1 Conv4
在一些论文中,也称为Conv-64F。其中“64F”表示网络中使用了64个滤波器(filters)
它包含 4 个重复的卷积块,在每个块中包含:
- 一个 kernel=3,stride=1,padding=1的卷积层;
- 一个 BatchNorm层;
- 一个 ReLU ;
- 一个大小为 2 的最大池化层。
输入图像的大小调整为 3 × 84 × 84 ,经过第一个卷积块后channel从3变成64。
有些论文还会在最后添加一个大小为5的全局最大池化层以降低嵌入的维数,大大减少后期转换的计算负担。
四个卷积块如图所示:

四个卷积块是相同的,图像shape的变化过程
-
图像经过第一个卷积块之后,3 × 84 × 84变成64 × 42 × 42(2 × 2最大池化);
-
经过第二个卷积块之后,变成64 × 21 × 21;
-
第三个卷积块输出64 × 10 × 10;
-
第四个卷积块输出64 × 5 × 5。
经过5 × 5的最大池化后则输出64 × 1 × 1,再按照channel展平为64维。
第一个卷积块如下如图所示:

在最后的卷积层之后,Conv-64F还包括一个全连接层,用于将特征图转换为分类输出。全连接层的输出经过softmax函数激活,得到最终的分类结果。
总体来说,Conv-64F主干网络是一个相对简单的卷积神经网络结构,但在许多图像分类和目标识别任务中已经表现出良好的性能。
Resnet12
Resnet12包含4个残差块,每个残差块有3个卷积层。“12”表示一共有12个卷积层;
一个残差块包含,如图(a):
- kernel=3, stride=1, padding=1的卷积层+ Batchnorm层+ leakyReLU层;
- kernel=3, stride=1, padding=1的卷积层+ Batchnorm层+ leakyReLU层;
- kernel=3, stride=1, padding=1的卷积层+Batchnorm层;
- 下采样层包含kernel=1, stride=1, padding=0的卷积层+ Batchnorm层;
- 最后再经过leakyReLU层,2 × 2的最大池化层,以及使用DropBlock防止过拟合。
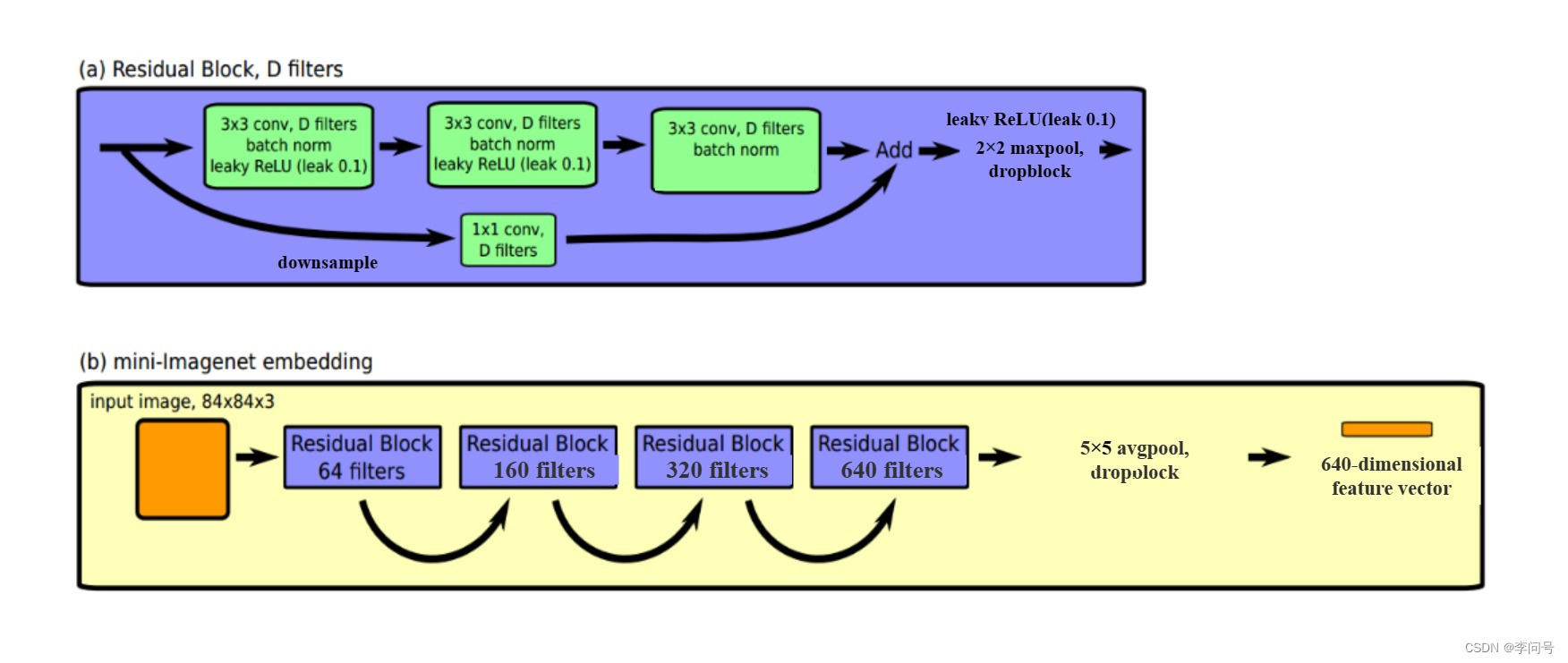
图像shape的变化过程
- 图像经过第一个残差块之后,3 × 84 × 84变成64 × 42 × 42(2 × 2最大池化);
- 经过第二个残差块之后,变成160 × 21 × 21;
- 第三个残差块输出320 × 10 × 10;
- 第四个残差块输出640 × 5 × 5。
- 经过5 × 5的平均池化后输出640 × 1 × 1,使用DropBlock防止过拟合,再按照channel展平为640维。
ResNet12被广泛应用于图像分类、目标检测和语义分割等任务中,其具有优秀的性能和较低的计算复杂度,即可以有效地解决深度神经网络中的梯度消失和梯度爆炸问题,并且可以在保持较小计算量的同时实现高精度的分类。