利用python进行常见的数据预处理,主要是通过sklearn的preprocessing模块以及自写的方法来简单介绍下:
加载包及导入数据
# -*- coding:utf-8 -*-
import math
import numpy as np
from sklearn import datasets
from sklearn import preprocessing
iris = datasets.load_iris()
iris_X = iris.data[:4]
iris_y = iris.target[:4]
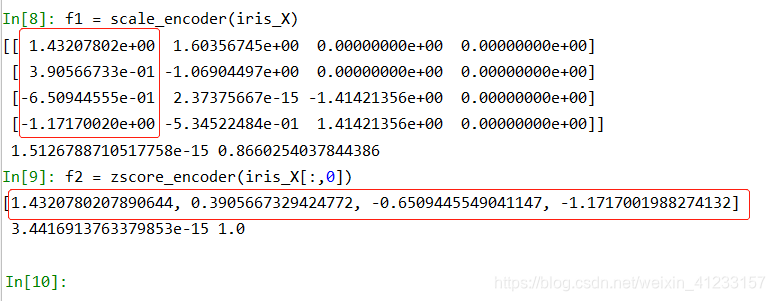
z-score标准化方法,均值为0,方差为1
# 方法1.sklearn下方法多列处理
def scale_encoder(iris_X):
X = preprocessing.scale(iris_X)
print(X[:4],'\n',np.mean(X),np.std(X))
return X
f1 = scale_encoder(iris_X)
# 方法2.单列处理
def zscore_encoder(colvalue):
average = float(sum(colvalue)) / len(colvalue)
X = [(x - average) / np.std(colvalue) for x in colvalue]
print(X[:4],'\n',np.mean(X),np.std(X))
return X
f2 = zscore_encoder(iris_X[:,0])
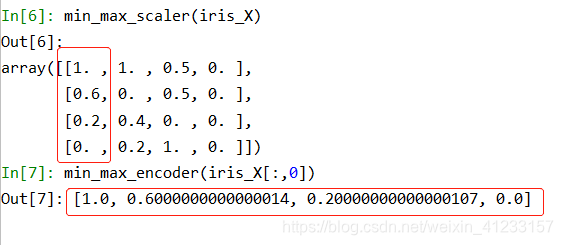
min-max标准化(Min-Max Normalization)
# 方法1:处理多列
def min_max_scaler(iris_X):
min_max_scaler = preprocessing.MinMaxScaler()
X2 = min_max_scaler.fit_transform(iris_X)
return X2
min_max_scaler(iris_X)
# 方法2:处理单列
def min_max_encoder(colvalue):
new_value = [(x - min(colvalue))/(max(colvalue) - min(colvalue)) for x in colvalue]
return new_value
min_max_encoder(iris_X[:,0])
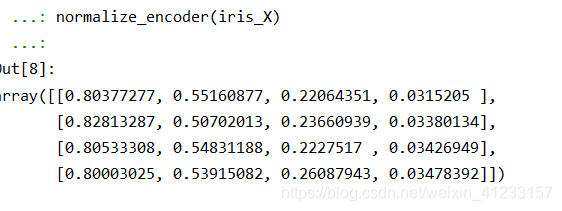
规范化(Normalization),其中L2 norm:平方和为1;L1 norm:绝对值和为1
def normalize_encoder(iris_X):
X3 = preprocessing.normalize(iris_X, norm='l2')
X4 = preprocessing.normalize(iris_X, norm='l1')
return X3
normalize_encoder(iris_X)
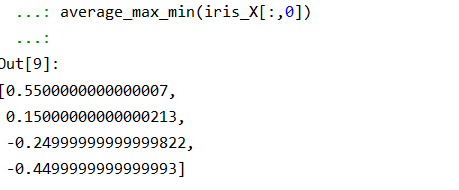
均值归一化方法[-1,1]
def average_max_min(data):
average = float(sum(data)) / len(data)
new_value = [(x - average) / (max(data) - min(data)) for x in data]
return new_value
average_max_min(iris_X[:,0])
特征二值化(Binarization),以某个阈值作为分割点进行切分数据
def binary_encoder(iris_X):
binarizer = preprocessing.Binarizer(threshold=2) #本例以阈值2为例
X5 = binarizer.transform(iris_X)
return X5
binary_encoder(iris_X)

标签二值化(Label binarization)
def label_encoder(iris_y):
lb = preprocessing.LabelBinarizer()
y2 = lb.fit_transform(iris_y)
return y2
label_encoder(iris_y)

数值或字符标签化
def label_encoder(data):
le = preprocessing.LabelEncoder()
le.fit(data)
t = le.transform(data)
return t
label_encoder(iris_X[:,0])

独热编码
def onehot_encoder(data):
enc = preprocessing.OneHotEncoder(sparse = False,categories='auto')
t = enc.fit_transform(data)
return t
onehot_encoder(iris_X)

对数变换
def log_encoder(col,logn):
if logn == 2:
new_value = [math.log2(x) for x in col]
elif logn == 10:
new_value = [math.log10(x) for x in col]
else:
print('暂不支持')
return new_value
log_encoder(iris_X[:,0],logn=10)
