前言
在我们之前介绍进程等待的时候,曾经介绍过父进程会等待子进程并且回收子进程的运行结束状态(status输出型参数):参考博客
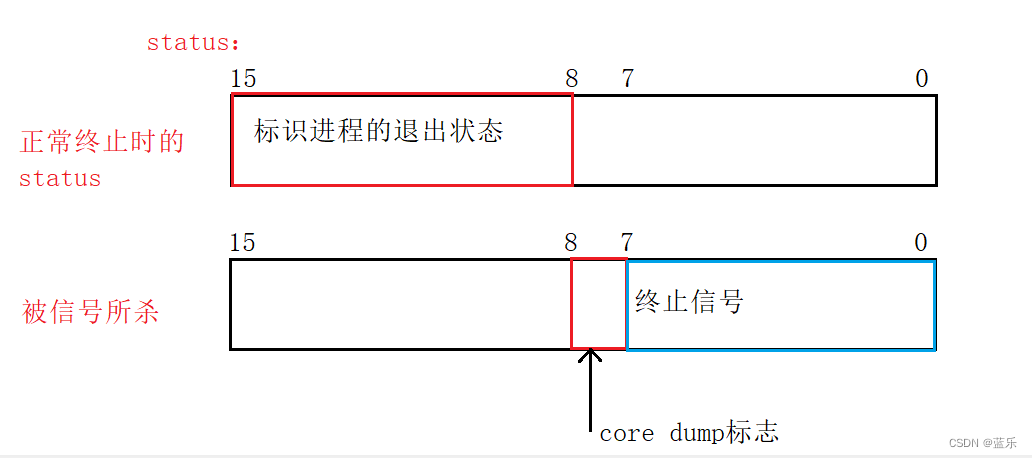
当进程因为一些硬件中断,异常等情况意外终止被信号所杀之后,退出码第8为的coredump标志位就会设置为1,这样其父进程会检测到,并且生成一个core快照文件用于后续寻找异常原因;
coredump是什么?
coredump翻译过来就是核心转储,这个机制会在用户级进程异常挂掉时的一个快照(kdump为内核级进程崩溃下面介绍),保存了异常时的内存、寄存器、堆栈等运行信息。这些数据存储成一个core文件,可以进一步通过gdb等调试器查看分析异常原因;
运行异常代码
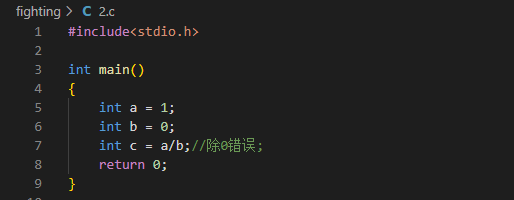
异常代码运行结果

查看本地文件多出的core文件

其实core.xxx,这个xxx部分就是当时异常进程对应的pid!
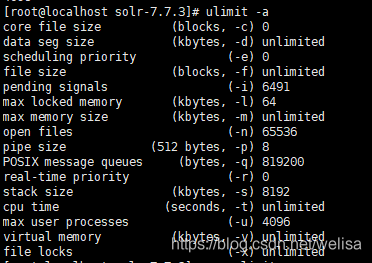
注意:如果无法生成core文件的话,是因为系统默认core文件大小为0字节了,需要用指令ulimit -c xxx 设置一下;
ulimit指令:
- S:表示软限制,超出设定的值会告警。
- H :表示硬限制,超出设定的值会报错。
- a :列出系统所有资源限制的值
c:当某些程序发生错误时,系统可能会将该程序在内存中的一些运行信息写成文件(除错用),这种文 件就被称为核心文件(core file)。此为限制每个核心文件的最大容量d:每个进程数据段的最大值f:当前shell可创建的最大文件容量l:可以锁定的物理内存的最大值m:可以使用的常驻内存的最大值n:每个进程可以同时打开的最大文件句柄数p:管道的最大值s:堆栈的最大值t:每个进程可以使用CPU的最大时间u:每个用户运行的最大进程并发数v:当前shell可使用的最大虚拟内存
gdb调试带上core文件
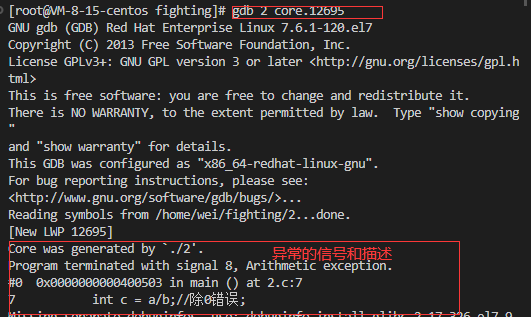
可以看到,这次gdb调试2程序的时候,后面加上上对应的core文件(注意gcc编译得加-g生成debug版的程序才能用gdb调试), 会直接跳转到异常的位置,显示了OS发来的异常信号并且描述了异常原因,这有利于我们调试过程中定位异常等等;
kdump机制
Kdump即kernel dump,内核崩溃转储,他的作用和coredump核心转储一样,场景不同,coredump是在用户级的程序挂掉,而Kdump是内核系统级进程崩溃的时候通过kexec进入第二内核捕获生成的crash dump文件;
Kdump的使用比较复杂,要配置很多选项;
大致流程: 通过kexec机制–>第一内核崩了后load第二(捕获)内核load到内存,并在崩溃的瞬间切换到第二内核运行,同时在第二内核中借助借助一系列的非gdb调试工具进行调试分析崩溃原因!