目录
Postgres数据备份的三种方式及比较
根据归档命令进行备份,通常备份会落后一个WAL日志文件。
② 流复制
流复制也叫物理复制,可以从实例级复制出一个与主库一模一样的实例级的从库。流复制同步模式有同步、异步两种。
> 异步复制,可以做到较好的性能,而它的劣势是:主库如果宕机,或从库被激活成主库,部分 WAL 没有发送到从库,可能造成数据丢失。
> 同步复制,能够保证主库上所有事务的修改都能被传送到从库,提高了数据复制安全性的同时也降低了性能。
③ 逻辑复制
区别于物理复制的是物理复制是基于实例级的复制,只能复制整个PostgreSQL实例,而不能基于部分库及表。从PostgreSQL10开始,出现了基于表级别的复制,即逻辑复制。
① 原理
默认状态下的流复制是以异步模式工作的,主库写WAL日志,通过wal sender进程把WAL日志发送给从库的wal receiver进程,wal receiver接收到WAL日志,并持久化到存储。
从库的startup进程恢复写到磁盘上的WAL日志,把数据apply到数据页面上实现主从数据同步。在流复制的异步模式的基础上,同步模式还指定事务提交的同步级别:remote_write保证该事务的所有数据被从库收到,从库收到数据并调用write写磁盘,但并未持久化到磁盘;remote_apply保证该事务的所有数据在从库被恢复到数据页面。
注:以下三张图来自网络
PG主备总体框架图:

PG流复制过程:

PG standby模式和apply日志过程:

② 配置
主库与从库版本都是psql10.11
1.修改主库配置文件postgresql.conf
注:除了基础参数,还至少需要如下参数
listen_addresses = '*'
wal_level = replica
max_connections = 100
archive_mode = on
archive_command = 'test ! -f /mnt/server/archive/%f && cp %p /mnt/server/archive/%f'
max_wal_senders = 10
wal_keep_segments = 60
hot_standby = on
上述参数中有涉及归档日志的路径,需手动创建
mkdir -p /mnt/server/archive/
参数说明:
listen_address:按需设置,本次测试配置为所有主机均可以访问,生产环境可以按需配置网段wal_level:设置流复制模式至少设置为replica
archive_mode: 本次启用归档
archive_command:WAL日志归档命令,生产环境可以将归档拷贝到对应目录或其他机器上,本次测试配置为归档到本机的另一个目录下
max_wal_senders:最大WAL发送进程数,此数量需大于等于从库个数且比max_connections小。
wal_keep_segments:pg_wal目录下保留WAL日志的个数,每个WAL文件默认16M,为保障从库能在应用归档落后时依旧能追上主库,此值建议设置较大一点。
hot_standby:此参数控制在恢复归档期间是否支持只读操作,设置为ON后从库为只读模式。
2.主库创建复制账号
Postgres=# CREATE ROLE replicauser login replication encrypted password 'replicauser';
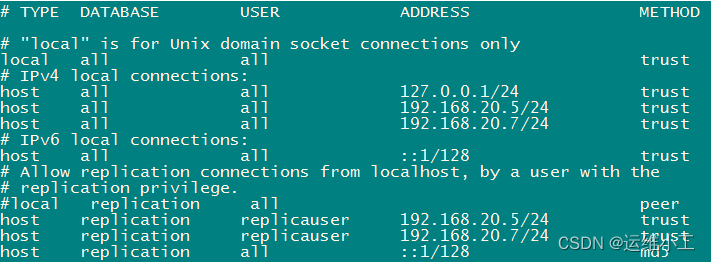
3.修改主库配置文件pg_hba.conf
主库服务器192.168.20.7/24 从库服务器 192.168.20.5/24
允许用户replicauser连接replication
4.重启主库服务
#su postgres
/usr/pgsql-10/bin/pg_ctl reload -D /var/lib/pgsql/10/data/
/usr/pgsql-10/bin/pg_ctl restart -D /var/lib/pgsql/10/data/
5.从机在线备份主库数据
将数据放在指定路径,此路径建议与主库路径一致,在执行以下命令前将从库中/var/lib/pgsql/10/data目录移走清空,执行完毕该命令后从库该路径下保存的是主库的数据,其中pg_wal保存到最近的WAL日志
[root@centos7min2 bin]# su postgres
bash-4.2$ ./pg_basebackup -h 192.168.20.7 -U replicauser -p 5432 -F p -X s -v -P -R -D /var/lib/pgsql/10/data/ -l postgres32
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/13000028 on timeline 2
pg_basebackup: starting background WAL receiver
32368/32368 kB (100%), 1/1 tablespace
pg_basebackup: write-ahead log end point: 0/130000F8
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: base backup completed

pg_basebackup命令中的参数说明:
-h 指定连接的数据库的主机名或IP地址,这里就是主库的ip
-U 指定连接的用户名,此处是我们刚才创建的专门负责流复制的repl用户
-F 指定生成备份的数据格式,支持p(plain原样输出)或者t(tar格式输出)
-X 表示备份开始后,启动另一个流复制连接从主库接收WAL日志,有 f(fetch)和s (stream)两种方式,建议使用s方式
-P 表示显示数据文件、表空间传输的近似百分比 允许在备份过程中实时的打印备份的进度
-v 表示启用verbose模式,命令执行过程中会打印各阶段日志,建议启用
-R 表示会在备份结束后自动生成recovery.conf文件,这样也就避免了手动创建
-D 指定把备份写到哪个目录,这里尤其要注意一点就是做基础备份之前从库的数据目录(/var/lib/pgsql/10/data)目录需要手动清空
-l 表示指定个备份的标识,运行命令后可以看到进度提示
6.修改从库配置文件recovery.conf
该配置文件由pg_basebackup命令自动生成,也可从/usr/pgsql-10/share/
recovery.conf.sample拷贝,并做如下调整
[root@centos7min2 data]# cat recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=replicauser host=192.168.20.7 port=5432 password=replicauser'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover'
参数说明:
standby_mode: 设置是否启用数据库为备库,如果设置成on,备库会不停地从主库上获取WAL日志流,直到获取主库上最新的WAL日志流
primary_conninfo:设置主库的连接信息,这里设置了主库IP、端口、用户名信息等,此处是明文密码,生产环境建议配置非明文密码,而是将密码配置在另一个隐藏文件中
recovery_target_timeline: 设置恢复的时间线(timeline),默认情况下是恢复到基准备份生成时的时间线,设置成latest表示从备份中恢复到最近的时间线,通常流复制环境设置此参数为latest,复杂的恢复场景可将此参数设置成其他值
trigger_file: 若trigger_file指定的文件存在,recovery.conf切换为recovery.done,主从切换
7.重启从库服务
pg_ctl restart 失败,通过postmaster 启动成功
bash-4.2$ ./pg_ctl restart -D /var/lib/pgsql/10/data/
pg_ctl: PID file "/var/lib/pgsql/10/data/postmaster.pid" does not exist
Is server running?
starting server anyway
pg_ctl: could not read file "/var/lib/pgsql/10/data/postmaster.opts"
/usr/pgsql-10/bin/postmaster -D /var/lib/pgsql/10/data/
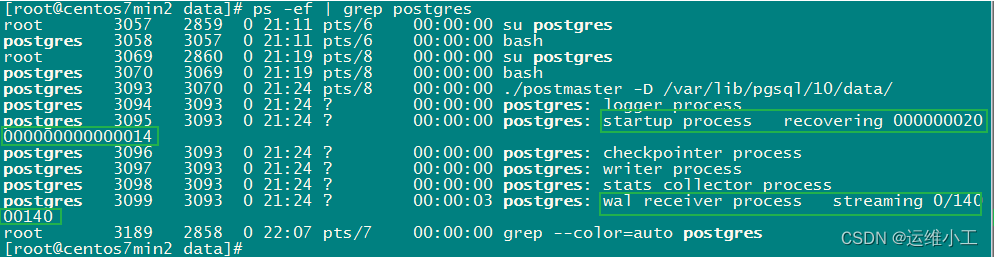
8.查看主从数据库服务,WAL日志与主从标识
主库
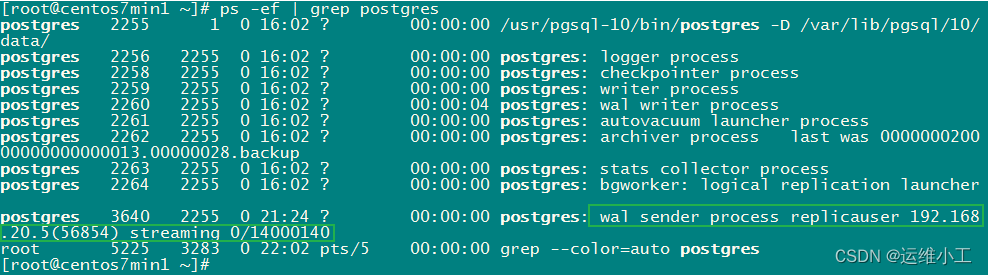
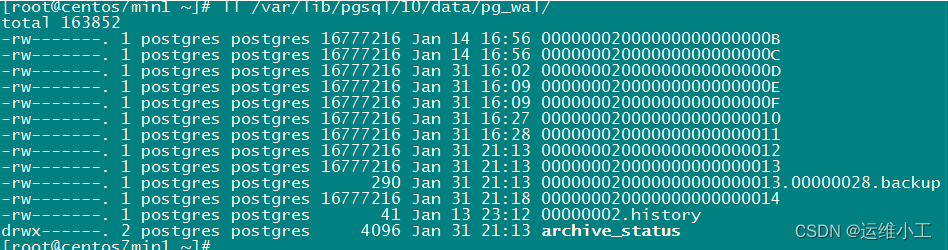
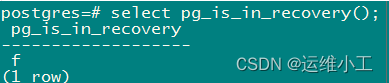
从库


9.同步测试
主库创建数据库test, 从库同步新增该数据库信息


10.同步流复制
以上配置可实现异步流复制,pg_stat_replication表字段sync_state = async.

1)设置application_name
更新备库配置文件 recovery.conf 中的 primary_conninfo 参数,默认值为 walreceiver ,需要指定该实例的 application_name
[root@centos7min2 data]# cat recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=replicauser host=192.168.20.7 port=5432 password=replicauser application_name=standby01'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover'
2)重启从库服务后主库查询状态

3)修改主库的postgres.conf
synchronous_standby_names = 'standby01'
synchronous_commit = remote_apply # synchronization level;
# off, local, remote_write, remote_apply, or on
4)重启主库服务后查询同步状态
sync_state = sync

③ 取消主从同步流复制
如果需要取消主从同步流复制,只需将从库数据库数据目录下的recovery.conf移走或删除,再重启从库的postgres服务即可。
查看从库postgres进程与同步标识
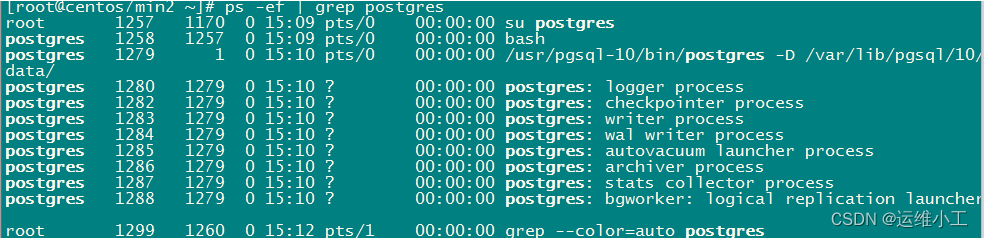

查看主库postgres进程与同步标识


④ 重新设置主从同步流复制
如果需要重新设置主从同步复制,则需要根据②配置去一步一步重新设置。如果只移除了recovery.conf,则可以将其恢复后重启主从数据库服务即可。