本文所有内容整理自Coursera - Advanced Machine Learning-
How to Win a Data Science Competition: Learn from Top Kagglers
一、分析问题
1、问题类型:
2、数据量大小
3、硬件需要
4、软件需要
5、评估模型是什么
6、有没有一些相关的历史代码
二、探索性数据分析
基本操作
1、通过hist图查看train和test分布是否一致
2、通过plot查看变量和target之间的关系,考虑时间变量的作用
3、单变量预测指标
4、bin 数值变量
5、计算变量相关性
Data Leakage
1、leak in time series:
数据集是否按照时间来拆分,而没有打乱;数据集是否包含未来数据;
2、metadata元数据:
探索是否可以找到数据的源数据结构,如zip code转换
3、id or row order:
把id和row order纳入模型中通常是有意义的
4、LB 问题:test数据和LB数据不同分布
按如下转换为同分布

C:test预测值
N:test总行数
N1:target值为1的行数
L:lb预测分
N1/N:实际test数据的平均值
5、参考资料:
https://www.kaggle.com/olegtrott/the-perfect-score-script
https://www.kaggle.com/wiki/Leakage
三、分析validation拆分策略
基本概念
1、将训练数据拆分为train和validation,并尽量保证validation和test同分布
2、尝试分别用调试好的validation和随机的validation验证方法是否有效
validation分割方法
1、holdout:sklearn.model_selection.ShuffleSplit
适用于比较大的数据集
2、k-fold:sklearn.model_selection.Kflod
将数据多次拆分,并取每个拆分的结果的平均值,适用于数据量比较小的数据集
3、leave one out:sklearn.model_selection.LeaveOneOut
每次拆分出一个validation,取最终结果的平均值,适用于数据量极小的数据集
4、stratification:分层确保每一个split出的validation都是同分布
适用于小型或不平衡的数据集
- time-based splits
- random
- by id
- combined
四、特征工程feature engine
拓展特征
1、groupby分组计算:mean、count、max、min
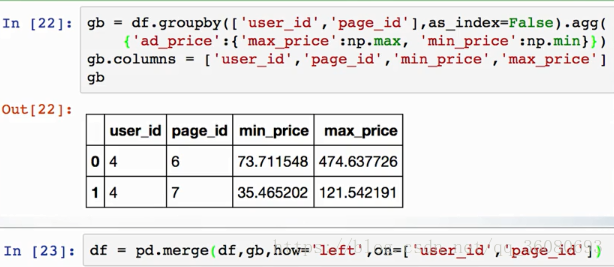
2、参数间计算:sum、add、minus、multiplay、diff
3、参数合并:f1.astype(str) + “_” + f2.astype(str)
4、数值分组neighbors:100m内最大的城市、200m内最小的商品
5、knn:先mean encoding再计算
- mean target of knn5、10、15、500、2000
- mean distance of knn10
- mean distance of knn10 with target 1
- mean distance of knn10 with target 0
6、特征计算图示:

Mean encoding
1、作用:为分类字段编码,并使分类字段具有一定的特征,可以使模型更好收敛
2、常用方法:将分类字段编码为(标记值合计/该分类行数)
means=X_tr.groupby(col).target.mean()
train_new[col+'_mean_target']=train_new[col].map(means)
val_new[col+'_mean_target']=val_new[col].map(means)其他方法:(goods/bads)*100、sum(goods)、goods-bads
3、解决过拟合regularization方法
稍后放出代码
4、问题:
- 如何在回归和多分类场景中使用:可以用mean以外的计算方法来encoding,median、max、min、sd、分布bin等
- many to many:先做cross production处理
- 时间序列:基于时间定义各种属性,例如往期用户购买量、往期所有用户总购买量/平均购买量
- 数字类属性:先bin,再当做分类属性进行encoding,先对模型进行决策树处理,挖掘数字属性的分割点,再bin
- 对组合属性建立encoding:组合模型可以基于初步决策树的结果,寻找频繁出现在父子节点的属性
5、整体操作步骤
- 测试阶段
- 在X_tr上进行encoding计算
- 将1的结果应用在X_tr和X_val上
- 对X_tr进行regularization计算
- 应用模型进行调试
- 上传阶段
- 在整个train上进行encoding计算
- 将1的结果应用在trian和test上
- 对train进行regularization计算
- 在train上训练模型
线性降维
1、原理:把一个矩阵用多个矩阵的乘积表示,应用于部分categorial、number列
2、参数:潜在变量5-100
3、模型包:sklearn
- 常用模型:svd、pca
- truncatedsvd:稀疏矩阵、文本分析
- NMF:正值潜变量,如count-like 数据,适用于tree-base处理
4、代码:

非线性降维tSNE
1、要点:
- 结果的好快基于参数的选择,尝试不同的perplexity困惑度
- 先降维再做tSNE
- 适合做数据的探索
- 同线性降维,需要把tSNE同时应用于train和test
相关资料
1、matrix factorizations线性降维:
- http://scikit-learn.org/stable/modules/decomposition.html
2、tSNE非线性降维:
- https://github.com/DmitryUlyanov/Multicore-TSNE
- http://scikit-learn.org/stable/auto_examples/manifold/plot_compare_methods.html
- https://distill.pub/2016/misread-tsne/
- https://lvdmaaten.github.io/tsne/
3、拓展特征:
- https://research.fb.com/publications/practical-lessons-from-predicting-clicks-on-ads-at-facebook/
- http://scikit-learn.org/stable/auto_examples/ensemble/plot_feature_transformation.html
五、模型计算
模型选择
1、图示:

2、树模型:GBDT、XGboost、lightGBM、random forest、ET
3、线性模型:liblinear、libsvm
核心参数调整
1、GBDT模型:

2、树模型:

3、神经网络模型:

4、线性模型:

训练技巧
early stop:
在训练数据上使用M1进行训练,并同时在固定周期迭代后在Val数据上对M2进行验证,如果在M2上的结果已经达到了最低点,则提前终止训练,即使模型还可以在M1上继续提升
六、ensembling模型融合
https://blog.csdn.net/qq_36080693/article/details/79782713