一、绘制立方体
2023年4月6日,谷歌宣布在 Chrome 用户可在 113 Beta 版本中,启用全新的 WebGPU 图形 API,支持硬件图形加速。
本系列是学习记录,尚不能称之为教程(因此可能在代码的实现上、原理的阐述上等都可能存在不合适、不严谨或错误)。该系列希望通过代码撰写以及解读代码的含义,尝试阐述 WebGPU 中相关的图形学效果的实现方法、原理。如有遗漏、错误,还请指正与赐教。
一、Buffer Creation 和 GPUBufferDescriptor
GPUBufferDescriptor有以下成员:
- size: 类型为 GPUSize64
缓冲区的大小,以 byte 为单位。
- usage:类型为 GPUBufferUsageFlags
缓冲区允许的用法。
- mappedAtCreation,类型为 boolean,默认为 false
如果为 true,则在已经映射的状态下创建缓冲区,允许立即调用 getMappedRange()。即使使用中不包含 MAP_READ 或 MAP_WRITE,将 mappedAtCreation 设置为 true 也是有效的。这可以用来设置缓冲区的初始数据。
保证即使缓冲区创建最终失败,它仍然会显示为映射
// Create a vertex buffer from the cube data.
const verticesBuffer = device.createBuffer({
size: cubeVertexArray.byteLength, // 指定了需要申请多大的显存,单位是 byte
usage: GPUBufferUsage.VERTEX,
mappedAtCreation: true // 被设置为 true,则 size 必须是 4 的倍数
});
二、Buffer Mapping 和 getMappedRange()
应用程序可以请求映射一个 GPUBuffer,这样它们就可以通过代表 GPUBuffer 分配的部分的 arraybuffer 访问它的内容。映射一个 GPUBuffer 是通过 mapAsync() 异步请求的,这样用户代理可以确保 GPU 在应用程序访问它的内容之前完成了对 GPUBuffer 的使用。映射的 GPUBuffer 不能被 GPU 使用,必须使用 unmap() 解除映射,然后才能将使用它的工作提交到 Queue 时间轴。
一旦映射了 GPUBuffer,应用程序就可以通过 getMappedRange 同步请求访问其内容的范围
new Float32Array(verticesBuffer.getMappedRange()).set(cubeVertexArray);
verticesBuffer.unmap();
缓冲映射
缓冲映射,直接简单的说,映射(Mapping)后的某块显存,就能被 CPU 访问。
三大图形 API(D3D12、Vulkan、Metal)的 Buffer(指显存)映射后,CPU 就能访问它了。此时注意,GPU 仍然可以访问这块显存。这就会导致一个问题:IO冲突,这就需要程序考量这个问题了。
WebGPU 禁止了这个行为,改用传递“所有权”来表示映射后的状态。每一个时刻,CPU 和 GPU 是单边访问显存的,也就避免了竞争和冲突。
当 JavaScript 请求映射显存时,所有权并不是马上就能移交给 CPU 的,GPU 这个时候可能手头上还有别的处理显存的操作。所以,GPUBuffer 的映射方法是一个异步方法:
const someBuffer = device.createBuffer({
/* ... */ }) |
await someBuffer.mapAsync(GPUMapMode.READ, 0, 4) // 从 0 开始,只映射 4 个字节 |
// 之后就可以使用 getMappedRange 方法获取其对应的 ArrayBuffer 进行缓冲操作 |
不过,解映射操作倒是一个同步操作,CPU 用完后就可以解映射:
somebuffer.unmap()
创建时映射
可以在创建缓冲时传递 mappedAtCreation: true,这样甚至都不需要声明其 usage 带有 GPUBufferUsage.MAP_WRITE
const buffer = device.createBuffer({
usage: GPUBufferUsage.UNIFORM,
size: 256,
mappedAtCreation: true,
})
// 然后马上就可以获取映射后的 ArrayBuffer
const mappedArrayBuffer = buffer.getMappedRange()
/* 在这里执行一些写入操作 */
// 解映射,还管理权给 GPU
buffer.unmap()
缓冲数据的流向
1、CPU 至 GPU
JavaScript 这端会在 rAF (requestAnimationFrame)中频繁地将大量数据传递给 GPUBuffer 映射出来的 ArrayBuffer,然后随着解映射、提交指令缓冲到队列,最后传递给 GPU.
上述最常见的例子莫过于传递每一帧所需的 VertexBuffer、UniformBuffer 以及计算通道所需的 StorageBuffer 等。
使用队列对象的 writeBuffer 方法写入缓冲对象是非常高效率的,但是与用来写入的映射后的一个 GPUBuffer 相比,writeBuffer 有一个额外的拷贝操作。推测会影响性能,虽然官方推荐的例子中有很多 writeBuffer 的操作,大多数是用于 UniformBuffer 的更新。
2、 GPU 至 CPU
这样反向的传递比较少,但也不是没有。譬如屏幕截图(保存颜色附件到 ArrayBuffer)、计算通道的结果统计等,就需要从 GPU 的计算结果中获取数据。
譬如,官方给的从渲染的纹理中获取像素数据例子:
const texture = getTheRenderedTexture()
const readbackBuffer = device.createBuffer({
usage: GPUBufferUsage.COPY\_DST | GPUBufferUsage.MAP\_READ,
size: 4 * textureWidth * textureHeight,
})
// 使用指令编码器将纹理拷贝到 GPUBuffer
const encoder = device.createCommandEncoder()
encoder.copyTextureToBuffer(
{
texture },
{
buffer, rowPitch: textureWidth * 4 },
[textureWidth, textureHeight],
) |
device.submit([encoder.finish()])
// 映射,令 CPU 端的内存可以访问到数据
await buffer.mapAsync(GPUMapMode.READ)
// 保存屏幕截图
saveScreenshot(buffer.getMappedRange())
// 解映射
buffer.unmap()
Accessing Mapped Buffers
一旦一个 GPUBuffer 被映射,就可以通过 JavaScript 访问它的内存,这是通过调用 GPUBuffer 来完成的。getMappedRange,它返回一个称为 “mapping” 的 ArrayBuffer。这些在 GPUBuffer 之前都可用。调用 unmap 或 GPUBuffer.destroy,此时它们被分离。这些 arraybuffer 通常不是新的分配,而是指向某种对内容进程可见的共享内存(IPC共享内存,mmapping 文件描述符等)。当将所有权转移到GPU时,可能需要从共享内存复制到底层映射缓冲区。GPUBuffer。getMappedRange 接受一个可选的要映射的缓冲区范围(其中偏移量0是缓冲区的开始)。通过这种方式,浏览器知道底层 GPUBuffer 的哪些部分已经“失效”,需要从内存映射中更新。该范围必须在 mapAsync() 中请求的范围内。
VAO、VBO、EBO、FBO、PBO、TBO、UBO
VBO 和 EBO
VBO(Vertex Buffer Object)是指顶点缓冲区对象,而 EBO(Element Buffer Object)是指图元索引缓冲区对象,VAO 和 EBO 实际上是对同一类 Buffer 按照用途的不同称呼。
OpenGL ES 2.0 编程中,用于绘制的顶点数组数据首先保存在 CPU 内存,在调用 glDrawArrays 或者 glDrawElements 等进行绘制时,需要将顶点数组数据从 CPU 内存拷贝到显存。
但是很多时候我们没必要每次绘制的时候都去进行内存拷贝,如果可以在显存中缓存这些数据,就可以在很大程度上降低内存拷贝带来的开销。
OpenGL ES 3.0 编程中, VBO 和 EBO 的出现就是为了解决这个问题。
VBO 和 EBO 的作用是在显存中提前开辟好一块内存,用于缓存顶点数据或者图元索引数据,从而避免每次绘制时的 CPU 与 GPU 之间的内存拷贝,可以改进渲染性能,降低内存带宽和功耗。
export const cubeVertexSize = 4 * 10; // Byte size of one cube vertex.
export const cubePositionOffset = 0;
export const cubeColorOffset = 4 * 4; // Byte offset of cube vertex color attribute.
export const cubeUVOffset = 4 * 8;
export const cubeVertexCount = 36;
// prettier-ignore
export const cubeVertexArray = new Float32Array([
// float4 position, float4 color, float2 uv,
1, -1, 1, 1, 1, 0, 1, 1, 1, 1,
-1, -1, 1, 1, 0, 0, 1, 1, 0, 1,
-1, -1, -1, 1, 0, 0, 0, 1, 0, 0,
1, -1, -1, 1, 1, 0, 0, 1, 1, 0,
1, -1, 1, 1, 1, 0, 1, 1, 1, 1,
-1, -1, -1, 1, 0, 0, 0, 1, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, -1, 1, 1, 1, 0, 1, 1, 0, 1,
1, -1, -1, 1, 1, 0, 0, 1, 0, 0,
1, 1, -1, 1, 1, 1, 0, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, -1, -1, 1, 1, 0, 0, 1, 0, 0,
-1, 1, 1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 0, 1,
1, 1, -1, 1, 1, 1, 0, 1, 0, 0,
-1, 1, -1, 1, 0, 1, 0, 1, 1, 0,
-1, 1, 1, 1, 0, 1, 1, 1, 1, 1,
1, 1, -1, 1, 1, 1, 0, 1, 0, 0,
-1, -1, 1, 1, 0, 0, 1, 1, 1, 1,
-1, 1, 1, 1, 0, 1, 1, 1, 0, 1,
-1, 1, -1, 1, 0, 1, 0, 1, 0, 0,
-1, -1, -1, 1, 0, 0, 0, 1, 1, 0,
-1, -1, 1, 1, 0, 0, 1, 1, 1, 1,
-1, 1, -1, 1, 0, 1, 0, 1, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
-1, 1, 1, 1, 0, 1, 1, 1, 0, 1,
-1, -1, 1, 1, 0, 0, 1, 1, 0, 0,
-1, -1, 1, 1, 0, 0, 1, 1, 0, 0,
1, -1, 1, 1, 1, 0, 1, 1, 1, 0,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, -1, -1, 1, 1, 0, 0, 1, 1, 1,
-1, -1, -1, 1, 0, 0, 0, 1, 0, 1,
-1, 1, -1, 1, 0, 1, 0, 1, 0, 0,
1, 1, -1, 1, 1, 1, 0, 1, 1, 0,
1, -1, -1, 1, 1, 0, 0, 1, 1, 1,
-1, 1, -1, 1, 0, 1, 0, 1, 0, 0,
])
由于顶点位置和颜色数据、uv 数据(如上代码)在同一个数组里,一起更新到 VBO 里面,所以需要知道 3 个属性的步长和偏移量。
为获得数据队列中下一个属性值(比如位置向量的下个 4 维分量)我们必须向右移动 10 个 float ,其中 4 个是位置值,另外 4 个是颜色值,还有 2 个是 uv 值,那么步长就是 10 乘以 float 的字节数 4(= 40 字节)。
同样,也需要指定顶点位置属性和颜色属性、uv 属性在 VBO 内存中的偏移量。
对于每个顶点来说,位置顶点属性在前,所以它的偏移量是 0 。而颜色属性紧随位置数据之后,所以偏移量就是 4 * 4 ,用字节来计算就是 16 字节。
// 1、创建 VBO
// 获取一块状态为映射了的显存,以及一个对应的 arrayBuffer 对象来写数据
const verticesBuffer = device.createBuffer({
size: cubeVertexArray.byteLength, // 指定了需要申请多大的显存,单位是 byte
usage: GPUBufferUsage.VERTEX,
mappedAtCreation: true // 被设置为 true,则 size 必须是 4 的倍数,创建时立刻映射,让 CPU 端能读写数据
});
// 2、复制目标/复制源类型的 GPUBuffer
const arrayBuffer = verticesBuffer.getMappedRange()
// 通过 TypedArray 向 ArrayBuffer 写入数据
new Float32Array(arrayBuffer).set(cubeVertexArray);
// 解除显存对象的映射,稍后它就能在 GPU 中进行复制操作
verticesBuffer.unmap();
UBO
UBO,Uniform Buffer Object 顾名思义,就是一个装载 uniform 变量数据的缓冲区对象,本质上跟 OpenGL ES 的其他缓冲区对象没有区别,创建方式也大致一致,都是显存上一块用于储存特定数据的区域。
当数据加载到 UBO ,那么这些数据将存储在 UBO 上,而不再交给着色器程序,所以它们不会占用着色器程序自身的 uniform 存储空间,UBO 是一种新的从内存到显存的数据传递方式,另外 UBO 一般需要与 uniform 块配合使用。
const uniformBufferSize = 4 * 16; // 4x4 matrix
// 创建 UBO
// COPY_DST 通常就意味着有数据会复制到此 GPUBuffer 上,这种 GPUBuffer 可以通过 queue.writeBuffer 方法写入数据
const uniformBuffer = device.createBuffer({
size: uniformBufferSize,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST
});
const uniformBindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0),
entries: [
{
binding: 0,
resource: {
buffer: uniformBuffer
}
}
]
});
三、uniform 资源的创建与写入
创建:
const uniformBufferSize = 4 * 16; // 4x4 matrix
// 创建 UBO
// COPY_DST 通常就意味着有数据会复制到此 GPUBuffer 上,这种 GPUBuffer 可以通过 queue.writeBuffer 方法写入数据
const uniformBuffer = device.createBuffer({
size: uniformBufferSize,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST
});
const uniformBindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0),
entries: [
{
binding: 0,
resource: {
buffer: uniformBuffer
}
}
]
});
写入:
const aspect = canvas.width / canvas.height;
const projectionMatrix = mat4.create();
mat4.perspective(projectionMatrix, (2 * Math.PI) / 5, aspect, 1, 100.0);
function getTransformationMatrix() {
const viewMatrix = mat4.create();
mat4.translate(viewMatrix, viewMatrix, vec3.fromValues(0, 0, -4));
const now = Date.now() / 1000;
mat4.rotate(
viewMatrix,
viewMatrix,
1,
vec3.fromValues(Math.sin(now), Math.cos(now), 0)
);
const modelViewProjectionMatrix = mat4.create();
mat4.multiply(modelViewProjectionMatrix, projectionMatrix, viewMatrix);
return modelViewProjectionMatrix as Float32Array;
}
// 写入
const transformationMatrix = getTransformationMatrix();
device.queue.writeBuffer(
uniformBuffer, //传给谁
0,
transformationMatrix.buffer, // 传递 ArrayBuffer
transformationMatrix.byteOffset, // 从哪里开始
transformationMatrix.byteLength // 取多长
);
WebGPU使用uniform buffer object来传递uniform变量。uniform buffer是一个全局的buffer,我们只需要设置一次值,然后在每次draw之前,设置使用的数据范围(通过offset, size来设置),从而复用相同的数据。如果uniform值有变化,则只需要修改uniform buffer对应的数据。
在WebGPU中,我们可以把所有gameObject的model矩阵设为一个ubo,所有相机的view和projection矩阵设为一个ubo,每一种material(如phong material,pbr material等)的数据(如diffuse color,specular color等)设为一个ubo,每一种light(如direction light、point light等)的数据(如light color、light position等)设为一个ubo,这样可以有效减少uniform变量的传输开销。
另外,我们需要注意ubo的内存布局:
默认的布局为std140,我们可以粗略地理解为,它约定了每一列都有4个元素。
我们来举例说明:
下面的ubo对应的uniform block,定义布局为std140:
layout (std140) uniform ExampleBlock
{
float value;
vec3 vector;
mat4 matrix;
float values[3];
bool boolean;
int integer;
};
它在内存中的实际布局为:
layout (std140) uniform ExampleBlock
{
// base alignment // aligned offset
float value; // 4 // 0
vec3 vector; // 16 // 16 (must be multiple of 16 so 4->16)
mat4 matrix; // 16 // 32 (column 0)
// 16 // 48 (column 1)
// 16 // 64 (column 2)
// 16 // 80 (column 3)
float values[3]; // 16 // 96 (values[0])
// 16 // 112 (values[1])
// 16 // 128 (values[2])
bool boolean; // 4 // 144
int integer; // 4 // 148
};
也就是说,这个ubo的第一个元素为value,第2-4个元素为0(为了对齐);
第5-7个元素为vector的x、y、z的值,第8个元素为0;
第9-24个元素为matrix的值(列优先);
第25-27个元素为values数组的值,第28个元素为0;
第29个元素为boolean转为float的值,第30-32个元素为0;
第33个元素为integer转为float的值,第34-36个元素为0。
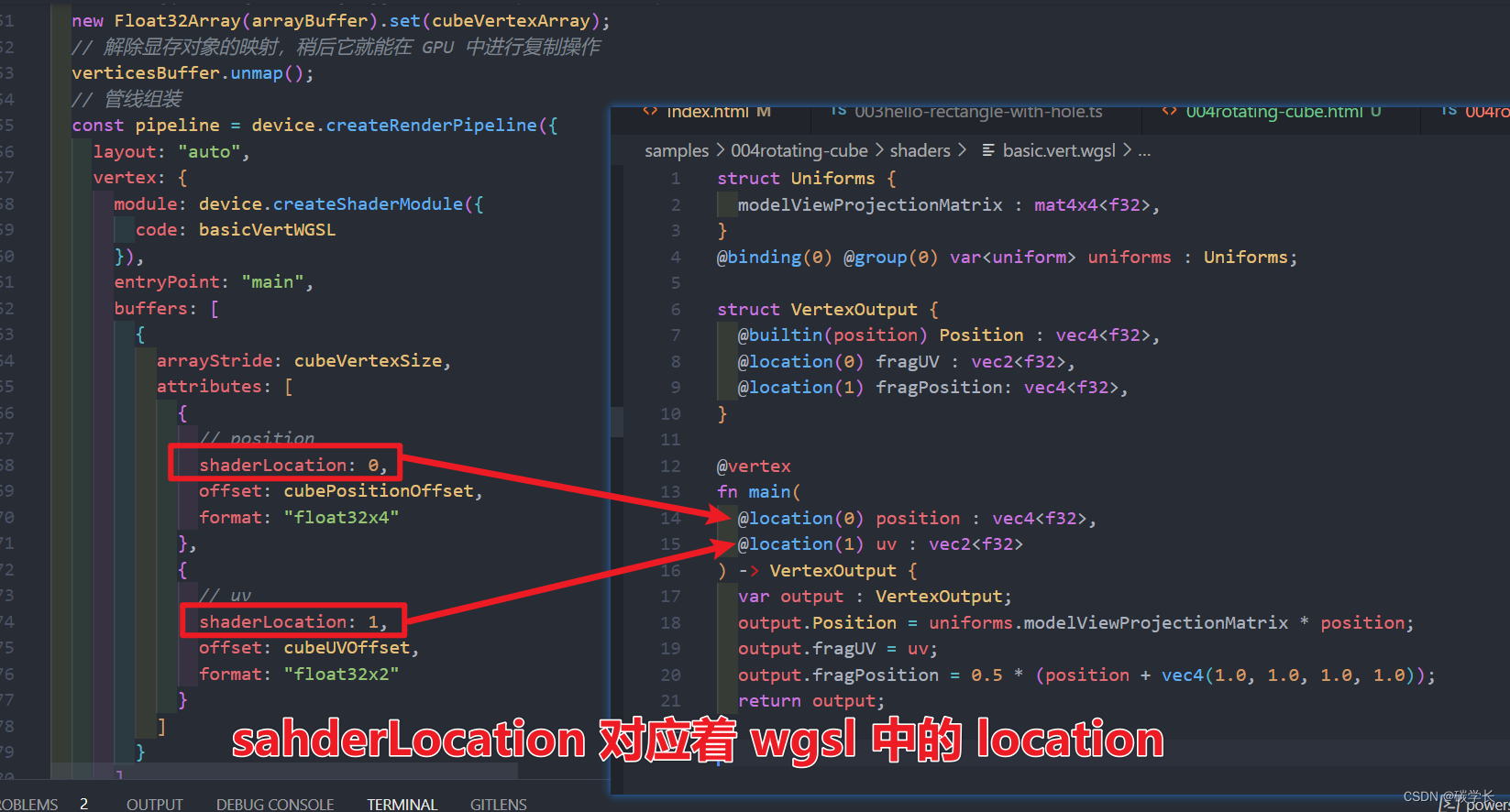
上图中的 position 和 uv 的 shaderLocation 分别代表 wgsl 的 main 函数的两个传参。
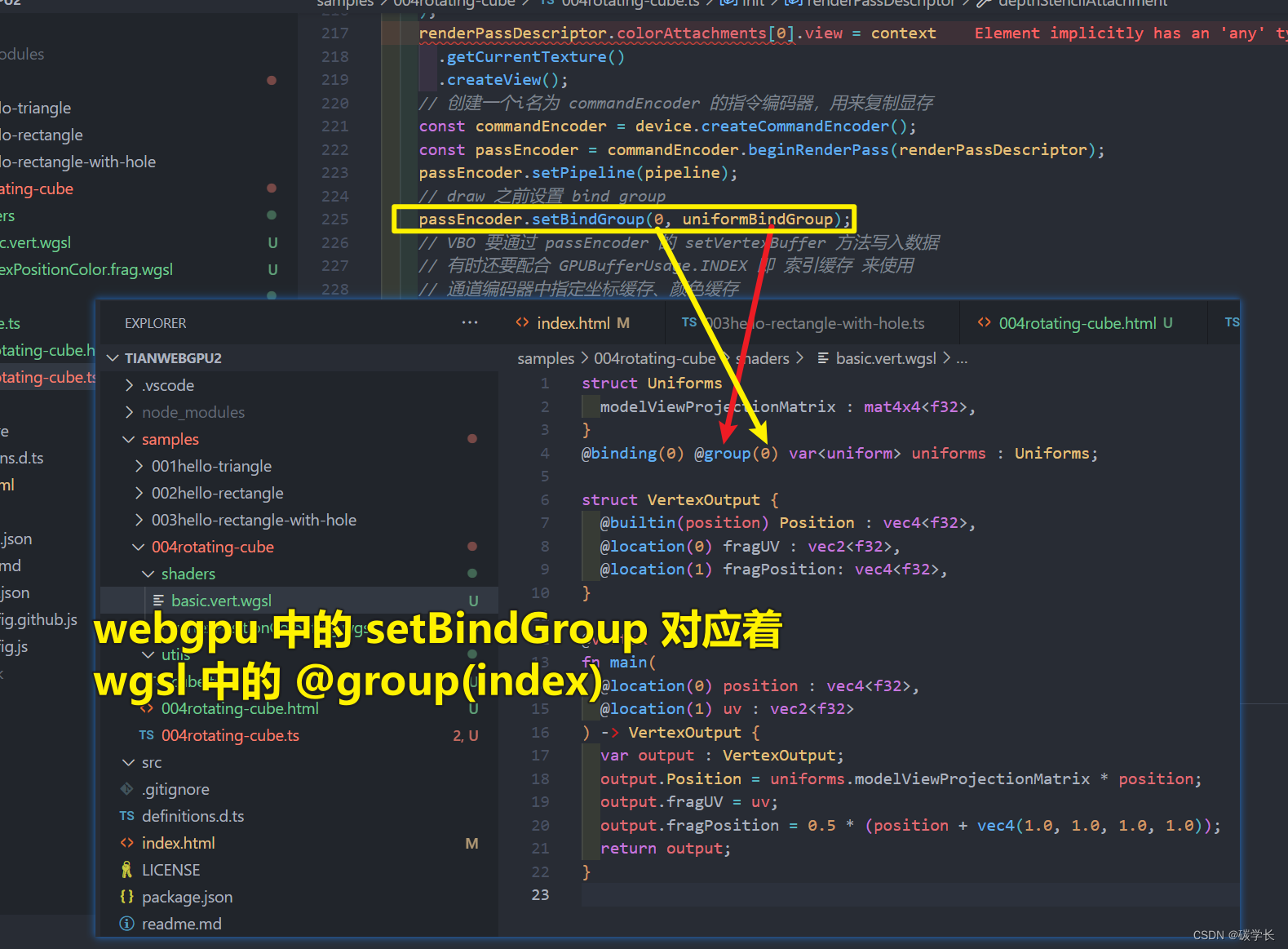
上图中的 passEncoder.setBindGroup(0,uniformBindGroup) 中的 “0”对应vertex shader中uniform block的“@group(0)”
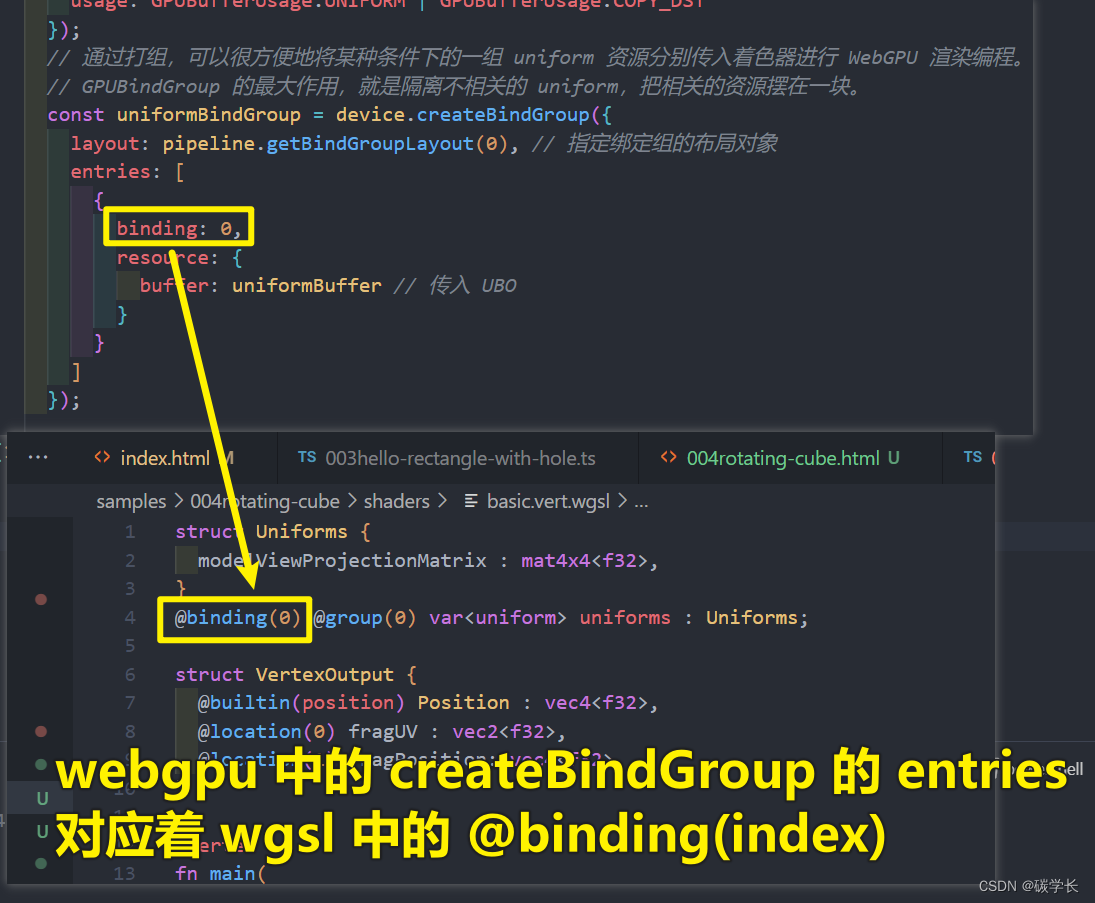
上图中的 binding: 0,binding对应vertex shader中uniform block的binding,意思是bindings数组的第一个元素的对应binding为0的uniform block
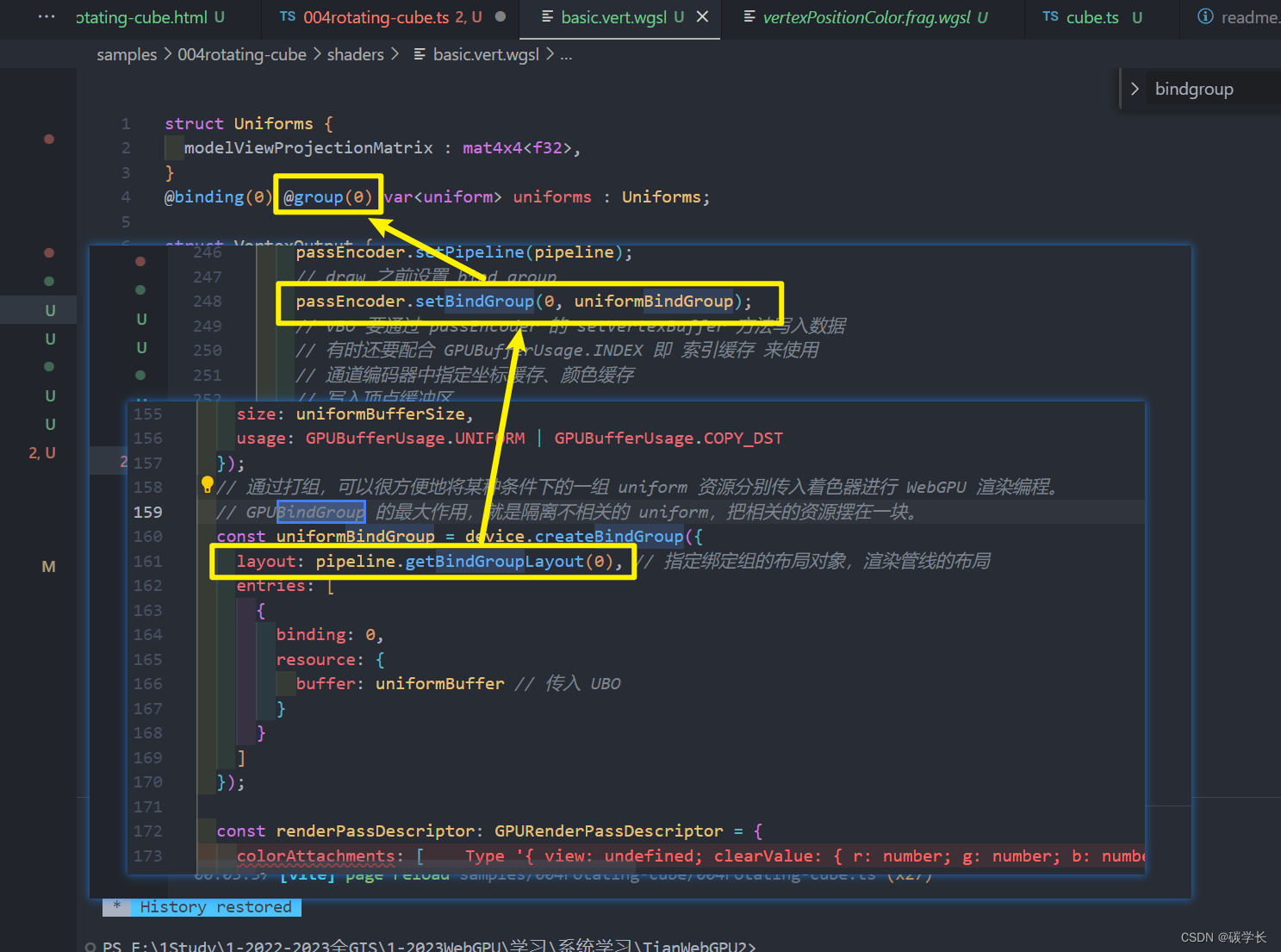
在显存里创建多个Buffer和Texture这些资源,通过BinderGroup的形式将不同的Buffer进行组合,再通过setBindGroup()【API】,将一个group绑定到对应管线当中,然后可以在Shader里面通过@group @bingding的形式获取对应的buffer信息。跟之前的VertexBuffer不同的是,这种group的组合形式相当于是全局变量。一个group可以在同一个Vertex Shader和fragment shader之间共享数据,也可以绑定到别的管线中,在不同的管线之间共享数据。所以方便动态地更改shader数据,所以更灵活。
四、WGSL 的一些知识
入口点
WGSL 没有强制使用固定的 main() 函数作为入口点(Entry Point),它通过 @vertex、@fragment、@compute 三个着色器阶段(Shader State)标记提供了足够的灵活性让开发人员能更好的组织着色器代码。你可以给入口点取任意函数名,只要不重名,还能将所有阶段(甚至是不同着色器的同一个阶段)的代码组织同一个文件中:
// 顶点着色器入口点
@vertex
fn vs_main() {
}
// 片无着色器入口点
@fragment
fn fs_main() -> @location(X) vec4<f32>{
}
// 计算着色器入口点
@compute
fn cs_main() {
}
Group 与 Binding 属性
WGSL 中每个资源都使用了 @group(X) 和 @binding(X) 属性标记,例如 @group(0) @binding(0) var<uniform> params: Uniforms。
params 它表示的是 Uniform buffer 对应于哪个绑定组中的哪个绑定槽。这与 GLSL 中的 layout(set = X, binding = X) 布局标记类似。WGSL 的属性非常明晰,描述了着色器阶段到结构的精确二进制布局的所有内容。
完整代码即注释:
/*
* @Description:
* @Author: tianyw
* @Date: 2023-04-08 20:03:35
* @LastEditTime: 2023-04-11 22:07:04
* @LastEditors: tianyw
*/
import {
mat4, vec3 } from "gl-matrix";
import {
cubeVertexArray,
cubeVertexSize,
cubeUVOffset,
cubePositionOffset,
cubeVertexCount
} from "./utils/cube";
export type SampleInit = (params: {
canvas: HTMLCanvasElement;
}) => void | Promise<void>;
import basicVertWGSL from "./shaders/basic.vert.wgsl?raw";
import vertexPositionColorWGSL from "./shaders/vertexPositionColor.frag.wgsl?raw";
const init: SampleInit = async ({
canvas }) => {
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) return;
const device = await adapter.requestDevice();
const context = canvas.getContext("webgpu");
if (!context) return;
const devicePixelRatio = window.devicePixelRatio || 1;
canvas.width = canvas.clientWidth * devicePixelRatio;
canvas.height = canvas.clientHeight * devicePixelRatio;
const presentationFormat = navigator.gpu.getPreferredCanvasFormat();
context.configure({
device,
format: presentationFormat,
alphaMode: "premultiplied"
});
console.log("bytelength等于:4 * 10 * 6 * 6=", cubeVertexArray.byteLength);
// Create a vertex buffer from the cube data.
// 1、创建 VBO
// 获取一块状态为映射了的显存,以及一个对应的 arrayBuffer 对象来写数据
// 建立顶点缓冲区
// 它就是一块存储空间,先让 js 把顶点数据放进去,然后再让着色器从里面读取
// 至于为什么 js 不通过一个简单的方法直接把顶点数据传递给着色器,这是因为 js 和 着色器用的是两种不一样的语言
// 它们无法直接对话,因此需要一个缓冲地带,也就是缓冲区对象
const verticesBuffer = device.createBuffer({
size: cubeVertexArray.byteLength, // 指定了需要申请多大的显存,单位是 byte
usage: GPUBufferUsage.VERTEX, // 表示与顶点相关的变量
mappedAtCreation: true // 被设置为 true,则 size 必须是 4 的倍数,创建时立刻映射,让 CPU 端能读写数据
});
// 2、复制目标/复制源类型的 GPUBuffer
const arrayBuffer = verticesBuffer.getMappedRange();
// 通过 TypedArray 向 ArrayBuffer 写入数据(从 CPU 到 GPU)
// 将顶点数据写入到上面建立的缓冲区对象
new Float32Array(arrayBuffer).set(cubeVertexArray);
// 解除显存对象的映射,稍后它就能在 GPU 中进行复制操作
verticesBuffer.unmap();
// 管线组装
const pipeline = device.createRenderPipeline({
layout: "auto", // 渲染管线的布局
vertex: {
module: device.createShaderModule({
code: basicVertWGSL
}),
entryPoint: "main",
buffers: [ // 这里的 buffers 属性就是缓冲区集合,其中一个元素对应一个缓冲对象
{
arrayStride: cubeVertexSize, // 顶点长度 以字节为单位
attributes: [
{
// position
shaderLocation: 0, // 遍历索引,这里的索引值就对应的是着色器语言中 @location(0) 的数字
offset: cubePositionOffset, // 偏移
format: "float32x4" // 参数格式
},
{
// uv
shaderLocation: 1, // 这里的索引值就对应的是着色器语言中 @location(1) 的数字
offset: cubeUVOffset,
format: "float32x2"
}
]
}
]
},
fragment: {
module: device.createShaderModule({
code: vertexPositionColorWGSL
}),
entryPoint: "main",
targets: [
{
format: presentationFormat
}
]
},
primitive: {
// topology: "line-list"
// topology: "line-strip"
// topology: "point-list"
topology: "triangle-list",
// topology: "triangle-strip"
// Backface culling since the cube is solid piece of geometry.
// Faces pointing away from the camera will be occluded by faces
// pointing toward the camera.
// 相关定义为:
// enum GPUFrontFace {
// "ccw",
// "cw"
// };
// enum GPUCullMode {
// "none",
// "front",
// "back"
// };
// ...
// dictionary GPURasterizationStateDescriptor {
// GPUFrontFace frontFace = "ccw";
// GPUCullMode cullMode = "none";
// ...
// };
// 开启面剔除
// 其中ccw表示逆时针,cw表示顺时针;frontFace用来设置哪个方向是“front”(正面);cullMode用来设置将哪一面剔除掉。
// 因为本示例没有设置frontFace,因此frontFace为默认的ccw,即将顶点连接的逆时针方向设置为正面;
// 又因为本示例设置了cullMode为back,那么反面的顶点(即顺时针连接的顶点)会被剔除掉。
cullMode: "back"
},
// Enable depth testing so that the fragment closest to the camera
// is rendered in front.
depthStencil: {
// 开启深度测试
depthWriteEnabled: true,
// 设置比较函数为 less
depthCompare: "less",
// 设置depth为24bit
format: "depth24plus"
}
});
const depthTexture = device.createTexture({
size: [canvas.width, canvas.height],
format: "depth24plus",
usage: GPUTextureUsage.RENDER_ATTACHMENT
});
const uniformBufferSize = 4 * 16; // 4x4 matrix
// 创建 UBO GPU
// COPY_DST 通常就意味着有数据会复制到此 GPUBuffer 上,这种 GPUBuffer 可以通过 queue.writeBuffer 方法写入数据
// 片元着色器传递数据:如 const color = new Float32Array([1, 0, 0, 1]) 表示一个颜色
// 为颜色 创建缓冲区对象,设置其尺寸和用途,使其作用于片元着色器,并可写
const uniformBuffer = device.createBuffer({
size: uniformBufferSize,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST
});
// 通过打组,可以很方便地将某种条件下的一组 uniform 资源分别传入着色器进行 WebGPU 渲染编程。
// GPUBindGroup 的最大作用,就是隔离不相关的 uniform,把相关的资源摆在一块。
const uniformBindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0), // 指定绑定组的布局对象,渲染管线的布局
entries: [
{
binding: 0,
resource: {
buffer: uniformBuffer // 传入 UBO
}
}
]
});
const renderPassDescriptor: GPURenderPassDescriptor = {
colorAttachments: [
{
view: undefined, // Assigned later
clearValue: {
r: 0.5, g: 0.5, b: 0.5, a: 1.0 },
// loadOp和storeOp决定渲染前和渲染后怎样处理attachment中的数据。
loadOp: "clear", // load 的意思是渲染前保留attachment中的数据,clear 意思是渲染前清除
storeOp: "store" // 如果为“store”,意思是渲染后保存被渲染的内容到内存中,后面可以被读取;如果为“clear”,意思是渲染后清空内容。
}
],
depthStencilAttachment: {
view: depthTexture.createView(),
// 在深度测试时,gpu会将fragment的z值(范围为[0.0-1.0])与这里设置的depthClearValue值(这里为1.0)比较。其中使用depthCompare定义的函数(这里为less,意思是所有z值大于等于1.0的fragment会被剔除)进行比较。
depthClearValue: 1.0,
depthLoadOp: "clear",
depthStoreOp: "store"
}
};
// 因为是固定相机 所以只需要计算一次 projection 矩阵
const aspect = canvas.width / canvas.height;
const projectionMatrix = mat4.create();
mat4.perspective(projectionMatrix, (2 * Math.PI) / 5, aspect, 1, 100.0);
// 计算 mvp 矩阵
function getTransformationMatrix() {
const viewMatrix = mat4.create();
mat4.translate(viewMatrix, viewMatrix, vec3.fromValues(0, 0, -4));
const now = Date.now() / 1000;
mat4.rotate(
viewMatrix,
viewMatrix,
1,
vec3.fromValues(Math.sin(now), Math.cos(now), 0)
);
const modelViewProjectionMatrix = mat4.create();
mat4.multiply(modelViewProjectionMatrix, projectionMatrix, viewMatrix);
return modelViewProjectionMatrix as Float32Array;
}
function frame() {
if (!context) return;
const transformationMatrix = getTransformationMatrix();
// 写入:从 CPU 到 GPU
// 将颜色数据/旋转数据 写入到缓冲区对象
device.queue.writeBuffer(
uniformBuffer, // 传给谁
0,
transformationMatrix.buffer, // 传递 ArrayBuffer
transformationMatrix.byteOffset, // 从哪里开始
transformationMatrix.byteLength // 取多长
);
renderPassDescriptor.colorAttachments[0].view = context
.getCurrentTexture()
.createView();
// 创建一个i名为 commandEncoder 的指令编码器,用来复制显存
// 我们不能直接操作command buffer,需要创建command encoder,使用它将多个commands(如render pass的draw)设置到一个command buffer中,然后执行submit,把command buffer提交到gpu driver的队列中。
// command buffer有
// creation, recording,ready,executing,done五种状态。
// 根据该文档,结合代码来分析command buffer的操作流程:
// const commandEncoder = device.createCommandEncoder()这个语句:创建command encoder时,应该是创建了command buffer,它的状态为creation;
// const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor)这个语句:开始render pass(webgpu还支持compute pass,不过这里没用到),command buffer的状态变为recording;
// passEncoder.setPipeline(pipeline) 这个语句:将“设置pipeline”、“绘制”的commands设置到command buffer中;
// passEncoder.end() 这个语句:(可以设置下一个pass,如compute pass,不过这里只用了一个pass);
// commandEncoder.finish() 这个语句:将command buffer的状态变为ready;
// device.queue.submit 这个语句:command buffer状态变为executing,被提交到gpu driver的队列中,不能再在cpu端被操作;
// 如果提交成功,gpu会决定在某个时间处理它。
const commandEncoder = device.createCommandEncoder();
// 建立渲染通道,类似图层
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
// 传入渲染管线
passEncoder.setPipeline(pipeline);
// draw 之前设置 bind group
passEncoder.setBindGroup(0, uniformBindGroup);
// VBO 要通过 passEncoder 的 setVertexBuffer 方法写入数据
// 有时还要配合 GPUBufferUsage.INDEX 即 索引缓存 来使用
// 通道编码器中指定坐标缓存、颜色缓存
// 写入顶点缓冲区
passEncoder.setVertexBuffer(0, verticesBuffer);
// 绘图:指定绘制的顶点个数
passEncoder.draw(cubeVertexCount, 1, 0, 0);
passEncoder.end();
// 提交写好的复制功能的命令
// commandEncoder.finish(): 结束指令编写,并返回 GPU 指令缓冲区
// device.queue.submit:向 GPU 提交绘图指令,所有指令将在提交后执行
device.queue.submit([commandEncoder.finish()]);
requestAnimationFrame(frame);
}
requestAnimationFrame(frame);
};
const canvas = document.getElementById("gpucanvas") as HTMLCanvasElement;
init({
canvas: canvas });
代码仓库地址:TianWebGPU
五、参考
canvas-output-multiple-adapters
OpenGL ES VAO、VBO、EBO、FBO、PBO、TBO、UBO