将以下python脚本放置到数据集源文件中,执行即可。然后得到的数据格式就是ImageFolder可读的形式了(划分了train和val文件夹,并且每个文件夹下都有#classes个以label命名的文件夹)
CIFAR-10
import pickle
import numpy as np
import os
import cv2
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
loc_1 = './train'
loc_2 = './val'
if not os.path.exists(loc_1):
os.mkdir(loc_1)
if not os.path.exists(loc_2):
os.mkdir(loc_2)
def unzip():
meta = unpickle('batches.meta')
label_names = meta[b'label_names']
for i in label_names:
dir1 = loc_1 + '/' + i.decode()
dir2 = loc_2 + '/' + i.decode()
if not os.path.exists(dir1):
os.mkdir(dir1)
if not os.path.exists(dir2):
os.mkdir(dir2)
for i in range(1,6):
data_name = 'data_batch_' + str(i)
data = unpickle(data_name)
for j in range (10000):
img = np.reshape(data[b'data'][j], (3, 32, 32))
img = np.transpose(img, (1, 2, 0))
label = label_names[data[b'labels'][j]].decode()
img_name = label + '_' + str(i*10000 + j) + '.jpg'
img_save_path = loc_1 + '/' + label + '/' + img_name
cv2.imwrite(img_save_path, img)
print(data_name + ' finished')
test_data = unpickle('test_batch')
for i in range (10000):
img = np.reshape(test_data[b'data'][i], (3, 32, 32))
img = np.transpose(img, (1, 2, 0))
label = label_names[test_data[b'labels'][i]].decode()
img_name = label + '_' + str(i) + '.jpg'
img_save_path = loc_2 + '/' + label + '/' + img_name
cv2.imwrite(img_save_path, img)
print('test_batch finished')
if __name__ == '__main__':
unzip()
转化前:
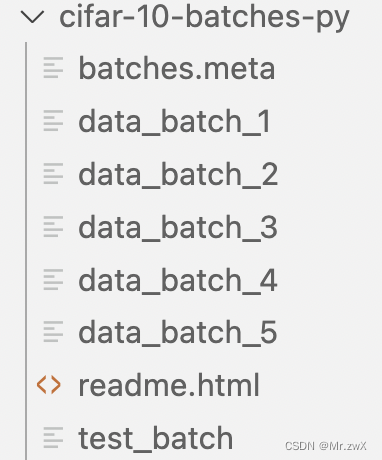
转化后:

CIFAR-100
import pickle
import numpy as np
import os
import cv2
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes') # encoding='latin1'
return dict
loc_1 = './train'
loc_2 = './val'
if not os.path.exists(loc_1):
os.mkdir(loc_1)
if not os.path.exists(loc_2):
os.mkdir(loc_2)
def unzip():
meta = unpickle('meta')
print(meta.keys())
label_names = meta[b'fine_label_names']
for i in label_names:
dir1 = loc_1 + '/' + i.decode()
dir2 = loc_2 + '/' + i.decode()
if not os.path.exists(dir1):
os.mkdir(dir1)
if not os.path.exists(dir2):
os.mkdir(dir2)
i = 1
data_name = 'train'
data = unpickle(data_name)
for j in range (50000):
img = np.reshape(data[b'data'][j], (3, 32, 32))
img = np.transpose(img, (1, 2, 0))
label = label_names[data[b'fine_labels'][j]].decode()
img_name = label + '_' + str(i * 10000 + j) + '.jpg'
img_save_path = loc_1 + '/' + label + '/' + img_name
cv2.imwrite(img_save_path, img)
print(data_name + ' finished')
test_data = unpickle('test')
for i in range (10000):
img = np.reshape(test_data[b'data'][i], (3, 32, 32))
img = np.transpose(img, (1, 2, 0))
label = label_names[test_data[b'fine_labels'][i]].decode()
img_name = label + '_' + str(i) + '.jpg'
img_save_path = loc_2 + '/' + label + '/' + img_name
cv2.imwrite(img_save_path, img)
print('test_batch finished')
if __name__ == '__main__':
unzip()
转化前:

转化后:
