目录
一、感知音频编码的设计思想
1. MEPG音频编码器框架图
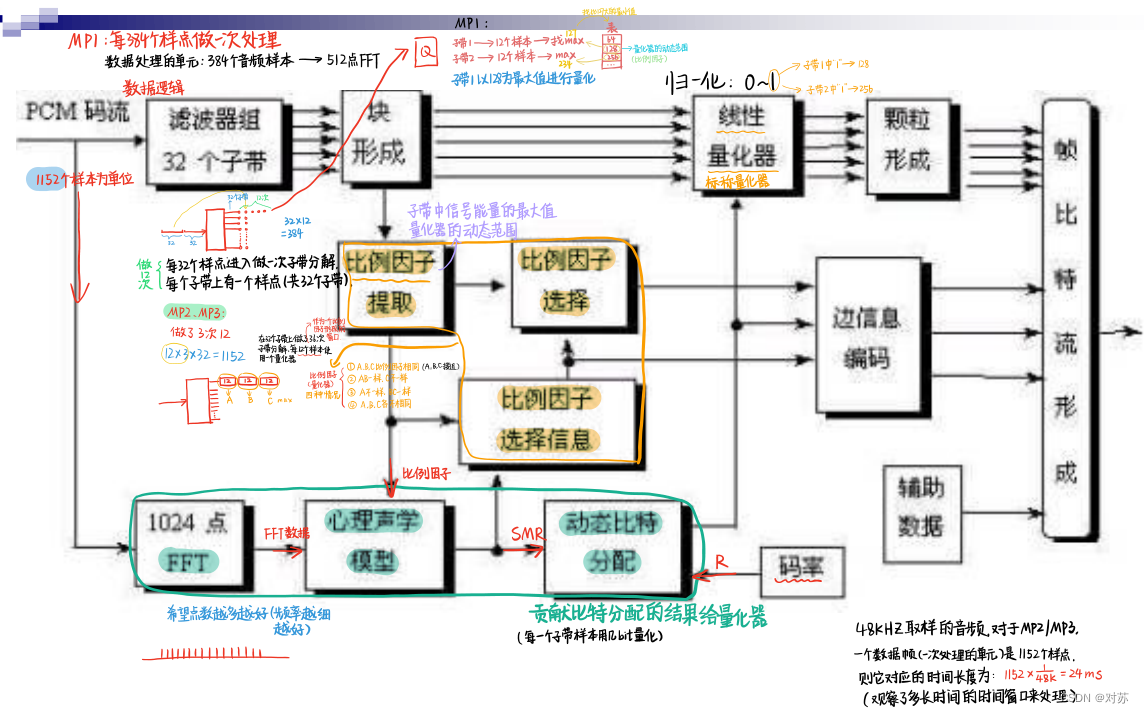
2. 多相滤波器组
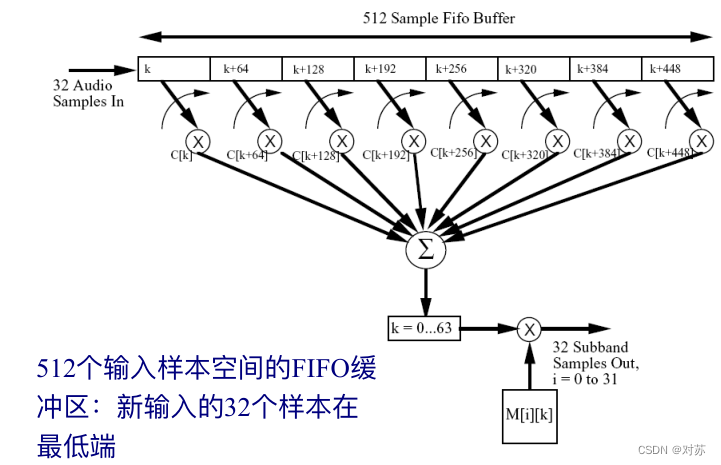
将PCM样本变换到32个子带的频域信号,每个子带上每12个样点共用一个量化器,即以12个样点为单位进行一次比例因子计算。找到12个样点中绝对值的最大值,在比例因子查找表中找到比该最大值大的最小值作为这12个样点的比例因子。
在MPEG2中,在32个子带上每个子带做了36次子带分解,每12个样本有一个比例因子,因此每个自带上共有三个比例因子,存在三个比例因子几乎相同、两个相同、各不相同的情况,若三者非常接近,则只需传输一个最大的比例因子。
3. 心理声学模型
临界频带
- 定义:当某个纯音被以它为中心频率,且具有一定带宽的连续噪声所掩蔽时,如果该纯音刚好被听到时的功率等于这一频带内的噪声功率,这个带宽称为临界频带宽度。
- 通常认为从20Hz到16KHz有25个临界频带,单位为bark,1bark=一个临界频带宽度
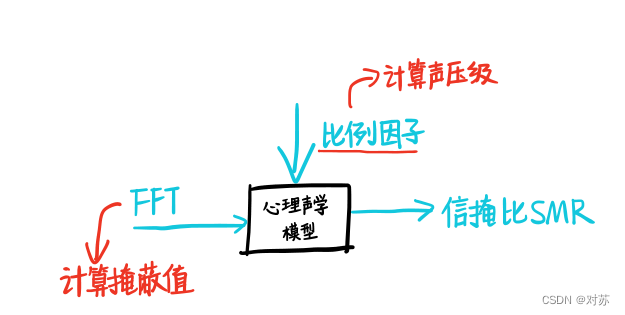
掩蔽阈值的计算
- 有乐音对乐音的掩蔽、乐音对噪声的掩蔽、噪声对乐音的掩蔽、噪声对噪声的掩蔽四种掩蔽音与被掩蔽音的组合方式。
- 计算思路:每个掩蔽音的掩蔽效果先独立变换再线性相加。
具体过程:
(1)将样本变换到频域
引入FFT补偿频率分辨率不足的问题,采用512(Layer Ⅰ)或1024(Layer Ⅱ/Ⅲ)样本窗口。
(2)确定声压级别

(3)考虑安静时阈值
即绝对阈值。在标准中有根据输入PCM信号的采样率编制的“频率、临界频带率和绝对阈值”表。此表为多位科学家经多次心理声学实验所得。
(4)将音频信号分解为“乐音”和“噪声”部分:因为两种信号的掩蔽能力不同
根据音频频谱的局部功率最大值确定乐音成分:局部峰值为乐音,然后将本临界频带内的剩余频谱合在一起,组成一个代表噪声频率(无调成份)。
(5)音调和非音调掩蔽成分的消除
利用标准中给出的绝对阈值消除被掩蔽成分;考虑在每个临界频带内,小于0.5Bark的距离中只保留最高功率的成分。
(6)单个掩蔽阈值的计算
音调成分和非音调成分单个掩蔽阈值根据标准中给出的算法求得。
(7)全局掩蔽阈值的计算

(8)每个子带的掩蔽阈值
选择出本子带中最小的阈值作为子带阈值。
对高频不正确——高频区的临界频带很宽,可能跨越多个子带,从而导致模型1将临界带宽内所有的非音调部分集中为一个代表频率,当一个子带在很宽的频带内却远离代表频率时,无法得到准确的非音调掩蔽值。但计算量低。
(9)计算每个子带信号信掩比
SMR = 信号能量 / 掩蔽阈值,并将SMR传递给编码单元。
4. 码率分配
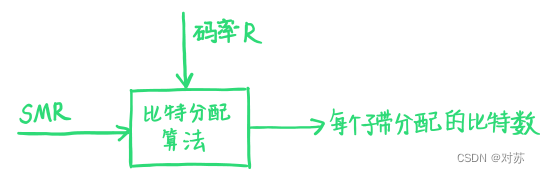
(1)Layer Ⅰ编码
在调整到固定的码率之前,先确定可用于样值编码的有效比特数,这个数值取决于比例因子、比例因子选择信息、比特分配信息以及辅助数据所需比特数 。
码率分配
- 思路:使整帧和每个子带的噪掩值NMR=SMR-SNR(dB)最小。
- 算法:对最高NMR的子带分配比特,使获益最大的子带的量化级别增加一级,重新计算分配了更多比特子带的NMR。
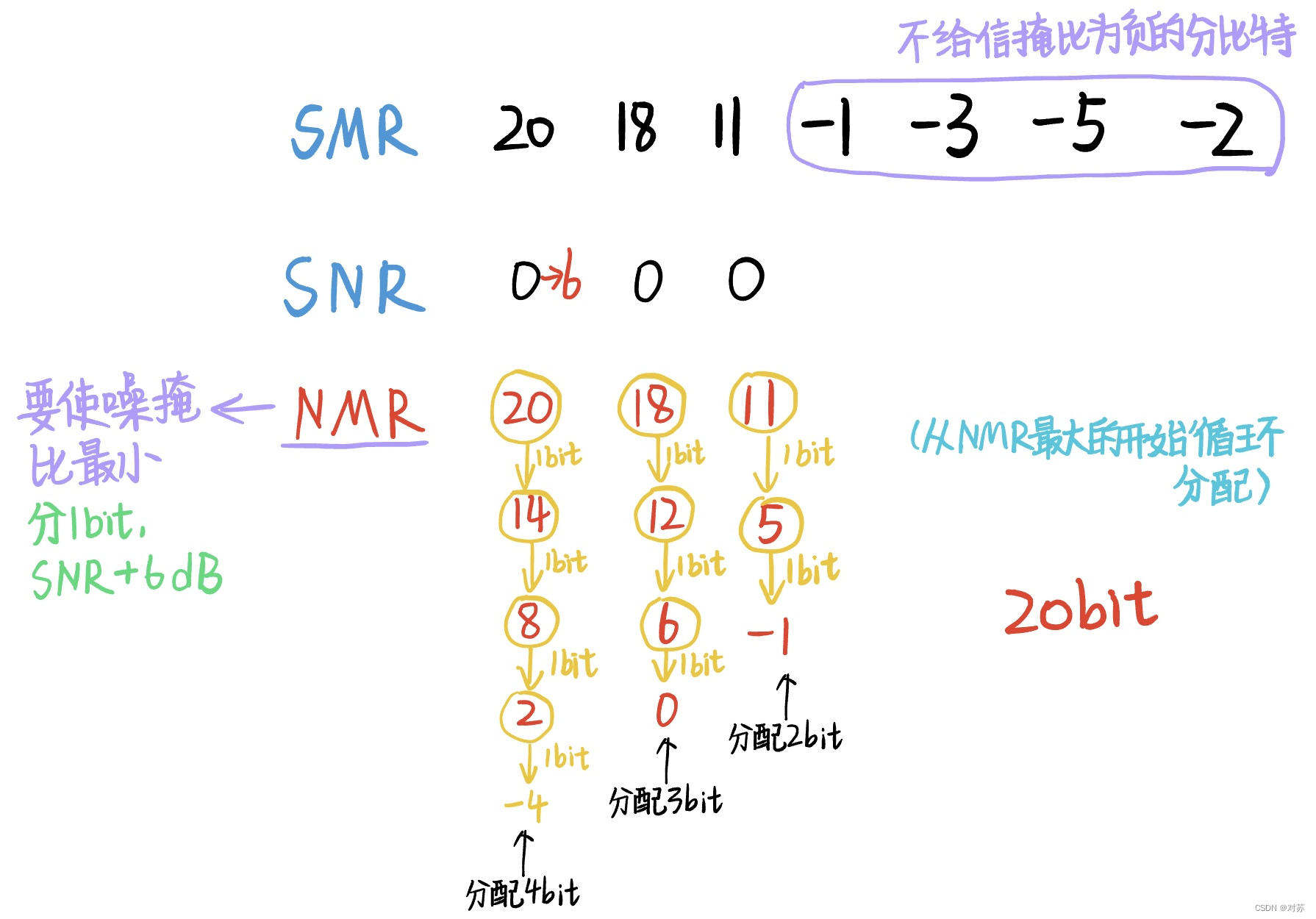
(2)Layer Ⅰ装帧
二、实验步骤
1. 输出音频的采样率和目标码率
设定命令行参数:
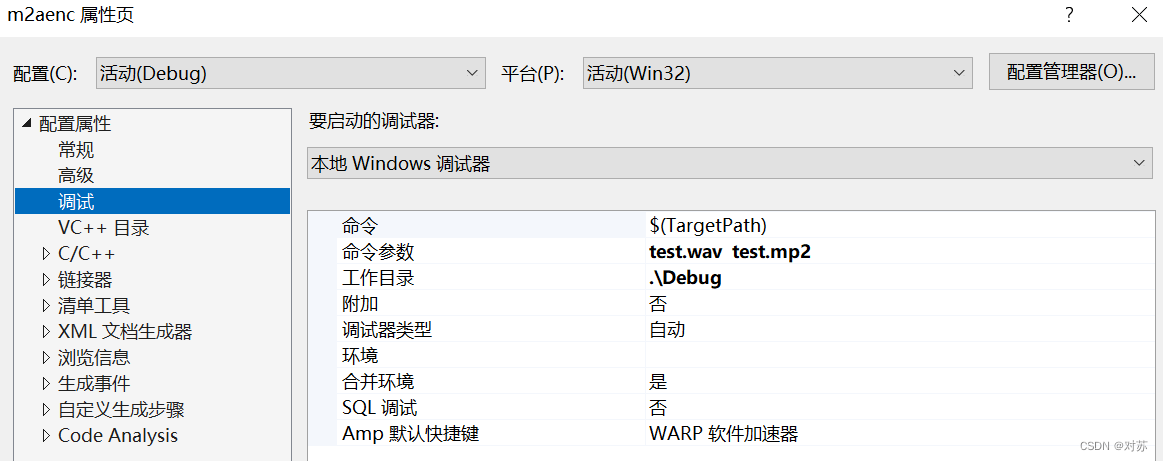
运行结果为:

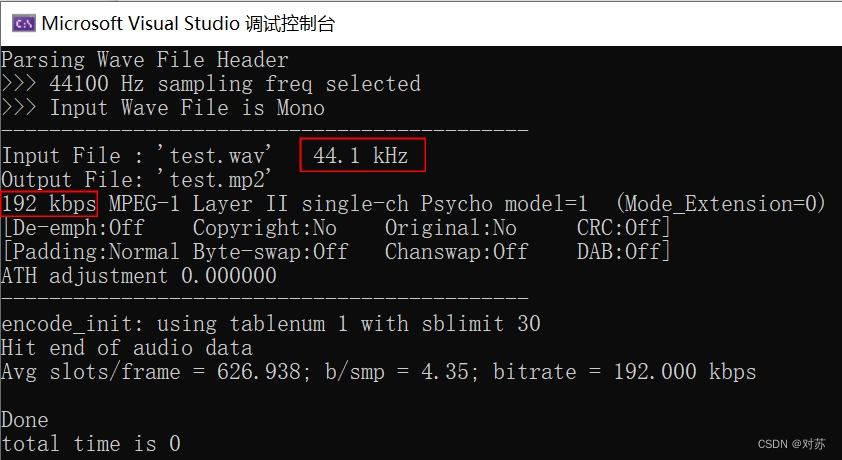
采样率为44.1KHz,目标码率为192Kbps。
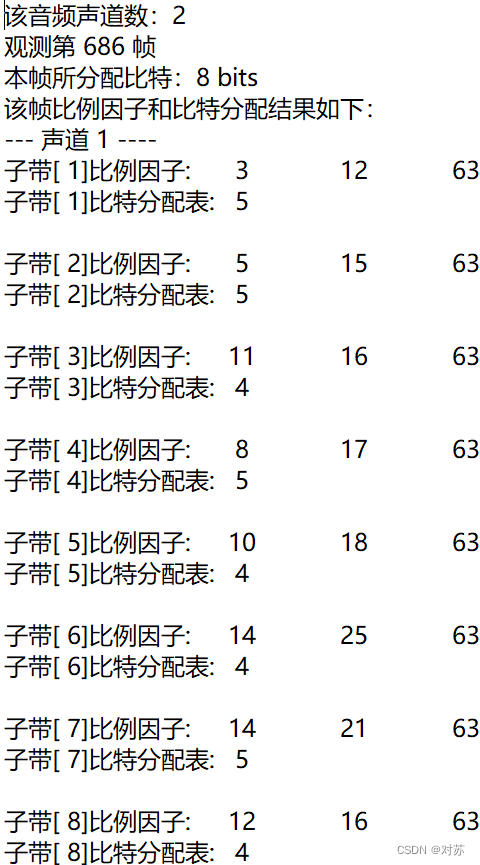
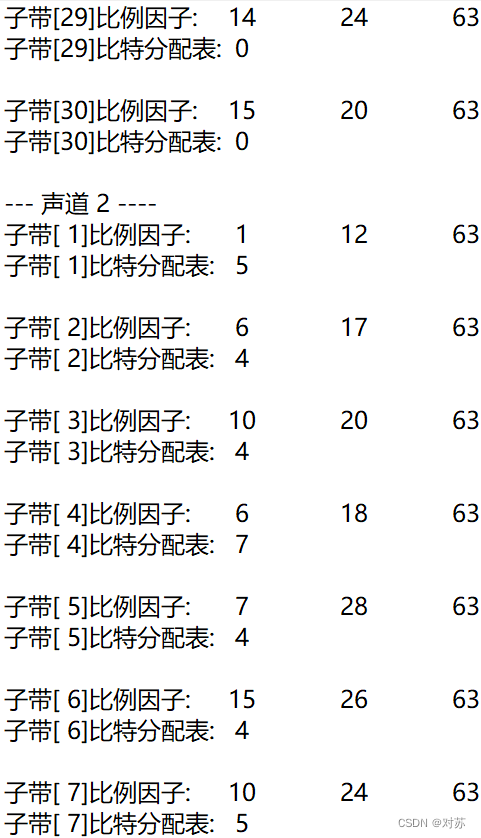
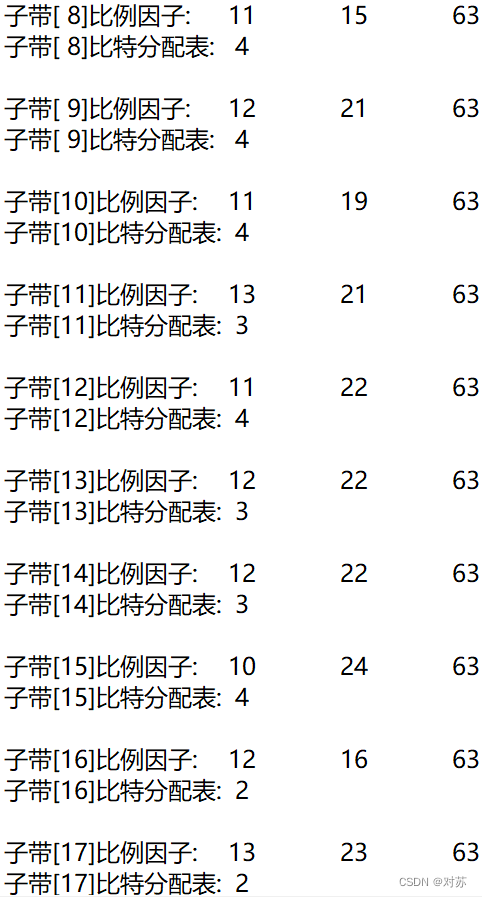
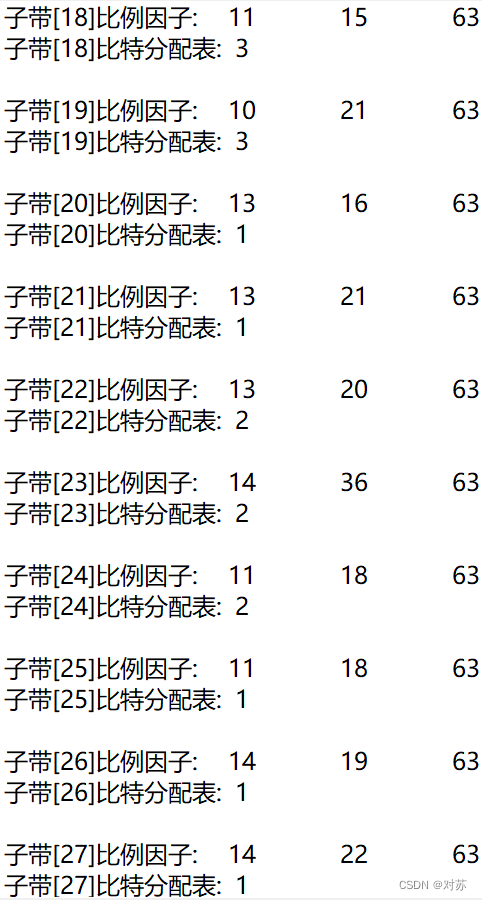
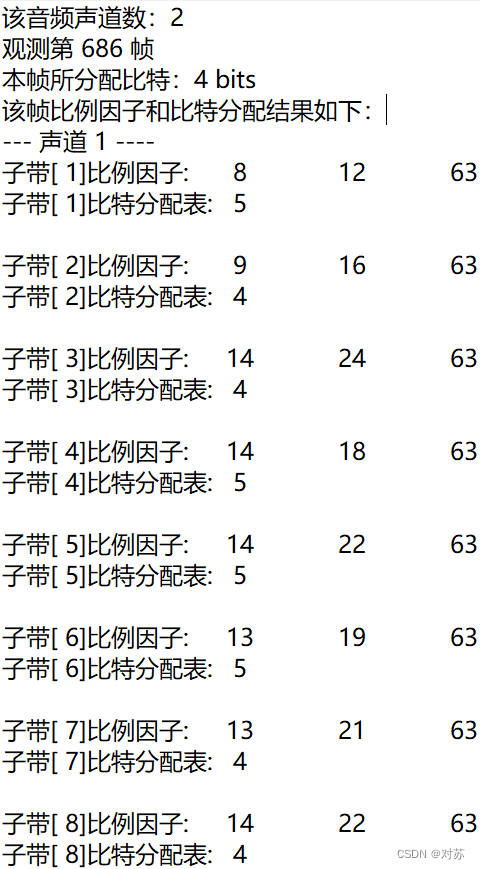
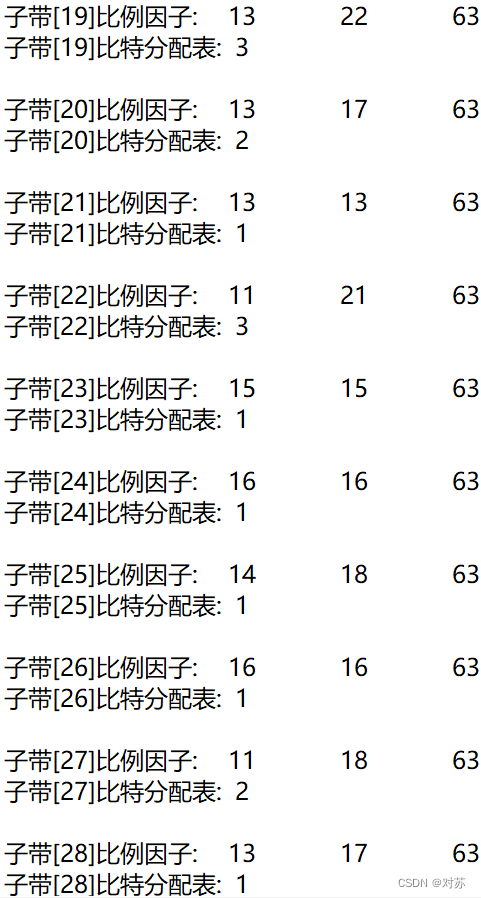
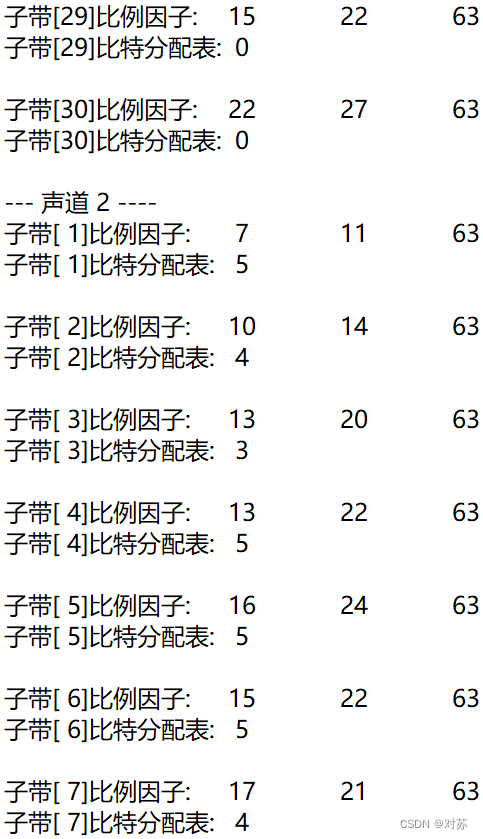
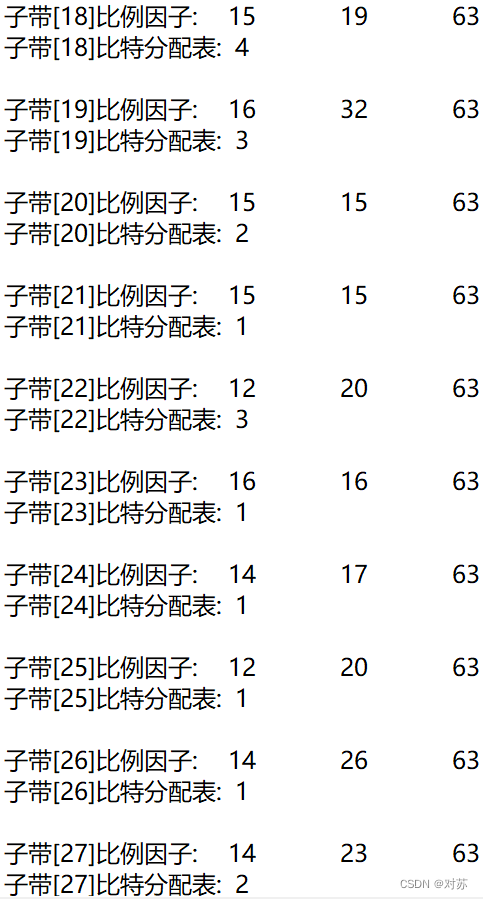
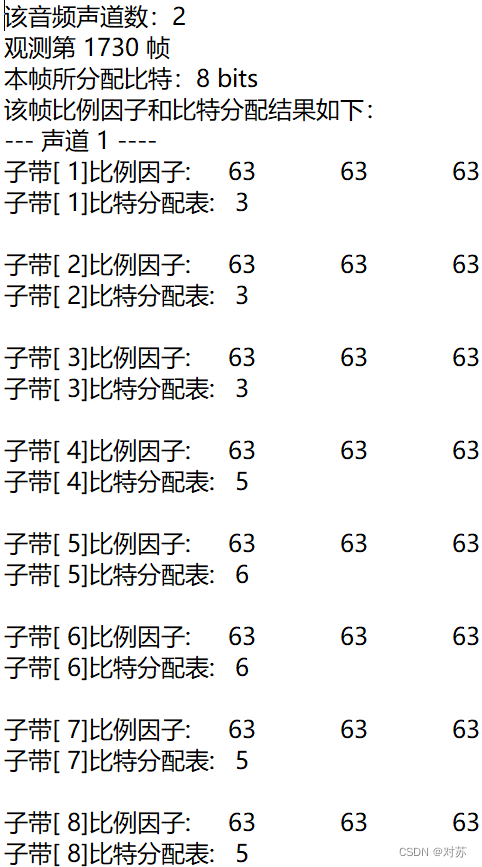
2. 输出数据帧的比例因子、分配的比特数和分配结果
在m2aenc.c中增加代码:
fprintf(out_txt, "该音频声道数:%d\n", nch);
fprintf(out_txt, "观测第 %d 帧\n", frameNum);
fprintf(out_txt, "本帧所分配比特:%d bits\n", adb);
fprintf(out_txt, "该帧比例因子和比特分配结果如下:\n");
for (ch = 0; ch < nch; ch++)
{
fprintf(out_txt, "--- 声道%2d ----\n", ch + 1);
for (sb = 0; sb < frame.sblimit; sb++)
{
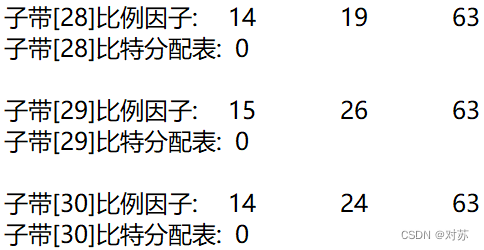
fprintf(out_txt, "子带[%2d]比例因子:\t", sb + 1);
for (gr = 0; gr < 3; gr++)
{
fprintf(out_txt, "%2d\t", scalar[ch][gr][sb]);
}
fprintf(out_txt, "\n");
fprintf(out_txt, "子带[%2d]比特分配表:\t%2d\n", sb + 1, bit_alloc[ch][sb]);
fprintf(out_txt, "\n");
}
}在int main()内增加代码:
int gr;
FILE* out_txt = NULL;
unsigned char* outTXT = NULL;
out_txt = fopen("output.txt", "w");3. 选择三个不同特性的音频文件
(1)音乐
选取音乐music.wav:
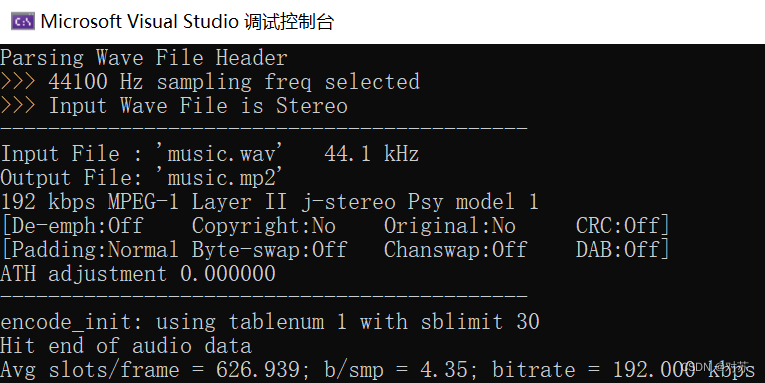
结果保存在output.txt中:



(2)噪声
选取一段持续噪音noise.wav:
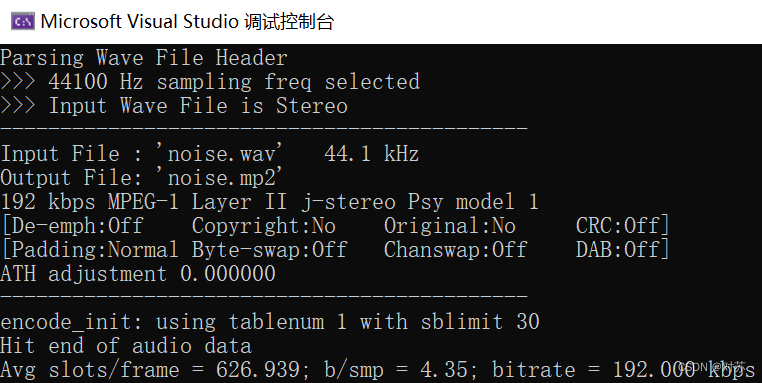
结果保存在output.txt中:
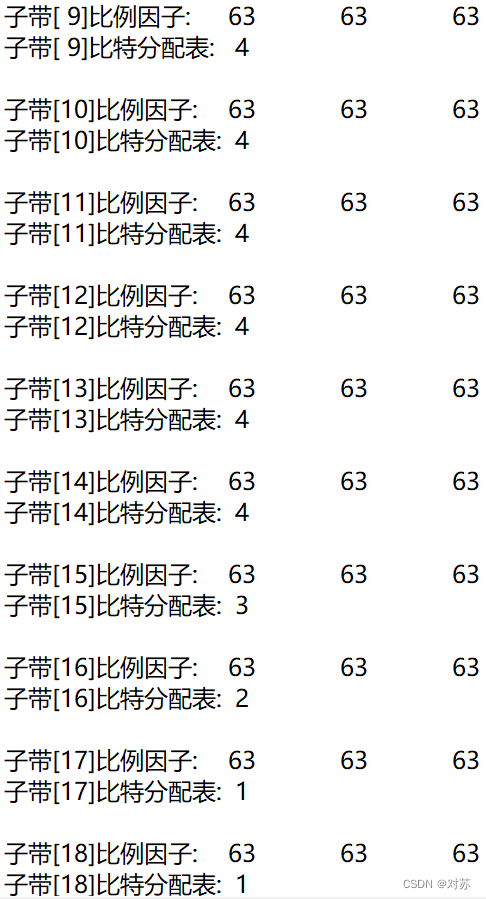
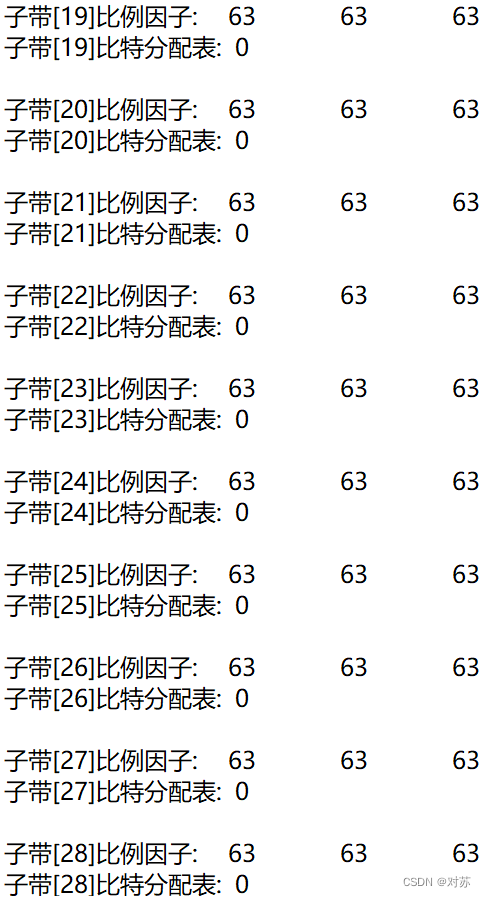

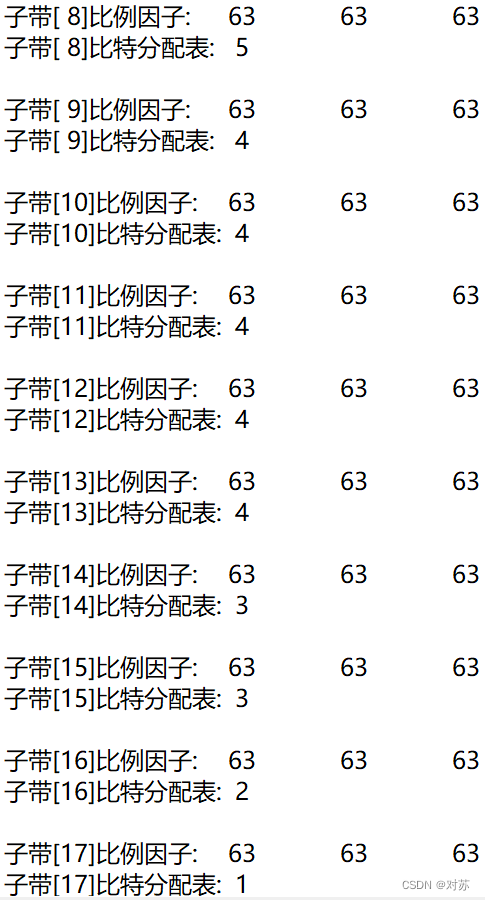

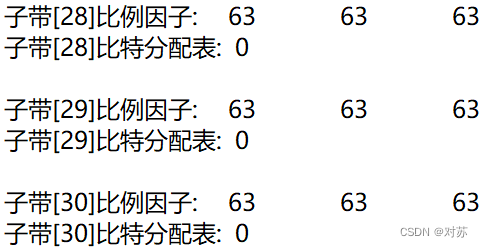
(3)混合
选取音乐+噪音混合mix.wav:
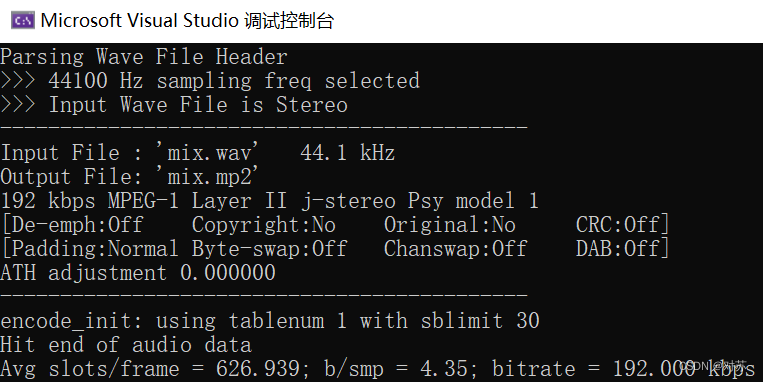
结果保存在output.txt中: