本文介绍了NetCDF文件格式,并详细讲解了如何使用Python对NetCDF文件进行读写操作,进而介绍了NetCDF文件的地理参考,最后以两个数据为例讲解了怎么将NetCDF格式的数据转GeoTIFF格式的数据(.nc文件转为.tif文件)。
1 什么是栅格数据
栅格数据是根据一定规则将地理空间分割成有规律且大小相同的网格,每一个网格称为一个像元,并在各像元上赋予相应的属性值来表示实体的一种数据形式。每一个像元的位置由它的行列号定义,所表示的实体位置隐含在栅格行列位置中。每个栅格像元都有一个值,代表由其行列数所决定的该位置上的实体的某一特征,如果像元在栅格数据所表示的实体的范围之外,则其像元值为no data或null。栅格数据可能包含多个波段,各个波段具有相同的行列数,反映同一范围下实体在不同方面的信息。
在栅格结构中,点用一个栅格像元表示;线状地物则用沿线走向的一组相邻的栅格像元表示,每个栅格像元最多只有两个相邻像元在线上;面状地物用标记有区域属性的相邻栅格像元的集合表示,每个栅格像元可以有多于两个的相邻像元。栅格像元最常用的形状为正方形,此外也有长方形、三角形、六边形等。遥感影像就属于典型的栅格结构,其中每个像元的数字表示影像的灰度等级。
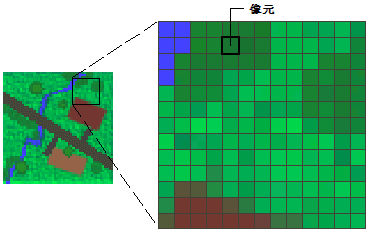
栅格数据结构的特点是属性明显、定位隐含,即数据直接记录属性值,而所在位置则根据行列号转换为相应的坐标。由于栅格结构是按照一定的规则排列的,因此其所表示实体的位置很容易隐含在网格文件的存储结构中,每个存储单元的行列位置可以根据其在文件中的记录位置得到,而行列坐标可以很容易地转换成任意坐标系下的坐标。
2 NetCDF文件格式介绍
NetCDF全称为Network Common Data Format,即网络通用数据格式,它是由美国大学大气研究协会的Unidata项目科学家针对科学数据的特点开发的,是一种面向数组型并适于网络共享的数据描述和编码标准。NetCDF文件格式设计伊始的目的是用于存储气象科学中的数据,由于其可以对网络数据进行高效地存储、管理、获取和分发等操作的特点,目前被广泛应用于大气科学、水文、环境模拟、地球物理等诸多领域。
从数学关系上看,NetCDF数据格式中存储的数据具有多对一的函数关系,"多"是指维,"一"是指变量值,这种数据结构的最大特点是能够方便地使用多维矩阵。例如,某个气象站点记录的随时间变化的温度数据以一维数组的形式存储,某个区域内在指定时间的温度以二维数组的形式存储,某个区域内随时间变化的温度用三维数组存储,某个区域内随时间和高度变化的温度用四维数组存储。Python中有一系列的工具可以操作和使用 NetCDF数据,其中常用的由netCDF4和xarray等,本文只介绍 netCDF4。
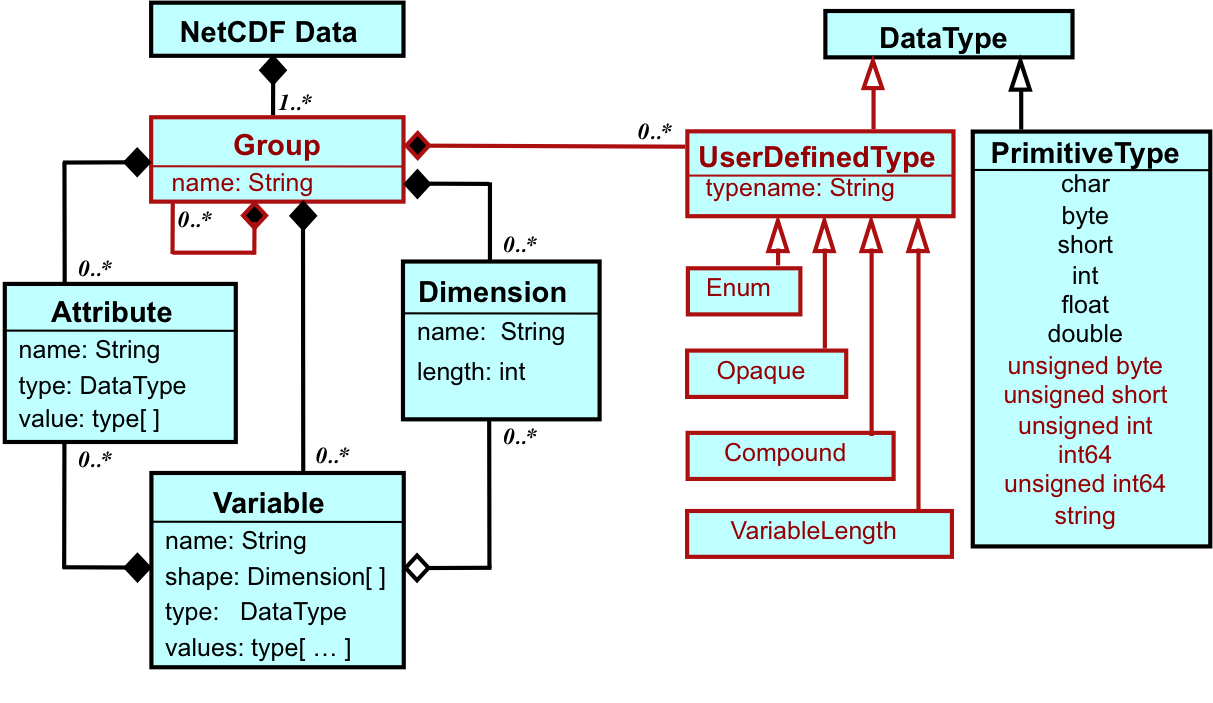
NetCDF文件后缀一般为.nc或.nc4,数据结构包含组(Groups)、维(Dimensions)、变量(Variables)和属性(Attributes)四种描述类型。
- Groups:类似于
unix文件系统的目录结构,以/开始,称为根组,所有的变量都包含在其下。请注意,NetCDF有很多版本,仅NetCDF 4支持创建Group。 - Dimensions:维对应着变量中自变量的取值范围,NetCDF根据维度定义所有变量的大小,因此在创建任何变量之前,必须先创建它们使用的维度。
- Variables:类似与numpy数组,但是Variables的维度是由Dimensions指定的。
- Attributes:变量和维在NetCDF中只是无量纲的数字,因此必须采用某种方式来让人们明白这些数字的含义,属性在这里就派上用场了。
综上所述,一个典型的NetCDF文件的数据结构如下所示:
3 NetCDF文件的基本信息
3.1 创建/打开/关闭一个NetCDF文件
NetCDF和zip、jpeg、bmp文件格式类似,都是一种文件格式的标准。在NetCDF的基础上,随着软硬件和应用场景的变化,逐渐发展出了多个版本,不同版本的文件格式各有不同。目前netCDF4支持以下版本:NETCDF3_CLASSIC,NETCDF3_64BIT_OFFSET,NETCDF3_64BIT_DATA,NETCDF4_CLASSIC和NETCDF4。其中,NETCDF3_CLASSIC是原始的NetCDF二进制格式,缺陷是文件大小不能超过2G,之后的格式没有此限制。NETCDF4_CLASSIC和NETCDF4格式支持HDF5,能够读取HDF5的库也可以处理这两种格式,因此使用h5py可以读取NETCDF4_CLASSIC和NETCDF4格式的文件,但不能新建该格式的文件。
打开或创建一个NetCDF文件需要使用netCDF4的Dataset类,使用方法类似于Python的open函数,一般需要传入两个参数,一个是要打开或创建的文件的路径(filename);另一个则是打开文件的模式(mode),共有如下几种:
| mode | 说明 |
|---|---|
| r | 只读,文件必须存在,此为默认的 mode |
| r+ | 读写,文件必须存在 |
| w | 创建新文件写,已经存在的文件会被覆盖掉 |
| a | 打开已经存在的文件进行读写,如果不存在则创建一个新文件读写 |
在下面的代码中,我们先导入netCDF4模块,后用该模块以只读的方式打开了示例数据。
>>> from netCDF4 import Dataset
>>> rootgrp = Dataset("./test.nc", "r")
>>> print(rootgrp.data_model)
NETCDF4
>>> rootgrp.close()
netCDF4.Dataset类的返回值rootgrp是一个netCDF4的数据集示例,其既是文件的根目录,也是文件的入口。数据集是组、维度、变量和属性的容器,它们一起描述了数据的含义以及存储在NetCDF文件中的数据字段。数据集的data_model记录了NetCDF 文件的版本,close()方法用于关闭文件。
3.2 NetCDF文件的组
NetCDF在第四个版本中增加了对分层组织数据的支持,即Group,类似于文件系统中的目录。Group是变量、维度和属性以及其他组的容器。数据集是一个特殊的组,一般被称为“根组”,类似于unix文件系统中的根目录。若要在一个数据集或者组下创建新的组,需要使用数据集或组实例的createGroup()方法。该方法只有一个参数,即包含新组名称的Python字符串。
在下面的代码中,我们首先创建了一个名为test.nc的文件,进而在文件的根组下使用createGroup()方法创建了两个新组,该方法的返回值为新建的组的实例。
>>> rootgrp = Dataset("test.nc", "a")
>>> fcstgrp = rootgrp.createGroup("forecasts")
>>> analgrp = rootgrp.createGroup("analyses")
>>>
数据集和组中包含的新组可以使用group属性查询,其返回结果是一个字典,该字典的键值对分别为组名和组的实例,因此可以通过group属性的返回值直接使用组名获取组的实例。此外,数据集或组实例本身也相当于一个字典,因此也可以直接通过数据集或组实例使用组名获取组的实例。
>>> print(rootgrp.groups)
{
'forecasts': <class 'netCDF4._netCDF4.Group'>
group /forecasts:
dimensions(sizes):
variables(dimensions):
groups: , 'analyses': <class 'netCDF4._netCDF4.Group'>
group /analyses:
dimensions(sizes):
variables(dimensions):
groups: }
>>> fcstgrp = rootgrp.groups["forecasts"]
>>> fcstgrp = rootgrp["forecasts"]
>>>
此外,每个组实例还有一个path属性,其中包含该组的模拟unix目录路径。为了简化嵌套组的创建,可以使用类似unix的路径作为createGroup()的参数。
>>> fcstgrp.path
'/forecasts'
>>> fcstgrp1 = rootgrp.createGroup("/forecasts/model1")
>>> fcstgrp1.path
<class 'netCDF4._netCDF4.Group'>
group /forecasts/model1:
dimensions(sizes):
variables(dimensions):
groups:
3.3 NetCDF文件的维度
NetCDF根据维度定义所有变量的大小,因此在创建任何变量之前,必须先创建它们使用的维度。在实践中不常使用的一个特例是标量变量,它没有维度。维度是使用数据集或组实例的createDimension()方法创建的。第一个参数的类型为Python字符串,用于设置维度的名称,第二个参数是非负整数值或None,用于设置维度的大小。要创建不限制大小的维度(可追加的尺寸),第二个参数需设置为None或0。在下面的例子中,时间和级别维度都是无限的。拥有多个无限维度是NetCDF 4的一个新特性,在NetCDF 3文件中只能有一个无限维度,而且必须是变量的第一个(最左边的)维度。
>>> level = rootgrp.createDimension("level", None)
>>> time = rootgrp.createDimension("time", None)
>>> lat = rootgrp.createDimension("lat", 73)
>>> lon = rootgrp.createDimension("lon", 144)
所有的维度实例都存储在Python字典中,可用dimensions属性查看,获取属性实例的方法与前文所述的获取组实例的方法类似。对维度实例使用len函数将返回该维度的当前大小,使用unlimited方法可以确定维度是否是无限制的。
>>> print(len(lon))
144
>>> print(lon.isunlimited())
False
>>> print(time.isunlimited())
True
3.4 NetCDF文件的变量
NetCDF变量的行为很像numpy模块提供的Python多维数组对象。然而,与numpy数组不同,NetCDF4变量可以沿着一个或多个“无限”维度追加。若要创建NetCDF变量,需要使用数据集或组实例的createVariable()方法。createVariable()方法有两个强制参数,变量名(Python字符串)和变量数据类型。除创建标量变量外,不能省略dimensions关键字,其用于指定变量的维度,由包含维度名称的元组(之前用createDimension创建的)给出。变量原始数据类型对应numpy数组的dtype属性,可以将数据类型指定为numpy的dtype对象,或者可以转换为numpy的dtype对象的任何对象。有效的数据类型说明符包括:“f4”(32位浮点)、“f8”(64位浮点)、“i4”(32位有符号整数)、“i2”(16位有符号整数)、“i8”(64位有符号整数)、“i1”(8位有符号整数)、“u1”(8位无符号整数)、“u2”(16位无符号整数)、“u4”(32位无符号整数)、“u8”(64位无符号整数)或“S1”(单字符字符串)。只有当文件格式为NetCDF 4时,才能使用无符号整数类型和64位整数类型。
维度本身通常也被定义为变量,称为坐标变量。createVariable方法用于创建和返回变量类的实例,该实例可在以后用于访问和设置变量的数据和属性。
>>> times = rootgrp.createVariable("time", "f8", ("time",))
>>> levels = rootgrp.createVariable("level", "i4", ("level",))
>>> latitudes = rootgrp.createVariable("lat", "f4", ("lat",))
>>> longitudes = rootgrp.createVariable("lon", "f4", ("lon",))
>>> # two dimensions unlimited
>>> temp = rootgrp.createVariable("temp", "f4", ("time","level","lat","lon",))
与创建新的组类似,可以使用路径在组的层次结构中创建新变量。数据集或组中的所有变量的实例都存储在Python字典中,存储方式与组和维度相同,可使用variables属性查看。如果路径中有组尚不存在,将会自动创建它们。还可以使用路径直接查询数据集或组实例,并以获得组或变量实例。
>>> ftemp = rootgrp.createVariable("/forecasts/model2/temp", "f4", ("time",))
>>> print(rootgrp["/forecasts/model2/temp"]) # a Variable instance
<class 'netCDF4._netCDF4.Variable'>
float32 temp(time)
path = /forecasts/model2
unlimited dimensions: time
current shape = (0,)
filling on, default _FillValue of 9.969209968386869e+36 used
3.5 NetCDF文件的属性
NetCDF文件中有两种类型的属性,全局属性和变量属性。全局属性提供一个组或整个数据集的信息。变量属性提供某个变量的信息。通过为数据集或组实例属性赋值来设置全局属性,通过给变量实例属性赋值来设置变量属性。属性可以是字符串、数字或序列。如下面的例子所示,
>>> import time
>>> rootgrp.description = "bogus example script"
>>> rootgrp.history = "Created at " + time.ctime(time.time())
>>> rootgrp.source = "netCDF4 python module tutorial"
>>> latitudes.units = "degrees north"
>>> longitudes.units = "degrees east"
>>> levels.units = "hPa"
>>> temp.units = "K"
>>> times.units = "hours since 1900-01-01 00:00:00.0"
>>> times.calendar = "gregorian"
数据集、组或变量实例的ncattrs()方法可用于检索所有属性的名称。提供这个方法是为了方便,因为使用Python内置的dir()函数将返回一堆私有方法和属性,而用户不能(或者不应该)修改这些方法和属性。此外,数据集、组或变量实例的__dict__属性的返回值是一个Python字典,包含所有NetCDF属性的名称和值。
>>> for name in rootgrp.ncattrs():
... print("Global attr {} = {}".format(name, getattr(rootgrp, name)))
Global attr description = bogus example script
Global attr history = Created Mon Jul 8 14:19:41 2019
Global attr source = netCDF4 python module tutorial
4 NetCDF文件的读写操作
4.1 NetCDF文件的写入操作
我们现在有了一个NetCDF变量实例,那么如何将数据放入其中呢?你可以把它当作一个numpy数组,然后使用类似于numpy数组切片的方式给变量赋值。
>>> import numpy as np
>>> lats = np.arange(-90, 91, 2.5)
>>> lons = np.arange(-180, 180, 2.5)
>>> latitudes[:] = lats
>>> longitudes[:] = lons
与numPy的数组对象不同的是,如果在当前变量定义的索引范围之外分配数据,具有无限维的NetCDF变量将沿着这些维增长。
>>> # append along two unlimited dimensions by assigning to slice.
>>> nlats = len(rootgrp.dimensions["lat"])
>>> nlons = len(rootgrp.dimensions["lon"])
>>> print("temp shape before adding data = {}".format(temp.shape))
temp shape before adding data = (0, 0, 73, 144)
>>>
>>> from numpy.random import uniform
>>> temp[0:5, 0:10, :, :] = uniform(size=(5, 10, nlats, nlons))
>>> print("temp shape after adding data = {}".format(temp.shape))
temp shape after adding data = (5, 10, 73, 144)
>>>
>>> # levels have grown, but no values yet assigned.
>>> print("levels shape after adding pressure data = {}".format(levels.shape))
levels shape after adding pressure data = (10,)
请注意,当沿着变量temp的level维度追加数据时,即使尚未将任何数据分配给level,level变量的大小也会增加。
>>> # now, assign data to levels dimension variable.
>>> levels[:] = [1000.,850.,700.,500.,300.,250.,200.,150.,100.,50.]
4.2 单个NetCDF文件的读取操作
NumPy和netCDF变量切片规则之间存在一些差异。切片行为如常,都是start:stop:step三元组。numpy使用标量整数索引i获取第i个元素,并将输出数组的秩减少一。而对于NetCDF变量,布尔数组和整数序列索引的行为不同于numpy数组。它只允许一维布尔数组和整数序列,这些索引沿着每个维度独立工作。这意味着:
>>> temp[0, 0, [0,1,2,3], [0,1,2,3]].shape
(4, 4)
对NetCDF变量进行切片时,返回shape为(4,4)的数组,但对于numpy数组,它返回shape为(4,)的数组。类似地,用[0,array([True,False,True]),array([False,True,True,True]),:]索引一个shape为(2,3,4,5)的NetCDF变量将返回shape为(2,3,5)的数组。而在NumPy中,这会产生一个错误,因为它相当于[0,[0,1],[1,2,3],:]。当使用整数序列进行切片时,索引不需要排序(会按照索引的顺序返回值),并且可以包含重复项(这两项都是版本1.2.1中的新特性)。虽然这种行为可能会对那些习惯于NumPy的“花哨的索引”规则的人造成一些困惑,但它提供了一种非常强大的方法,即通过在维度数组上使用逻辑操作来创建切片,从而从多维NetCDF变量中提取数据。
如下面的代码所示,将提取time切片为0、2和4,气压level为850、500和200百帕,所有北半球纬度和东半球经度,返回的numpy数组的shape为(3,3,36,71)。
>>> tempdat = temp[::2, [1,3,6], lats>0, lons>0]
>>> print("shape of fancy temp slice = {}".format(tempdat.shape))
shape of fancy temp slice = (3, 3, 36, 71)
标量变量的特殊注意事项:要从没有关联维度的标量变量v中提取数据,请使用numpy.asarray(v)或v[...],结果将是一个numpy的标量数组。
默认情况下,对变量读取后的返回值为numpy掩码数组,其值等于为基元(前文介绍的数据类型)和枚举(自定义数据类型)数据类型掩码的变量按照missing_value或_FillValue属性值掩码后的值。数据集和变量实例可以使用set_auto_mask()方法来禁用此功能,以便始终返回numpy数组,但其中会包含缺少的值。在1.4.0版之前,默认行为是仅当请求的片包含缺失值时才返回掩码数组,可以使用set_always_mask()方法可以恢复此行为。如果掩码数组被写入NetCDF变量,掩码元素将被missing_value属性指定的值填充。如果变量没有missing_value,则使用_FillValue代替。
4.3 多个NetCDF文件的读取操作
如果要从跨多个NetCDF文件的变量中读取数据,可以使用MFDataset类读取数据,这样读取数据时就像数据包含在单个文件中一样。不同于使用单个文件名创建数据集实例,MFDataset类使用文件名列表或带通配符的字符串(然后使用Python的glob模块将其转换为文件的排序列表)创建MFDataset实例,将文件列表中具有相同无限维度的的变量聚集在一起,并且可以跨多个文件进行切片。
为了说明这一点,让我们首先创建一组具有相同变量名(都具有相同的无限维度)的NetCDF文件。文件必须采用NETCDF3_64BIT_OFFSET、NETCDF3_64BIT_DATA、NETCDF3_CLASSIC或NETCDF4_CLASSIC格式(MFDataset不支持NETCDF4格式)。
>>> for nf in range(10):
... with Dataset("mftest%s.nc" % nf, "w", format="NETCDF4_CLASSIC") as f:
... _ = f.createDimension("x", None)
... x = f.createVariable("x", "i", ("x",))
... x[0:10] = np.arange(nf*10, 10*(nf+1))
现在用MFDataset一次读取所有文件,需要注意的是,MFDataset只能用于读取多文件数据集,不能用于写入多文件数据集。
>>> from netCDF4 import MFDataset
>>> f = MFDataset("mftest*nc")
>>> print(f.variables["x"][:])
[ 0 1 2 ...... 96 97 98 99]
5 NetCDF文件的地理参考
一个NetCDF变量的地理参考与该变量的维度相关联,用于空间定位的维度被称为坐标维度。坐标维度必须是独立变化的维度,同时有一个和其名称相同的变量并且该变量的维度就是这个用于空间定位的维度,这个变量被称为坐标变量。坐标变量最常见的用途是在空间和时间上定位数据,但可以为数据变量所依赖的任何其他连续地球物理量(例如密度、温度、辐射波长、天顶辐射角、海面波频率)或离散类别(例如区域类型、模型级别编号、集成成员编号)提供坐标。
NetCDF文件标准化的约定(COARDS)对坐标变量进行了定义,但相对而言较为简单。因此,一些学者共同制定并开源了NetCDF气候和预报(CF)元数据公约,旨在促进使用NetCDF应用程序编程器接口 NetCDF 创建的文件的处理和共享。CF公约概括并扩展COARDS公约,其目的是要求符合要求的数据集包含足够的元数据,这些元数据是自描述的,即文件中的每个变量都有对其所表示内容的相关描述,包括物理单位(如果适用),并且每个值可以位于空间(相对于基于地球的坐标)和时间中。
CF公约对四种类型的坐标变量进行了特殊处理:纬度、经度、垂直和时间。CF公约不会根据变量的名称判断一个变量是否是坐标变量,而会根据变量的units和positive属性的值判断。由于这种识别坐标类型的方法很复杂,因此CF公约提供了两种产生直接标识的可选方法。属性axis可以附加到坐标变量,并给定值 X、Y、Z或T之一,分别代表经度、纬度、垂直轴或时间轴。或者,standard_name属性可用于直接标识。但请注意,这些可选属性是对必需的COARDS元数据的补充。
要识别通用空间坐标,需要将axis属性附加到这些坐标变量中,并给定值X、Y或Z之一。轴属性的值X和Y应用于标识水平坐标变量。如果同时标识了X轴和Y轴,则X-Y-up应定义一个右手坐标系,即如果从上方观察,从正X方向到正Y方向的旋转是逆时针的。
本文只介绍经度、维度这两种坐标变量,而又地理坐标系和投影坐标系的经度变量、纬度变量有所不同,因此本文对其进行分别介绍。此外,NetCDF文件的地理参考十分复杂,本文只对常用的知识进行简单介绍。有关NetCDF文件地理参考的详细信息,请参考NetCDF气候和预报(CF)元数据公约。
5.1 地理坐标系下的坐标变量
地理坐标系默认为WGS 84坐标系,根据变量的units属性判断一个变量是不是坐标变量,经度变量和纬度变量的units属性要求不同。
1)维度变量
表示纬度的变量必须始终显式包含units属性;没有默认值。units属性将是根据 udunits.dat 文件格式化的字符串。建议的纬度单位是degrees_north,或者degree_north、degree_N、degrees_N、degreeN和degreesN。一个典型的维度变量的属性描述如下所示:
float lat(lat) ;
lat:long_name = "latitude" ;
lat:units = "degrees_north" ;
lat:standard_name = "latitude" ;
应注意,Udunits 包无法识别units规范的"north"部分所隐含的方向性。它只识别其大小,即 1 度定义为 pi/180 弧度。因此,只能通过units确定一个变量是否为纬度变量。或者,可以通过向standard_name属性提供值latitude或向axis属性提供值Y来额外指示纬度类型。
2)经度变量
表示经度的变量必须始终显式包含units属性;没有默认值。units属性将是根据 udunits.dat 文件格式化的字符串。建议的经度单位为degrees_east,或者degree_east、degree_E、degrees_E、degreeE和degreesE。一个典型的经度变量的属性描述如下所示:
float lon(lon) ;
lon:long_name = "longitude" ;
lon:units = "degrees_east" ;
lon:standard_name = "longitude" ;
同样的,Udunits 包无法识别units规范的"east"部分所隐含的方向性。它只识别其大小,即 1 度定义为 pi/180 弧度。因此,只能通过units确定一个变量是否为精度变量。或者,可以通过向standard_name属性提供值longitude或向axis属性提供值X来额外指示经度类型。
5.2 投影坐标系下的坐标变量
数据变量可以引用格网映射变量,以便明确声明用于水平空间坐标值的坐标参考系统(CRS)。例如,如果水平空间坐标是纬度和经度,网格映射变量可用于声明其基于的椭球体(如WGS84椭球体、球体等)。如果地图投影中的水平空间坐标为东距和北距,格网映射变量将声明所使用的地图投影,并提供根据东距和北距计算纬度和经度所需的信息。
网格映射变量通过附加属性的集合提供映射的描述。它是任意类型的,因为它不包含任何数据。它的目的是作为定义映射的属性的容器。所有网格映射变量必须具有的一个属性是grid_mapping_name,它接受一个包含映射名称的字符串值。
网格映射变量通过数据变量的grid_mapping属性与数据变量相关联。此属性附加到数据变量上,以便具有不同映射的变量可以出现在单个文件中。该属性采用两种可能格式的字符串值。在第一种格式中,它是网格映射变量的名称。在第二种格式用于存储多个坐标参考系统的坐标信息,使用较少,本文不再介绍。
一个兰伯特等角投影的NetCDF文件的描述如下所示,由于x和y的standard_name属性值分别为projection_x_coordinate和projection_y_coordinate,并且其axis属性分别为X和Y,因此判断其是投影坐标变量。变量Lambert_Conformal具有grid_mapping_name属性,因此是网格映射变量,其包含作为属性的映射参数。Temperature变量具有grid_mapping属性,其值为Lambert_Conformal,即网格映射变量的名称,因此可以将其与网格映射变量相关联。
网格映射变量的属性值记录了投影信息,但不同投影的投影信息不同,将其转换为完整的投影较为复杂。因此,网格映射变量的一个可选属性为crs_wkt,包含了符合 WKT 语法的文本字符串。
dimensions:
y = 228;
x = 306;
time = 41;
variables:
int Lambert_Conformal;
grid_mapping_name = "lambert_conformal_conic";
standard_parallel = 25.0;
longitude_of_central_meridian = 265.0;
latitude_of_projection_origin = 25.0;
double y(y);
axis = "Y";
units = "km";
long_name = "y coordinate of projection";
standard_name = "projection_y_coordinate";
double x(x);
axis = "X";
units = "km";
long_name = "x coordinate of projection";
standard_name = "projection_x_coordinate";
int time(time);
long_name = "forecast time";
units = "hours since 2004-06-23T22:00:00Z";
float Temperature(time, y, x);
units = "K";
long_name = "Temperature @ surface";
missing_value = 9999.0;
coordinates = "lat lon";
grid_mapping = "Lambert_Conformal";
6 实际操作
本文提供两个NetCDF格式的文件,一个为地理坐标系,一个为投影坐标系,用于读者练手。关注公众号GeodataAnalysis,回复20230119获取示例数据和代码。
6.1 地理坐标系下的ERA5再分析数据
本文提供的ERA5数据描述如下所示,共有三个坐标变量,分别是longitude、latitude和time;其中longitude、latitude分别是经度变量和维度变量,反映了数据的空间信息,time是时间变量,反映了数据的创建时间;r是数据变量,在这个数据中是相对湿度。
dimensions:
longitude = 281;
latitude = 201;
time = 744;
variables:
float32 longitude(longitude);
units = "degrees_east";
long_name = "longitude";
float32 latitude(latitude);
units = "degrees_north";
long_name = "latitude";
int32 time(time);
long_name = "time";
units = "hours since 1900-01-01 00:00:00.0";
calendar = "gregorian";
int16 r(time, latitude, longitude);
scale_factor = 0.002545074823328961;
add_offset = 71.43526329785445;
_FillValue = -32767;
missing_value = -32767;
units = "%";
long_name = "Relative humidity";
standard_name = "relative_humidity";
current shape = (744, 201, 281);
本文使用GDAL创建GeoTIFF文件,因为数据的值是已知的,存储在变量r中。数据的坐标系也是已知的,即WGS 84坐标系。因此,我们在创建GeoTIFF文件时只需要明确仿射变换六参数即可。仿射变换六参数用于表示栅格位置(行列坐标)和地理参考坐标(经纬度)之间的关系,采用下面的关系把行/列坐标转换到地理参考空间:
X g e o = G T ( 0 ) + X p i x e l ⋅ G T ( 1 ) + Y p i x e l ⋅ G T ( 2 ) Y g e o = G T ( 3 ) + X p i x e l ⋅ G T ( 4 ) + Y p i x e l ⋅ G T ( 5 ) X_{geo} = GT(0) + X_{pixel} \cdot GT(1) + Y_{pixel} \cdot GT(2) \\ Y_{geo} = GT(3) + X_{pixel} \cdot GT(4) + Y_{pixel} \cdot GT(5) Xgeo=GT(0)+Xpixel⋅GT(1)+Ypixel⋅GT(2)Ygeo=GT(3)+Xpixel⋅GT(4)+Ypixel⋅GT(5)
式中, X p i x e l X_{pixel} Xpixel和 Y p i x e l Y_{pixel} Ypixel分别为栅格像元的行坐标(自上而下)和列坐标(自左向右); X g e o X_{geo} Xgeo和 Y g e o Y_{geo} Ygeo分别为栅格像元的东西方向和南北方向的坐标值;GT(2) 和 GT(4) 表示图像的旋转系数,在“向北”的图像中,二者都为为0; GT(1) 和GT(5) 分别是图像横向和纵向的分辨率(一般横向分辨率为正数,纵向分辨率为负数);(GT(0), GT(3)) 是栅格左上角像素在东西方向和南北方向的坐标值。
图像的分辨率可以由坐标变量的任意两个相邻的值的差的绝对值得到,左上角像素的坐标值则可以通过坐标向量的最小值和最大值的得到。详细代码如下所示:
import numpy as np
import netCDF4 as nc
from pyproj import CRS
from osgeo import gdal
in_path = "./test1.nc"
out_path = "./test1.tif"
# 获取分辨率和左上角像素坐标值
rootgrp = nc.Dataset(in_path)
lon = rootgrp['longitude'][...].data
lat = rootgrp['latitude'][...].data
x_min, y_max = lon.min(), lat.max()
x_res, y_res = abs(float(lon[1]-lon[0])), abs(float(lat[1]-lat[0]))
# 仿射变换六参数
gt = (x_min, x_res, 0, y_max, 0, -y_res)
# 获取地理坐标系
crs = CRS.from_epsg(4326)
wkt = crs.to_wkt()
# 读取数据
r = rootgrp['r']
nodata = int(r._FillValue)
r = r[...].filled(nodata)
# 计算月平均相对湿度
r = r.mean(axis=0).astype(np.int32)
# 创建GeoTIFF文件并写入数据
driver = gdal.GetDriverByName('GTiff')
ds = driver.Create(out_path, r.shape[1], r.shape[0], 1, gdal.GDT_Int32)
ds.SetGeoTransform(gt)
ds.SetProjection(wkt)
band = ds.GetRasterBand(1)
band.WriteArray(r)
band.SetNoDataValue(nodata)
ds = band = None
6.2 投影坐标系下的反演数据
本文所用的数据来源于Permafrost extent for the Northern Hemisphere,是根据MODIS、ERA5等反演的北半球永久冻土范围数据,其数据描述如下所示。该数据共有三个坐标变量,分别是x、y和time;其中x、y分别是只是东西方向和南北方向坐标值的变量,反映了数据的空间信息,time是时间变量,反映了数据的创建时间;PFR是数据变量,在这个数据中是相对湿度;polar_stereographic是网格映射变量,存储了数据的投影信息。
dimensions:
x = 14762;
y = 10353;
time = 1;
variables:
int polar_stereographic;
grid_mapping_name = "lambert_conformal_conic";
straight_vertical_longitude_from_pole = 0.0;
latitude_of_projection_origin = 90.0;
standard_parallel = 71.0;
false_easting = 0.0;
false_northing = 0.0;
crs_wkt = PROJCS["WGS 84 / Arctic Polar Stereographic",
GEOGCS["WGS 84",
DATUM["WGS_1984",
...;
float64 x(x);
standard_name = "projection_x_coordinate";
long_name = “x coordinate of projection";
units = "m";
axis = "X";
float64 y(y);
standard_name = "projection_y_coordinate";
long_name = "y coordinate of projection";
units = "m";
axis = "Y";
float64 time(time);
long_name = "time";
units = "hours since 1950-01-01 00:00:0";
calendar = "standard";
int8 PFR(time, y, x);
standard_name = "permafrost_area_fraction";
grid_mapping = "polar_stereographic";
_FillValue = 0;
current shape = (1, 10353, 14762);
将该数据转为坐标系的方法与地理坐标系的数据相同,都要明确仿射变换六参数,计算方法与上文相同。但与地理坐标系的数据不同的是,投影坐标系的数据的坐标系由网格映射变量的属性给出,要想获取其完整的投影需要根据属性的值进行转换,具体可参考NetCDF气候和预报(CF)元数据公约的附录F。本文所用的数据的网格映射变量提供了crs_wkt属性,因此可用其定义投影。
import netCDF4 as nc
from osgeo import gdal
in_path = "./test2.nc"
out_path = "./test2.tif"
# 获取分辨率和左上角像素坐标值
rootgrp = nc.Dataset(in_path)
lon = rootgrp['x'][...].data
lat = rootgrp['y'][...].data
x_min, y_max = lon.min(), lat.max()
x_res, y_res = abs(float(lon[1]-lon[0])), abs(float(lat[1]-lat[0]))
# 仿射变换六参数
gt = (x_min, x_res, 0, y_max, 0, -y_res)
# 获取地理坐标系
gr = rootgrp['polar_stereographic']
wkt = gr.crs_wkt
# 读取数据
PFR = rootgrp['PFR']
nodata = int(PFR._FillValue)
PFR = PFR[0, ...].filled(nodata)
# 创建GeoTIFF文件并写入数据
driver = gdal.GetDriverByName('GTiff')
ds = driver.Create(out_path, PFR.shape[1], PFR.shape[0], 1, gdal.GDT_Int16)
ds.SetGeoTransform(gt)
ds.SetProjection(wkt)
band = ds.GetRasterBand(1)
band.WriteArray(PFR)
band.SetNoDataValue(nodata)
ds = band = None