文章目录
- 加密流量专栏
-
- 1. 原理篇
- 2. 模型篇
- 3. 文章分类总结
-
- 3.1 研究方向
- 3.2 特征提取
- 3.3 机器学习模型及其改进
- 3.4 深度学习模型及其改进
- 3.5 其他模型
-
- MBTree: Detecting Encryption RATs Communication Using Malicious Behavior Tree
- Realtime Robust Malicious Traffic Detection via Frequency Domain Analysis
- Encrypted Malware Traffic Detection via Graph-based Network Analysis
- Accurate Decentralized Application Identification via Encrypted Traffic Analysis Using Graph Neural Networks
- 3.7 实时检测
- 3.8 概念漂移
- 工具
- 数据集
加密流量专栏
1. 原理篇
- 原理:
- 会话、流、数据包之间的关系。
流:指具有相同五元组(源IP,源端口,目的IP,目的端口,协议)的所有包
会话:指由双向流组成的所有包(反向流:源和目的互换)
- 在计算机网络中,定义5元组(源IP,目的IP,源端口,目的端口,协议)相同的一系列数据包同属于一个流。
- 源IP和目的IP相反,源端口和目的端口相反,协议相同的另一个流就是它的反向流。
- 前向流和反向流就构成了一个双向流即会话。
- 论文:
综述类:
研究类:
2. 模型篇
- 论文:
综述类:
研究类:
3. 文章分类总结
3.1 研究方向
- Machine Learning for Encrypted Malicious Traffic Detection: Approaches, Datasets and Comparative Study(重要)
- 加密流量研究方向
- 综述类论文_TLS协议恶意加密流量识别研究综述(中文论文)
3.2 特征提取
- 研究型论文_结合多特征识别的恶意加密流量检测方法(中文论文_信息安全学报)
- 研究型论文_基于 stacking 和多特征融合的加密恶意流量检测研究(中文论文)
- 研究型论文_基于数据包特征的加密流量分类(中文论文)
3.3 机器学习模型及其改进
3.4 深度学习模型及其改进
Flow Sequence-Based Anonymity Network Traffic Identification with Residual GCN
- 提出利用流之间的属性和时间关系,实现更合理有效的流序列特征提取,用于交通识别。我们假设图卷积网络(GCN)适合我们的目的,并提出了一种新的RESGCN模型来识别不同的网络服务。
- 设计了一个实用的方案来处理真实世界的原始交通数据。它考虑了流量分割,用于生成和丰富原始流量的流量特征,以及基于lightgbm的特征组合,避免了不重要的特征降低模型性能和效率。
- 在两个真实的流量数据集上评估该框架。实验结果表明,该方法具有较好的分类性能,适用于不同网络服务的识别。
总结:
本文提出了一种新的基于流序列的网络流量识别框架,该框架利用RESGCN利用流之间的属性关系和时间关系,成功地识别了不同匿名网络服务。此外,作为一种端到端的实时流量识别方法,我们的框架可以有效地处理真实的流量。它考虑了流量分割,利用原始流量生成和丰富流量特征,以及基于lightgbm的特征组合,避免了不重要的特征降低模型性能和效率。实验结果表明,RESGCN分类器由于结构设计优良,具有较高的分类精度、较低的复杂度和较快的分类速度。
- 论文亮点
- 准确率:
(1)通过评估各种参数:比如流量分割方法(基于时间的方法:多少秒分割一次流量),特征选择的数量等等。来确认适合模型的最优参数。
(2)提出了一种ResGCN的方法来提高模型的准确率:分别从时间和属性两个角度进行构图,使得模型能够充分提取每个流之间的信息。- 实时性:
(1)使用lightGBM来提取特征,从而保证模型提取特征的速度够快。
(2)得益于GCN对流序列的有效特征提取,RESGCN可以在不需要大参数的情况下实现精确分类。
- 论文缺点(创新想法)
- 模型只能应用于对正常网络应用流量的分类,没有考虑网络中存在的恶意流量的情况,因此可以加入对正常与异常流量的分类模块,对模型进行进一步拓展。
- 模型的鲁棒性有待进一步提高,即当模型受到恶意攻击者投放的一些精心制作的流量攻击时,还能否正确对流量进行分类。
- 工具
- 流量分析工具Tranalyzer2,安装教程
- 数据挖掘工具Weka,安装教程
- 数据集
SJTU-AN21 dataset:https://github.com/iZRJ/The-SJTU-AN21-Dataset
ISCXVPN2016:https://www.unb.ca/cic/datasets/vpn.html


MAppGraph: Mobile-App Classification on Encrypted Network Traffic using Deep Graph Convolution Neural Networks
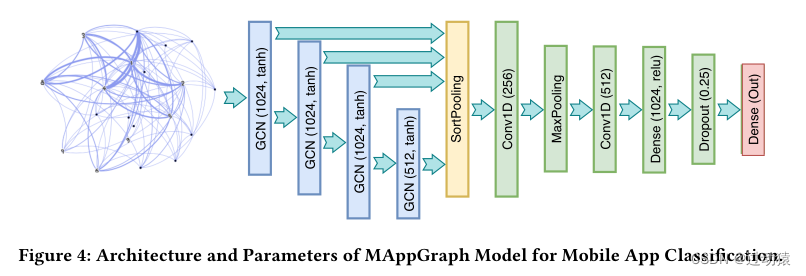
论文贡献:
- 开发了一种处理网络流量的方法,并生成具有节点特征和边缘权重的图形,从而更好地代表移动应用程序的通信行为。
- 开发了一个DGCNN模型,能够从大量的图中学习移动应用程序的流量行为,并实现快速的移动应用程序分类。
- 收集了101个移动应用程序的流量,并进行了大量的实验来证明MAppGraph的有效性。
- 增强了AppScanner和FlowPrint,并将其作为与MAppGraph性能比较的基线。
论文解决上述问题的方法:
- 只从包头中提取包大小、包到达间时间等信息,并推导出统计特征,作为图节点的属性来表示应用程序和服务之间通信的流量行为。而没有提取数据包的有效载荷。
- 在不同的时间收集移动应用程序的网络流量,导致每个应用程序需要处理大量的网络流量。每个流量块(例如,在5分钟内)形成一个通信图。在收集了大量的流量数据后,一个移动应用程序会有一组图,每个图代表不同时刻的流量行为。通过这一大组图学习或识别每个移动应用程序的指纹。
论文的任务:
对应用程序进行多分类。(这是一个graph-level的图神经网络分类问题)
图构建方法:
图的构建:
节点构建:以(目的ip,目的端口)来构造节点。每个节点具有63个特征
边构建: C i , j = ∑ t = 1 T a i ( t ) ⋅ a j ( t ) C_{i,j} = \sum_{t=1}^Ta_i(t)·a_j(t) Ci,j=∑t=1Tai(t)⋅aj(t)这样一来,在一个图中,如果一个应用程序(IP相同)使用了多种服务(即多个不同的端口),那么这个图中就会生成多个该应用程序的节点,这样就避免了单节点的星型拓扑结构。
模型:
DGCNN
论文的总结:
-
学到的方法
理论上的方法:
- 学到了一种构造边权重的方法。对某个应用收集一段时间的流量,记为 T w i n d o w s T_{windows} Twindows。然后对这段时间进行进一步切片,每段时间用 t s l i c e t_{slice} tslice 表示,共 T T T 段时间。对于每个 t s l i c e t_{slice} tslice 而言,若两个节点之间存在数据包交换(即既有接收又有发送数据包),则将这两个节点在这个 t s l i c e t_{slice} tslice时间段的权值设为1,否则设为0。最后在整个 T w i n d o w s T_{windows} Twindows时间段内,这两个节点的边权重为所有 t s l i c e t_{slice} tslice时间段的权值之和。
- 大概清楚了当前实际场景中流量交互的模式。
- 多个第三方服务可能部署在同一台服务器(即同一IP地址)下,但端口号不同
- 同个第三方服务通常部署在多个服务器上(不同的IP地址),以提供负载均衡。
- 单纯使用IP地址来构造节点会导致产生一个以应用程序为中心的星型拓扑,这样一来,大部分图就会具有相同结构。为了避免这种情况发生,可以使用(目的IP地址,目的端口)来代替使用单一IP地址来构建图节点。
-
论文优缺点
优点:
- 论文的模型在实时预测时,将收集到的数据存储下来以丰富训练集,这样能避免数据漂移问题。数据漂移问题具体来说就是当应用程序的流量行为发生变化时,应用程序的指纹也会发生变化。但如果模型的训练样本还是之前收集的样本而没有进行更新的话,就会导致模型无法识别这些应用程序新的流量行为,从而导致准确率大幅下降。
缺点:
- 论文的重点放在了已知应用程序的流量识别,缺少未知应用程序的识别。但是在结尾处对该方向进行了讨论,这也是之后可以创新的方向。
-
数据集
- ReCon [34],应用程序加密流量数据集
- Cross Platform[33],应用程序加密流量数据集
- ANDRUBIS[23],应用程序加密流量数据集
- 该论文自行收集的数据集
-
可读的引用文献
- FLOWPRINT: Semi-Supervised Mobile-App Fingerprinting on Encrypted Network Traffic
- A Network Monitoring System for High Speed Network Traffic(一种收集流量的系统,可以读一读,看能不能安装一下)
EC-GCN: A encrypted traffic classification framework based on multi-scale graph convolution networks

论文贡献:
- 将加密流量表示为图形,并观察到许多明显的特征,这些特征揭示了加密流量中的潜在空间模式。
- 为了了解隐藏在流中的空间依赖性,我们创造性地将GCN引入我们的分类方法中,并提出了一种新的时间-空间(多子图)加密流量分类框架。据我们所知,这是第一个用于对加密流量进行分类的基于多图的方法。为了使我们的方法对噪声和动态具有鲁棒性,我们将图组织成多个粒度级别,并利用所有级别的特征。
- 在深度学习框架中,我们创造性地设计了一个编码层,以自动将加密的流量转换为图形表示。此外,我们还提出了一种新的图形化层和图形学习层来动态提取加密流量中的多图结构。
- 为了评估我们提出的模型的性能,我们在3个数据集上进行了一系列实验。实验结果表明,与现有方法相比,EC-GCN算法的精度提高了5% ~ 20%,容错能力更强。
论文解决上述问题的方法:
- 将加密流量表示为图形,并观察到许多明显的特征,这些特征揭示了加密流量中的潜在空间模式。使用GCN来提取空间特征。
- 为了使提出的方法对噪声和动态具有鲁棒性,将图组织成了多个粒度级别,并利用所有级别的特征。
论文的任务:
以报文长度序列为输入,将加密后的流量分类到特定的应用中
论文总结:
-
学到的方法
理论上的方法:
- 提供了一种构图的新思路:以一个流作为一个图,节点特征为数据包长度,边权重为数据包长度的转移概率。
- 为了提高模型的实时性,提出了一种轻量级的图池化层,从而在训练过程中逐层将图转化为一个规模更小的子图。具体实现方法如下:
H ( l + 1 ) = S ( l ) H ( l ) ,其中 H ( l + 1 ) ∈ R n l + 1 × F H^{(l+1)} = S^{(l)}H^{(l)},其中H^{(l+1)} \in R^{n^{l+1} \times F} H(l+1)=S(l)H(l),其中H(l+1)∈Rnl+1×F W ( l + 1 ) = S ( l ) T W ( l ) S ( l ) ,其中 W ( l + 1 ) ∈ R n l + 1 × n l + 1 W^{(l+1)} = S^{(l)T}W^{(l)}S^{(l)},其中W^{(l+1)} \in R^{n^{l+1} \times n^{l+1}} W(l+1)=S(l)TW(l)S(l),其中W(l+1)∈Rnl+1×nl+1 - 图中边权重矩阵 W W W学习图结构的方法:
首先定义一个 I R IR IR
I R = D ( l ) − 1 W ( l ) H ( l ) ,其中 I R ∈ R n l × F IR = D^{(l)-1}W^{(l)}H^{(l)},其中IR \in R^{n^{l} \times F} IR=D(l)−1W(l)H(l),其中IR∈Rnl×F其中 D ( l ) D^{(l)} D(l) 表示 W ( l ) W^{(l)} W(l)的对角度矩阵
IR表示图中每个节点的交互得分,如果IR的某一行中的数值越大,就证明该节点(该行)与其余邻居节点交互越频繁。下面具体介绍当前 l 层的权重矩阵如何计算:

-
论文优缺点
优点:
- 考虑了模型的实时性。在构建模型时使用了轻量级的pooling方法,逐层降低图的规模,同时还考虑了边权重矩阵的更新,从而使得降低图规模时造成的信息损失减小。
- 只使用了数据包长特征。并根据这一个特征提取了它的时间和空间信息。
缺点:
- 由于只使用元数据特征作为输入,EC-GCN可能会受到一些流量整形操作的影响,例如填充入包以正则化报文长度序列[36]。
解决思路:可以通过集成更多的元数据特征,包括数据包类型序列、数据包间隔序列和上行/下行序列等,在一定程度上克服这一问题。
- 难以应对协议变化和流量混淆的鲁棒算法。
-
数据集
- OBW30:自行收集的数据集
- HW19:自行收集的数据集
- ISCX-Tor [34]:公共的数据集
3.5 其他模型
MBTree: Detecting Encryption RATs Communication Using Malicious Behavior Tree
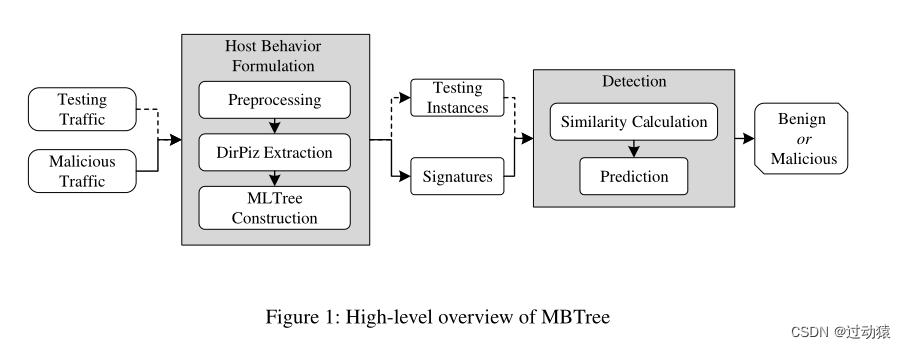
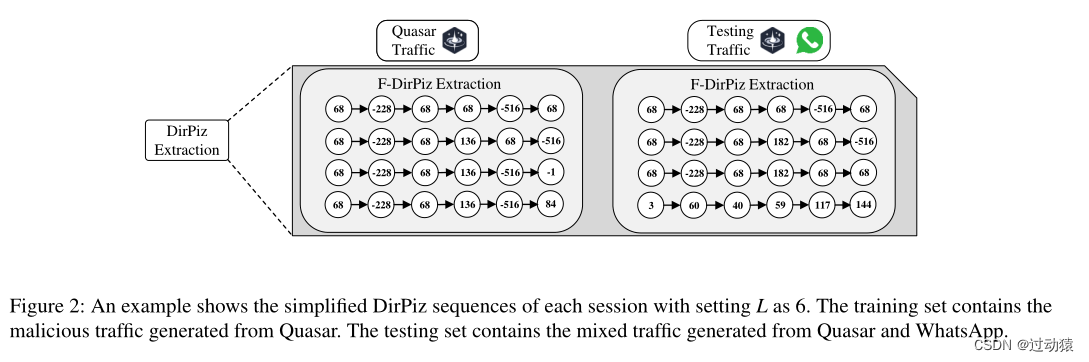
创新想法:
- 检测模型要考虑模型在不同环境下的稳定性:可以通过训练集和测试集分布不同来验证模型稳定性。
- 检测模型要考虑模型的抗不平衡性和样本依赖度:一般能够处理不平衡数据或只通过少量样本就能获得高准确度的模型比较好
Realtime Robust Malicious Traffic Detection via Frequency Domain Analysis

- 提出了第一个基于机器学习的系统,在高吞吐量网络中实现实时和健壮的检测:Whisper,一种利用频域分析的新型恶意流量检测系统。
- 通过频域特征分析提取序列特征,为Whisper的检测精度、鲁棒性和吞吐量奠定基础。
- 开发了Whisper的自动编码向量选择,减少了人工参数选择的工作量,在保证检测精度的同时避免了人工参数设置。
- 开发了一个理论分析框架来证明Whisper的特性。
- 使用英特尔DPDK构建Whisper原型,并使用不同类型的重放攻击流量的实验来验证Whisper的性能。
总结1:
- 能检测零日攻击:Whisper使用机器学习的方法进行检测,能有效应对零日攻击
- 准确率:Whisper通过频域分析有效地提取和分析网络流量的序列特征,以低信息损失提取流量特征,低信息损失能保证准确率。
- 健壮性(鲁棒性):由于频域特征代表了数据包序列的细粒度顺序特征,不受注入噪声数据包的干扰,因此Whisper可以实现鲁棒检测。
- 实时检测:Whisper提取流量的频域特征。流量的频域特征可以有效地表示流量的各种分组排序模式,且特征冗余度低。低特征冗余保证了高通量流量检测。
由于丰富的特征表达和轻量级的机器学习,Whisper最终实现了高吞吐量网络中恶意流量的实时检测。
难点: 由于流量模式的大规模、复杂性和动态性,从流量中提取和分析频域特征并非易事。
总结2:
- 学到的方法
- 理论上的方法:
- 对特征进行频域变换,并在RGB图上进行可视化分析。如文章中3.1中提到的。
- 当对一个特征进行编码时,可以对编码向量 w w w使用SMT方法进行优化,如文章中3.2中提到的。
- 如果对所有的样本直接求聚类中心,可能会受到个别极端值的影响。此时可以设置一个窗口,对每个窗口先求一个平均值,然后再对这些平均值求聚类中心,这样一来就会多多少少消除一些影响。如文章中3.3提到的。
- 写论文的方法:
- 实验评估那节,要先写上该节实验证明了哪几个问题?可以从模型优势,模型对比等方面探讨。
- 论文优缺点
- 考虑了模型的准确率(所使用的频域特征代表了流量的细粒度顺序特征,能更深的理解数据)
- 考虑了模型的健壮性(能检测攻击者构造的逃避攻击,即注入各种良性流量来逃避检测)
- 考虑了模型的时效性(Whisper提取流量的频域特征。流量的频域特征可以有效地表示流量的各种分组排序模式,且特征冗余度低。低特征冗余保证了高通量流量检测。)
- 工具
DPDK:高速包解析器的实现
mlpack:K-means聚类实现
Z3 SMT solver:SMT问题求解
- 数据集
WIDE. Accessed January 2021. MA WI Working Group Traffic Archive. http://mawi.wide.ad.jp/mawi/.
Encrypted Malware Traffic Detection via Graph-based Network Analysis

论文的贡献:
- 提出了ST-Graph,一个加密场景下的实时恶意流量检测框架。ST-Graph通过探索和集成多种特征,有效地揭示加密网络中的恶意行为,从而实现低误报率的检测。
- 为加密流量设计了一个异构属性图,并提出了一种新的嵌入方法,即间隔倾斜随机游走,用于探索和融合流量数据的时空特征。
- 我们在几个真实的网络场景中对检测系统进行了长达一年的评估,并观察到良好的结果。与其他工作相比,我们的检测模型具有更高的精度(接近基线的10倍),并且在可容忍的时间成本下显著降低假阳性。
- 通过实际部署,我们的检测系统发现了一些其他系统无法发现的恶意案例,并揭示了一些新兴的恶意流量类型。
论文的任务:
- 恶意软件检测:主机是否被恶意软件感染(二分类)
- 恶意软件家族分类(多分类)
论文的总结:
-
学到的方法
理论上的方法:
- 图的随机游走可以综合图的时间和空间特征
- 得到主机的embedding后,还可以通过为embedding设置权重(与这个embedding相关的一些信息,softmax计算重要性。)
写论文的方法:
实验评估的写法:
- 实验设置:
- Implementation:核心方法实现的过程中用到的工具
- Baselines:基线模型,用于对比
- Environment and Parameters:实验环境和参数设置
- Metrics:评估指标
- 数据集:
- 数据集的介绍
- 数据集的收集方法
- 数据集的切分(训练集,测试集)
- 收集数据时涉及到的伦理问题
- 检测效果:
- 在不同数据集上,各种基线模型和提出模型在不同评估指标下的比较。
- 泛化能力(消融实验)
- 模型鲁棒性检测:加入噪声数据
- 真实世界评估
实验评估后面的内容:
- 讨论:模型局限性
-
论文优缺点
优点:
- 准确率高:提出了ST-Graph,从空间和时间角度探索多个特征,并集成所有可用信息,用于加密场景下的全面恶意软件流量检测。
- 实时性好:只通过迭代更新优化边表示来改进图表示的算法,而最优节点表示则来自封闭形式的解。这大大降低了图表示学习的计算复杂度;ST-Graph采用少量迭代的随机游走学习边嵌入,并采用封闭形式的解决方案优化主机嵌入。这大大降低了计算复杂度,满足了实时检测的需要。
- 能检测未知攻击
- 能实际应用
缺点:
- 集合 I I I(主机流的顺序)的元素要怎么表示,没有具体说明。
- 基线模型太少,说服力稍小一些。
- 网络规模。内部网络的规模对st图有影响。内部主机的增加会导致我们的图结构中有更多的节点和边。图中边的数量越多,检测的时间成本就越高,网关无法处理无限多的主机。
-
创新想法
可以不通过随机游走的方式来提取时空特征,而采用其他方法,如GCN等等。
-
工具
- Tshark:提取流量
- NetworkX来构建异构图
- Gensim的文本表示来初始化节点
-
数据集
- 公开数据集AndMal2019
- 私有数据集EncMal2021
Accurate Decentralized Application Identification via Encrypted Traffic Analysis Using Graph Neural Networks



论文的贡献:
- 提出流量交互图(TIG)来表示每个单独的加密流,其中TIG中的顶点表示包,边表示一对客户端和服务器之间的包级交互。我们还提供了量化的措施,以证明使用TIG表示流比传统的包长度序列的优势。
- 设计了GraphDApp模型,这是一个使用多层感知(MLPs)和全连接层的强大的基于GNN的分类器。它将不同DApp流的TIG映射到嵌入空间中的不同表示,不需要手工制作的特征,从而可以有效准确地进行分类。
- 收集了以太坊上1300个dapp的真实流量数据集,流量超过16.9万。我们展示了GraphDApp在封闭和开放环境下的准确性和效率。与最先进的方法相比,GraphDApp的分类准确率最高,训练时间最短。此外,它也适用于传统的移动应用分类。
论文的任务:
- 封闭情景:实现DApps的多分类
- 开放情景:实现DApps的二分类(正常、恶意)
论文的总结:
-
学到的方法
理论上的方法:
- 测试提出的图构建效果比其他的特征好的方法,可以采用量化的方法(由于本文的任务是DApp指纹识别,因此需要每个DApp产生的流尽可能相似,因此采用了图编辑距离来度量构建的图所表示的流的相似度的方式)(原文:III-C,本文:论文贡献-2-3)
-
论文优缺点
优点:
- 研究对象为现有研究较少的DApp的指纹识别
- 构件图的方法很值得借鉴:
- 包方向信息:方向信息由TIG中顶点的符号显示,其中正值表示下行数据包,负值表示上行数据包
- 数据包长度信息:数据包长度信息是用于加密流分类的关键特性。
- 报文突发信息:TIG中同一层的顶点表示组成单个突发的数据包。不同应用程序的突发级行为可能有很大差异,因此可以作为分类器学习的鉴别特征。
- 包排序信息:TIG可以表示从SSL/TLS会话开始协商到应用程序数据传输结束的报文顺序。此外,TIG还反映了服务器和客户端之间的交互。
缺点:
- h v h_v hv的初始化不太清楚是怎样的,只包含包的大小(带方向)这个特征吗?
- 模型的细节描述的不太到位,比如Readout函数使用的是哪个。
- GraphDApp需要相对较长的时间来标记未知流。可以通过适当减少tig中的包数来缩短特征提取时间,减少MLP层数和隐藏单元来加快预测速度。
- 作为指纹识别方案,当应用程序的指纹发生变化时,精度会相应降低。为了解决这个问题,我们可以定期更新应用程序的tig,并微调分类器中的参数。
-
创新想法
- 除了DApp,还可以在其他的一些新型应用上尝试一些比较好的模型,以用于指纹识别
- 构造TIG时,除了数据包长度信息,是否可以使用其他的特征或添加其他的特征(这些特征都是有利于加密流量分类的,可以先通过特征筛选或者其他论文中提到的比较重要的特征)
- 可以通过使用GCN模型来提取用分类的每个流的embedding,后面再跟全连接层进行分类
- 本文由于实验对象为DApp,因此只在Chrome浏览器上进行了流量抓取。可以考虑不同的浏览器上效果是否不同。
- 设计的模型要适应于应用程序的指纹发生变化的情况。即概念漂移。
-
工具
- wireshark
-
数据集
- 私有数据集:手动收集
Detecting Unknown Encrypted Malicious Traffic in Real Time via Flow Interaction Graph Analysis


论文贡献:
- 提出了HyperVision,这是第一个利用流交互图对未知模式的加密恶意流量进行实时无监督检测。
- 开发了几种算法来构建内存图,使我们能够准确地捕获各种流之间的交互模式。
- 设计了一种轻量级的无监督图学习方法,通过图特征检测加密流量。
- 开发了一个由信息论建立的理论分析框架,以表明该图捕获了接近最优的交通交互信息。
- 建立HyperVision,并使用各种真实世界加密恶意流量的广泛实验来验证其准确性和效率。
论文解决上述问题的方法:
- 提出了HyperVision来实现无监督的检测
- 构建内存图来捕获各种流之间的交互模式,从而达到检测未知恶意流量的目的
- 构图时保留使用明文流量检测传统(已知)攻击的能力,从而实现通用检测
论文的总结:
-
学到的方法
理论上的方法:
- 聚类可以从以下几个角度切入:
(1)类似短流进行聚类:
- 流具有相同的源地址 和/或 目的地址,这意味着由这些地址产生的行为相似;
- 流具有相同的协议类型;
- 流的数量足够大,即当短流的数量达到阈值AGG LINE时,确保流具有足够的重复性。
(2)类似连通分量可以进行聚类。用以下五元组表示连通分量,然后DBSCAN聚类:
- 长流的数量
- 短流的数量
- 表示短流的边数
- 所有长流的字节数
- 所有短流的字节数
(3)类似长流进行聚类
- 分别为与短流和长流相关的边提取了8个和4个图结构特征,具体特征如上图所示
- 对特征进行min-max归一化
- 使用DBSCAN方法进行聚类,其中要采用较小的搜索范围 ϵ \epsilon ϵ 和较大的mini-point值,以避免在聚类中包含不相似的边,从而可能产生假阳性
- 对于无法聚类的异常边,将其作为只含这一条边的簇
(4)使用聚类方法对流进行聚类:
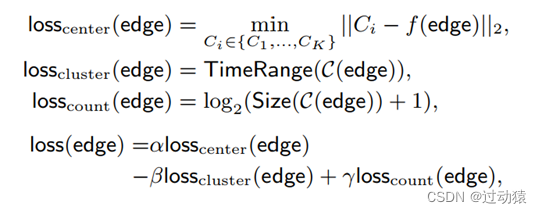
- 减小图规模的方法
- 聚类短流
- 聚类连通分量
- 预聚类长流
写论文的方法:
模范文章 -
论文优缺点
优点:
- 考虑了无监督下加密流量的检测方法
- 考虑了模型的鲁棒性
- 考虑了模型的实时性
- 考虑了模型对未知加密流量的检测能力
- 考虑了模型的通用性,即能检测加密流量也可检测非加密流量
- 文献引用极多,实验工作极其丰富
缺点:
没想到困惑点:
- 不太清楚异常交互检测中Identifying Critical Vertices(识别关键节点)的SMT优化方法是怎么建模的
-
创新想法
- Connectivity Analysis(连通性分析)那里也可以分析一下各个连通分量的其他特征,比如时间间隔等,如果各个连通分量的时间间隔特征很集中,那么用DBSCAN根据时间相关特征来进行聚类也未尝不可。
-
工具
- Z3 SMT求解器:求解顶点覆盖问题来提取关键顶点,以最小化聚类数量
- NetFlow
- Zeek
-
数据集
- vantage-G of WIDE MAWI项目
- MAWI数据集[80]
- Kitsune数据集[56]
- CIC-IDS2017数据集[15]
- CIC-DDoS2019数据集[14]
-
可读的引用文献
- Flowlens: Enabling efficient flow classification for ml-based network security applications
- Kitsune: An ensemble of autoencoders for online network intrusion detection
- Deeplog: Anomaly detection and diagnosis from system logs through deep learning
3.7 实时检测
3.8 概念漂移
工具
流量分析工具
- 流量分析工具Tranalyzer2,安装教程
- Tshark:提取流量
- wireshark
- DPDK:高速包解析器的实现
模型构建工具
数据集
加密流量数据集
- SJTU-AN21 dataset:https://github.com/iZRJ/The-SJTU-AN21-Dataset
- ISCXVPN2016:https://www.unb.ca/cic/datasets/vpn.html
- 公开数据集AndMal2019
- 私有数据集EncMal2021
- WIDE. Accessed January 2021. MA WI Working Group Traffic Archive. http://mawi.wide.ad.jp/mawi/.