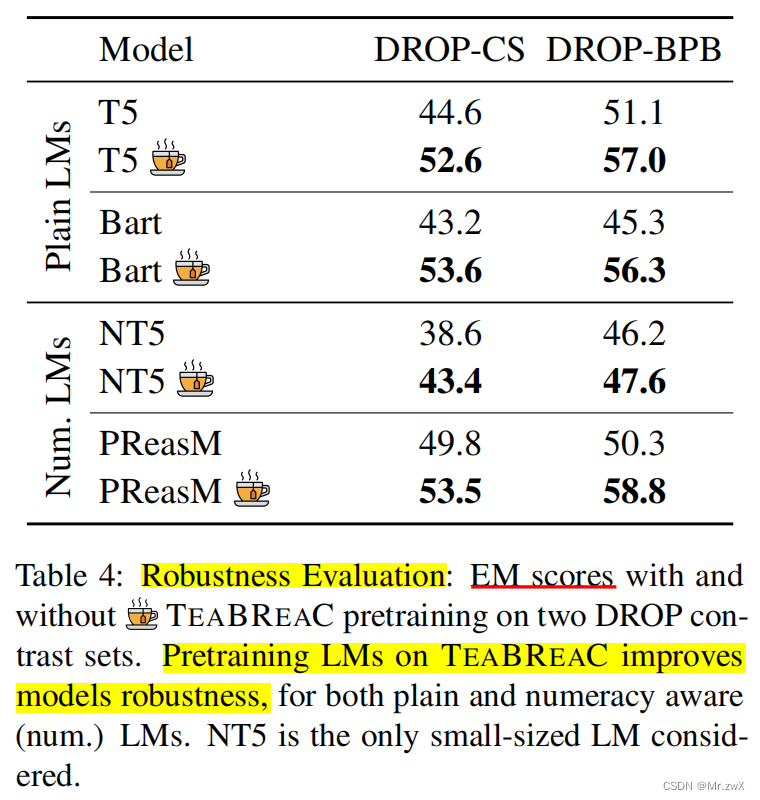
- TEABREAC improves model robustness
- improves more on more complex questions
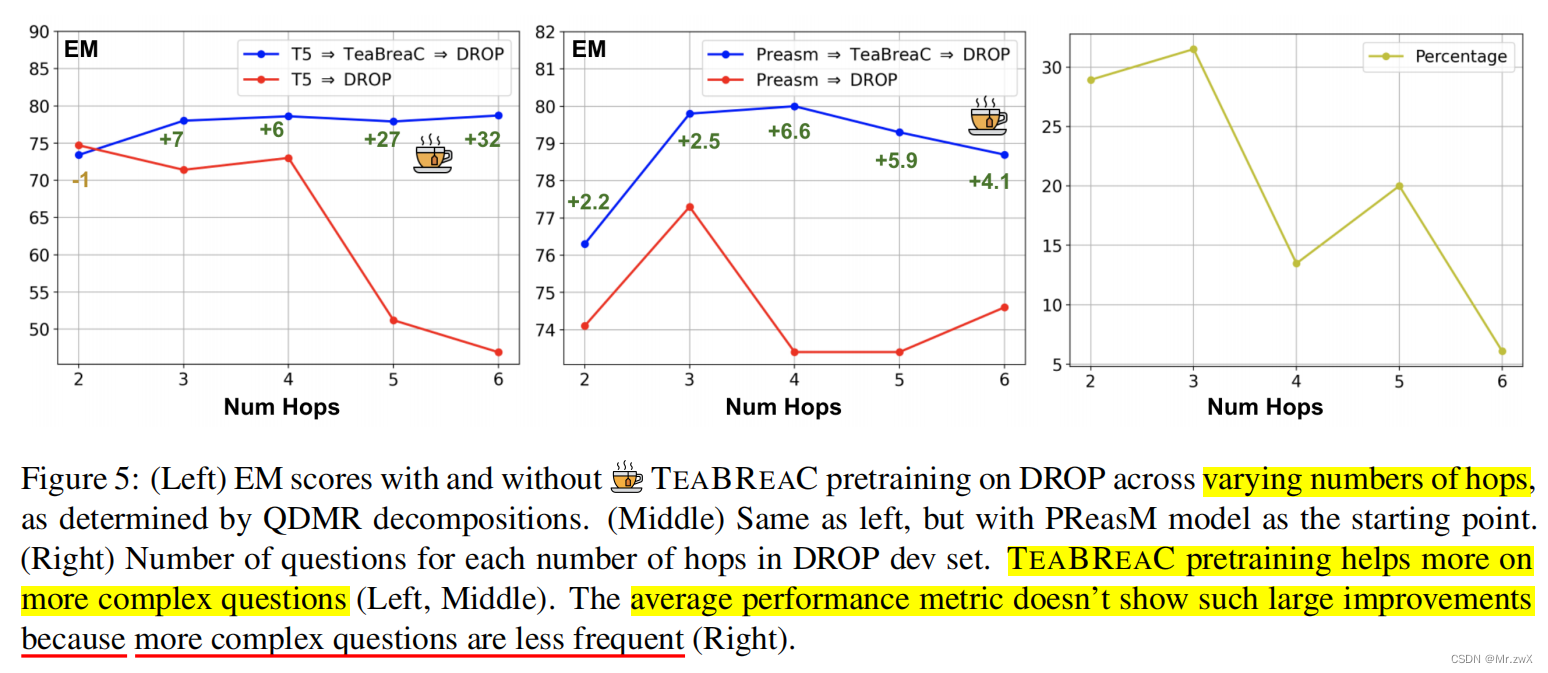
- There is a significantly larger improvement for more complex questions
- Observe that more complex questions are significantly less frequent in the DROP dev set, the average performance metric doesn’t show such large improvements
9 总结和核心takeaway(如何帮助自己的工作?)
- Use decomposition-guided contexts can robustly teach braod multihop reasoning skills.
- The decomposition of a question can be leveraged to carefully design a synthetic context for this question that avoids cheating.