一、简介
1.MQ的概念
MQ全称 Message Queue(消息队列),是在消息的传输过程中保存消息的容器。多用于分布式系统之间进行通信。是一种“先进先出”的数据结构。
2.MQ模型
生产者将消息发送给MQ。 MQ将消息推送给指定消费者,或者消费者去MQ拉特定的消息。 生产者和消费者又可以成为客户端,相对应MQ就是服务端

3.MQ与redis、传统数据库的区别
MQ消息队列服务:针对数据更改场景、功能比其他两者弱(发数据、取数据),是数据的临时中转地,主要用于新增、删除、或者及其少量的查询功能;处理速度比传统数据库快(操作更简单、没这么多约束。高性能的最重要原因:MQ操作是顺序读写为主,数据库是随机读取磁盘)
redis缓存技术:处理速度快,使用内存机制,主要针对查询场景
传统的数据库:事务支持、持久存储、数据管理场景
4.常见的MQ
常见的MQ主要有activemq、rabbitmq、kafka、rocketmq
这里主要使用rocketmq,是阿里主导的,官网文档:https://rocketmq.apache.org/zh/docs/
二、MQ的作用
1.解耦
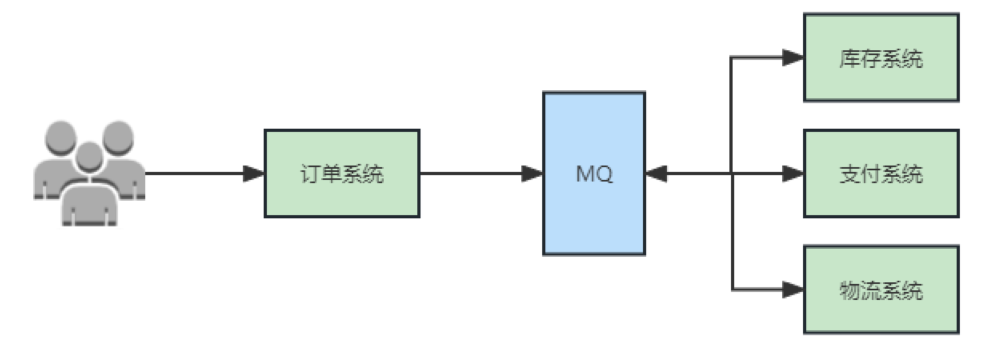
当 A 系统生产关键数据,发送数据给多个其他系统消费,此时 A 系统和其他系统产生了严重的耦合,如果将 A 系统产生的数据放到 MQ 当中,其他系统去 MQ 获取消费数据,此时各系统独立运行只与 MQ 交互,添加新系统消费 A 系统的数据也不需要去修改 A 系统的代码,达到了解耦的效果。
使用MQ后,将不同应用之间的调用解耦,提高系统容错性。如图,订单系统直接将订单消息发给MQ就结束了。 其他系统从MQ获取订单信息处理
2.异步提速
不同依赖服务之间的通信异步化,可以提高整个系统的吞吐量。如下图,不适用MQ时,单个请求总耗时20ms+3*300ms,使用MQ以后,20+5+300

3.削峰填谷
使用了 MQ 之后,限制消费消息的速度为1000,这样一来,高峰期产生的数据势必会被积压在 MQ 中,高峰就被“削”掉了,但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000,直到消费完积压的消息,这就叫做“填谷”。

三、监控体系
下载rocketmq-console的jar包:https://download.csdn.net/download/qq_38571773/87388867
下载jar包后,启动命令:
java -jar -Dserver.port=9981 -Drocketmq.namesrv.addr=ip:端口号 rocketmq-console-ng-1.0.1.jar # ip和端口号,为rocketmq部署时, 启动NameServer的服务器ip和端口号,默认端口是9876启动后,可通过端口号进行访问:

主要查看主题top,主题为某一类的存放的统一标记,类似数据库里面的表。
消费者tab下,主要关注TPS和延迟,TPS为消费者程序中,每秒钟处理了多少的MQ消息;
延迟为堆积的MQ消息,等待消费者消费。

四、MQ架构测试注意事项
1.异步导致的延时性
不同的业务,对响应时间的关心程度不一样。所以需要根据具体业务情况,考虑是否接受采用异步导致的延迟时间
例如,点完外卖,评价送积分--->1)、先提交评价 ;2)、修改用户的积分
由于对增加积分的时间要求没这么高-->程序设计: 将 积分的相关操作设计为 异步操作
2.消息丢失
2.1消息模式类型:
sync同步模式:发送消息采用同步模式,这种方式只有在消息完全发送完成之后才返回结果,此方式存在需要同步等待发送结果的时间代价,具有内部重试机制
async同步模式:发送消息采用异步发送模式,消息发送后立刻返回,当消息完全完成发送后,会调用回调函数sendCallback来告知发送者本次发送是成功或者失败。异步模式通常用于响应时间敏感业务场景,即承受不了同步发送消息时等待返回的耗时代价;异步模式也在内部实现了重试机制,默认次数为2次-->针对网络问题调用失败
测试的时候要注意, 如果发送完毕之后,程序就挂掉了, 对于数据处理是否存在问题
异步发送消息代码之后,MQ不一定收到,而继续处理后面的代码 (理论上来说,上一个操作成功, 才能进行下一步操作),因为性能的考虑, 进行异步的MQ消息发送,可能会出现: MQ发送失败,而后面的操作成功了
往往程序设计, 要在接受 MQ 确认没问题的消息之后,进行一系列具体数据的处理;收到 MQ 处理失败的callback回调消息之后,要进行相对应重试设计
one-way生产者单向发送:采用one-way发送模式发送消息的时候,发送端发送完消息后会立即返回,不会等待来自broker的ack来告知本次消息发送是否完全完成发送。这种方式吞吐量很大,但是存在消息丢失的风险,所以其适用于不重要的消息发送,比如日志收集
2.2 MQ服务器的刷盘类型
收到数据 ,最终要持久化到 磁盘,存在两种方式落盘:
SYNC_FLUSH(同步刷新):MQ收到消息之后,写入磁盘
ASYNC_FLUSH(异步处理):MQ收到信息,保存在内存,定时批量写入磁盘
3.幂等性
幂等性包含两次语义:1)一个消息最少被消费一次; 2)一个消息只会被成功消息一次
因为消息发送的,有重试机制,可能导致 同一条消息 发送多遍。
所以消费者收到消息之后,要检查是否重复处理,使用业务上的唯一ID,如支付ID、交易号、订单号、消息编码等来进行检查
4.通过MQ做系统解耦
如果通过MQ进行系统拆分,本质来讲就是分布式架构,需要监控多个系统而不是只看 接口后台
五、瓶颈分析
1.资源问题
1.1. MQ -- 高并发 数据 存取, 网络要求不低公司的消息内容很大
1.2. CPU、内存、磁盘不够--可考虑集群架构
2.Rocket MQ 本身资源
MQ是用java 语言开发的, 堆内存优化查看官方手册:https://rocketmq.apache.org/zh/docs/bestPractice/19JVMOS
3.消息积压
当 生产者 发送大量数据到MQ, 消费者处理能力跟不上,就会导致积压,可以通过检查消费者程序的 处理逻辑 或者 消费者程序所在的服务器 资源是否够用

六、调优建议
所有MQ的调优 都包含 使用的调优 以及 MQ本身的配置调优
主要调优手段来自官方文档:https://rocketmq.apache.org/zh/docs/bestPractice/15bestpractice