思路: 给面试官画一下JVM内存模型图,并描述每个模块的定义,作用,以及可能会存在的问题,如栈溢出等。
答案:
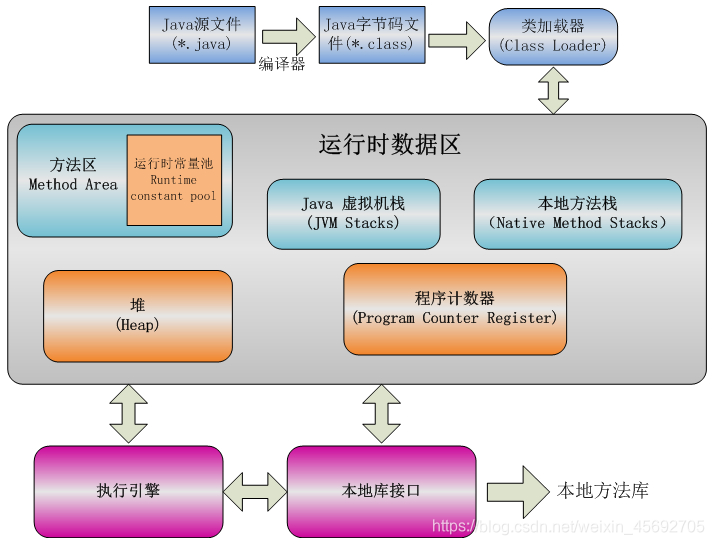
- JVM内存结构
-
程序计数器:当前线程所执行的字节码的行号指示器,用于记录正在执行的虚拟机字节指令地址,线程私有。
-
Java虚拟栈:存放基本数据类型、对象的引用、方法出口等,线程私有。
-
Native方法栈:和虚拟栈相似,只不过它服务于Native方法,线程私有。
-
Java堆:java内存最大的一块,所有对象实例、数组都存放在java堆,GC回收的地方,线程共享。
-
方法区:存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码数据等。(即永久带),回收目标主要是常量池的回收和类型的卸载,各线程共享。
[](()三. JVM内存为什么要分成新生代,老年代,持久代。新生代中为什么要分为Eden和Survivor ?
思路: 先讲一下JAVA堆,新生代的划分,再谈谈它们之间的转化,相互之间一些参数的配置(如: – XX:NewRatio,–XX:SurvivorRatio等),再解释为什么要这样划分,最好加一点自己的理解。
答案:
共享内存区划分
-
共享内存区 = 持久带 + 堆
-
持久带 = 方法区 + 其他
-
Java堆 = 老年代 + 新生代
-
新生代 = Eden + S0 + S1
一些参数的配置
-
默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ,可以通过参数
–XX:NewRatio配置。 -
默认的,Edem : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定)。
-
Survivor区中的对象被复制次数为15(对应虚拟机参数 -XX:+MaxTenuringThreshold)。
为什么要分为Eden和Survivor?为什么要设置两个Survivor区?
- 如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。老年代很快被
填满,触发Major GC.老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC
长得多,所以需要分为Eden和Survivor。
- Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选
保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
- 设置两个Survivor区最大的好处就是解决了碎片化,刚刚新建的对象在Eden中,经历一次Minor
GC,Eden中的存活对象就会被移动到第一块survivor space S0,Eden被清空;等Eden区再满
了,就再触发一次Minor GC,Eden和S0中的存活对象又会被复制送入第二块survivor space
S1(这个过程非常重要,因为这种复制算法保证了S1中来自S0和Eden两部分的存活对象占用连续
的内存空间,避免了碎片化的发生)。
[](()四. JVM中一次完整的GC流程是怎样的,对象如何晋升到老年代
思路: 先描述一下Java堆内存划分,再解释Minor GC,Major GC,full GC,描述它们之间转化流程。
答案:
-
ava堆 = 老年代 + 新生代
-
新生代 = Eden + S0 + S1
-
当 Eden 区的空间满了, Java虚拟机会触发一次 Minor GC,以收集新生代的垃圾,存活下来的对象,则会转移到 Survivor区。
-
大对象(需要大量连续内存空间的Java对象,如那种很长的字符串)直接进入老年态; 如果对象在Eden出生,并经过第一次Minor GC后仍然存活,并且被Survivor容纳的话,年龄设为1,每熬过一次Minor GC,年龄+1,若年龄超过一定限制(15) , 则被晋升到老年态。 即长期存活的对象进入老年态。
-
老年代满了而无法容纳更多的对象,Minor GC 之后通常就会进行Full GC,Full GC 清理整个内存
堆 – 包括年轻代和年老代。
- Major GC 发生在老年代的GC,清理老年区,经常会伴随至少一次Minor GC,**比Minor GC慢10
倍以上**。
[](()五. 你知道哪几种垃圾收集器,各自的优缺点,重点讲下cms和G1,包括原理,流程,优缺点。
思路: 一定要记住典型的垃圾收集器,尤其cms和G1,它们的原理与区别,涉及的垃圾回收算法。
我的答案:
几种垃圾收集器
-
Serial收集器: 单线程的收集器,收集垃圾时,必须stop the world,使用复制算法。
-
ParNew收集器: Serial收集器的多线程版本,也需要stop the world,复制算法。
-
Parallel Scavenge收集器: 新生代收集器,复制算法的收集器,并发的多线程收集器,目标是达
到一个可控的吞吐量。如果虚拟机总共运行100 《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》无偿开源 威信搜索公众号【编程进阶路】 分钟,其中垃圾花掉1分钟,吞吐量就是99%。
-
Serial Old收集器: 是Serial收集器的老年代版本,单线程收集器,使用标记整理算法。
-
Parallel Old收集器: 是Parallel Scavenge收集器的老年代版本,使用多线程,标记-整理算法。
-
CMS(Concurrent Mark Sweep) 收集器: 是一种以获得最短回收停顿时间为目标的收集器,标
记清除算法,运作过程:初始标记,并发标记,重新标记,并发清除,收集结束会产生大量空间碎
片。
- G1收集器: 标记整理算法实现,运作流程主要包括以下:初始标记,并发标记,最终标记,筛选
标记。不会产生空间碎片,可以精确地控制停顿。
CMS收集器和G1收集器的区别
-
CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用;
-
G1收集器收集范围是老年代和新生代,不需要结合其他收集器使用;CMS收集器以最小的停顿时间为目标的收集器;
-
G1收集器可预测垃圾回收的停顿时间
-
CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
-
G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。
[](()六. JVM内存模型的相关知识了解多少,比如重排序,内存屏障,happen-before,主内存,工作内存。
思路: 先画出Java内存模型图,结合例子volatile ,说明什么是重排序,内存屏障,最好能给面试官写以下demo说明。
答案:
一. Java内存模型图
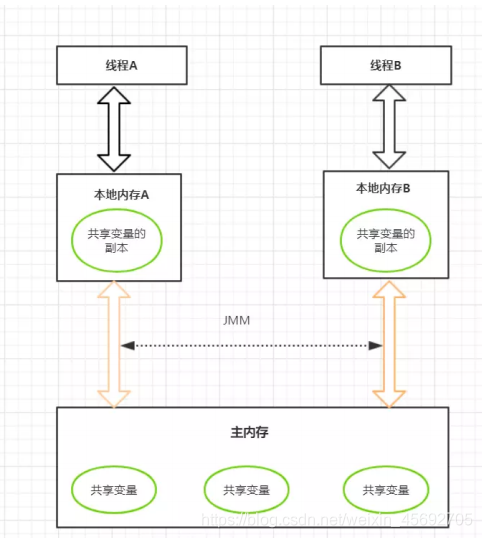
- Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
二. 指令重排序