二分查找和差值查找
二分查找和差值查找法基本一样,仅在一处代码不同,合并到一起描述
下面先讲二分查找
概述
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
百度百科: 首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
实现
二分查找方法前提是数列是有序的
下面假设数列是从小到大排序
思路: 用递归按照所寻找的数值与中间值的大小关系,对数列进行对半分,一直递归到所寻找的数值等于中间值或者数列中的元素给递归没了。
进一步思路: 首先一个数列,我们找到数列中间的那个值,用此值和所要寻找的值进行大小比较。若此值更大,则取此值左边的数列再执行前面的操作(即找中间值再和所寻找的值比大小的操作)。若此值小,则取此值右边的数列进行再进行这样的操作。若两者相等,则表示找到了,则记录此中间值的索引,并从此索引向两边找一下看有没有相同的值(此时数列有序,可很简单的找到是不是有相同值)。若有,则也记录下这些值的索引然后返回这些索引的集合。若一直没找到,则当数列中没数据了,也结束循环,此时表示未找到
大致思路: 写一个方法,作为递归的方法体,此方法接收四个参数,分别是:原数列(这里我们用数组)、每次递归所需要数列在数组中的起始点和终止点的索引值、要寻找的值。要两个点的索引值作用就是为了对数列进行中分,我们借由每次递归中,对两点索引传入值的不同来对数列进行对半分。起始终止两点决定了当前的递归是对数组中的那一部分数列进行操作。
在方法体中,我们先获得当前数列的中间值的索引,然后获得中间值,然后用中间值和所要寻找的值进行大小比较。
若中间值大,则进入下一次递归,下一次的递归传入的参数中,把终止位置的参数索引传入(中间值的索引+1),起始位置索引不变,其他参数也不变
若中间值小,则进入下一次递归,下一次的递归传入的参数中,把起始位置的参数索引传入(中间值的索引+1),终止位置索引不变,其他参数也不变
若两者相等,则表示找到此值在数列中的位置,记录下此中间值的索引,并从此索引向两边找一下看有没有相同的值(此时数列有序,可很简单的找到是不是有相同值)
若有,则也记录下这些值的索引然后返回这些索引的集合。
作为一个递归的方法体,我们得为递归进行考虑,所以在此方法体内,一开始,我们得先判断是否达到了递归结束的另一个条件,即是否此时递归中,起始位置是否大于终止位置,
若大于则表示在此数组中未找到所要寻找的数据,直接返回一个空集合。这里需要知道几种情况,当起始位置等于终止位置,则表示此时数列中仅有一个数据,若大于,则表示一个数据也没了
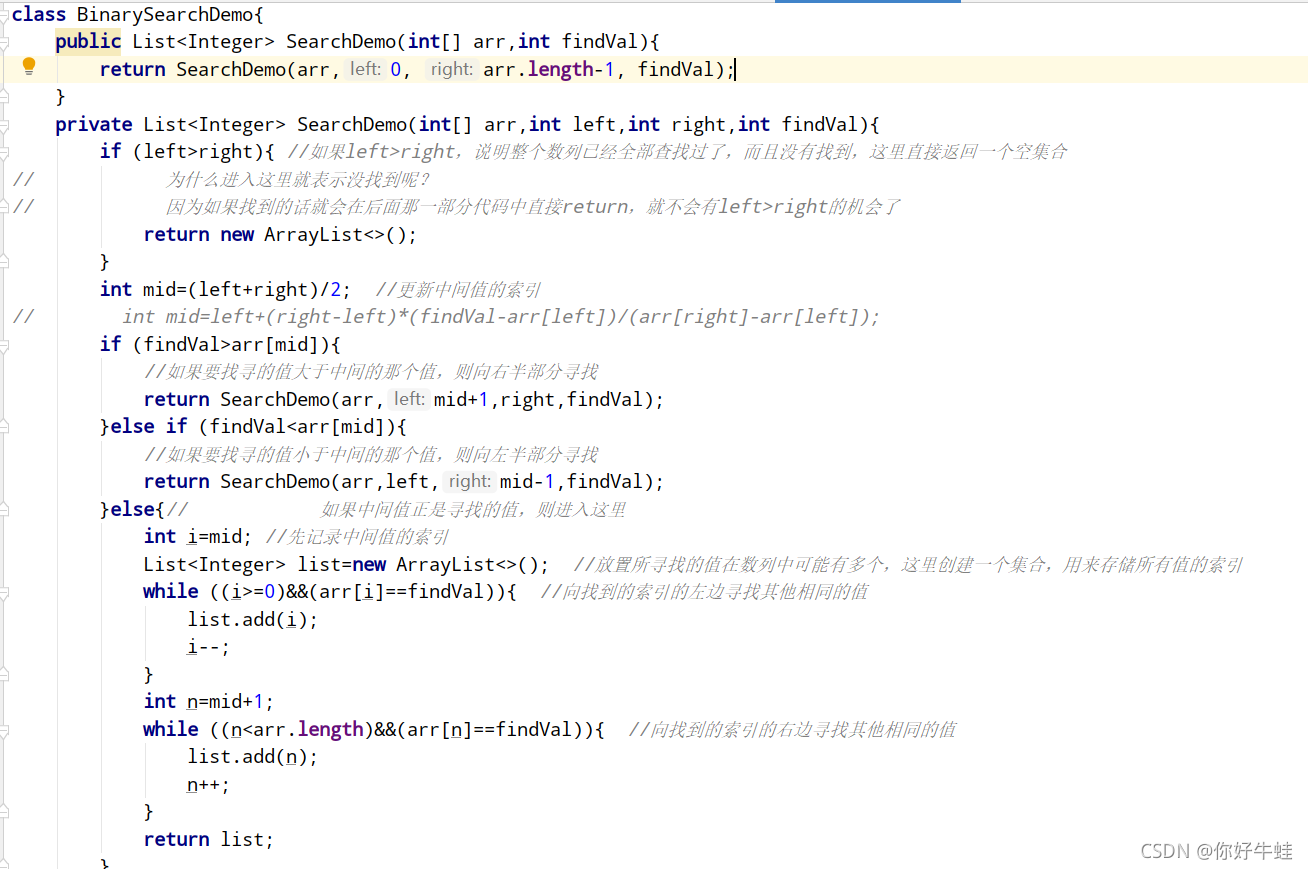
上面是二分查找的主体代码
二分查找和差值查找仅差了一点东西,即对中间值的取值更新上和退出递归的条件判断上
int mid=left+(right-left)*(findVal-arr[left])/(arr[right]-arr[left]);
百度百科: 插值查找,有序表的一种查找方式。插值查找是根据查找关键字与查找表中最大最小记录关键字比较后的查找方法。插值查找基于二分查找,将查找点的选择改进为自适应选择,提高查找效率。
这里的自适应,指的就是他这个特殊的更新mid值的方法
在插值查找中,mid的自适应公式是这样的:int mid=(left+right)/2;变为int mid=left+(right-left)*(findVal-arr[left])/(arr[right]-arr[left]);
我也不知道这个公式从哪来的,但是确实可以加快查找速度
在结束递归的条件判断上,需要更改一下:

多一个left=right,这是为了防止arr[right]-arr[left]=0导致的除0异常
后面findVal<arr[0]||findVal>arr[arr.length-1],表示若寻找的数据大于数组最大的元素或者小于数组最小的元素,则直接返回,第一可以加快速度,而是也是最重要的一点,就是为了防止数组索引越界,因为所寻找的数据也参与了运算,防止所寻找的数据过大导致的mid过大,而使数组索引越界。
不知道为什么,我在测试的时候,遇到过几次死递归的情况,就中间值的那个索引一直循环一段数字,或者干脆就直接是循环一个数字。
全部代码:
import java.util.ArrayList;
import java.util.List;
public class BinarySearch {
public static void main(String[] args) {
BinarySearchDemo searchDemo=new BinarySearchDemo();
int[] array={
1,2,3,4,5,6,7,8,9,10,11,12};
int Array[]=new int[8000];
for (int i = 0; i < 8000; i++) {
Array[i]= (int) (Math.random()*8000);
}
QuickSortDemo sortDemo=new QuickSortDemo();
sortDemo.SortDemo(Array);
Long time1=System.currentTimeMillis();
System.out.println(searchDemo.SearchDemo(Array, 452));
System.out.println("耗时(毫秒)"+(System.currentTimeMillis()-time1));
}
}
//二分查找方法前提是数列是有序的
//下面假设数列是从小到大排序
//思路:用递归按照所寻找的数值与中间值的大小关系,对数列进行对半分,一直递归到所寻找的数值等于中间值或者数列中的元素给递归没了
//进一步思路:首先一个数列,我们找到数列中间的那个值,用此值和所要寻找的值进行大小比较,若此值更大,则取此值左边的数列再执行前面的操作(即找中间值再和所寻找的值比大小的操作)
//若此值小,则取此值右边的数列进行再进行这样的操作,若两者相等,则表示找到了,则记录此中间值的索引,并从此索引向两边找一下看有没有相同的值(此时数列有序,可很简单的找到是不是有相同值)
//若有,则也记录下这些值的索引然后返回这些索引的集合。若一直没找到,则当数列中没数据了,也结束循环,此时表示未找到
//大致思路:写一个方法,作为递归的方法体,此方法接收四个参数,分别是:原数列(这里我们用数组)、每次递归所需要数列在数组中的起始点和终止点的索引值、要寻找的值
//要两个点的索引值作用就是为了对数列进行中分,我们借由每次递归中,对两点索引传入值的不同来对数列进行对半分。起始终止两点决定了当前的递归是对数组中的那一部分数列进行操作
//在方法体中,我们先获得当前数列的中间值的索引,然后获得中间值,然后用中间值和所要寻找的值进行大小比较,
//若中间值大,则进入下一次递归,下一次的递归传入的参数中,把终止位置的参数索引传入(中间值的索引+1),起始位置索引不变,其他参数也不变
//若中间值小,则进入下一次递归,下一次的递归传入的参数中,把起始位置的参数索引传入(中间值的索引+1),终止位置索引不变,其他参数也不变
//若两者相等,则表示找到此值在数列中的位置,记录下此中间值的索引,并从此索引向两边找一下看有没有相同的值(此时数列有序,可很简单的找到是不是有相同值)
// 若有,则也记录下这些值的索引然后返回这些索引的集合。
//作为一个递归的方法体,我们得为递归进行考虑,所以在此方法体内,一开始,我们得先判断是否达到了递归结束的另一个条件,即是否此时递归中,起始位置是否大于终止位置,
// 若大于则表示在此数组中未找到所要寻找的数据,直接返回一个空集合。这里需要知道几种情况,当起始位置等于终止位置,则表示此时数列中仅有一个数据,若大于,则表示一个数据也没了
class BinarySearchDemo{
public List SearchDemo(int[] arr,int findVal){
return SearchDemo(arr,0, arr.length-1, findVal);
}
private List SearchDemo(int[] arr,int left,int right,int findVal){
if (left>=right||findVal<arr[0]||findVal>arr[arr.length-1]){
//如果left>right,说明整个数列已经全部查找过了,而且没有找到,这里直接返回一个空集合
// 这里需要再加一个=号,为了防止除0异常
return new ArrayList<>();
// 为什么进入这里就表示没找到呢?
// 因为如果找到的话就会在后面那一部分代码中直接return,就不会有left>right的机会了
}
// int mid=(left+right)/2; //更新中间值的索引
int mid=left+(right-left)*(findVal-arr[left])/(arr[right]-arr[left]);
int midValue = arr[mid];
if (findVal>midValue){
//如果要找寻的值大于中间的那个值,则向右半部分寻找
return SearchDemo(arr,mid+1,right,findVal);
}else if (findVal<midValue){
//如果要找寻的值小于中间的那个值,则向左半部分寻找
return SearchDemo(arr,left,mid-1,findVal);
}else{
// 如果中间值正是寻找的值,则进入这里
int i=mid; //先记录中间值的索引
List<Integer> list=new ArrayList<>(); //放置所寻找的值在数列中可能有多个,这里创建一个集合,用来存储所有值的索引
while ((i>=0)&&(arr[i]==findVal)){
//向找到的索引的左边寻找其他相同的值
list.add(i);
i--;
}
int n=mid+1;
while ((n<arr.length)&&(arr[n]==findVal)){
//向找到的索引的右边寻找其他相同的值
list.add(n);
n++;
}
return list;
}
}
}
这里顺便测试了一下查找速度,QuickSortDemo sortDemo=new QuickSortDemo(); sortDemo.SortDemo(Array);是上一篇文章中写的快速排序
斐波那契查找
斐波那契查找我感觉是个很怪的东西,他又名黄金分割查找,顾名思义,其实斐波那契查找就是每次从黄金分割点对数列进行分割,其余的就跟二分查找一样,为啥非要在黄金分割点进行分割???我确实搞不明白,而且在测试的时候,我发现这个速度好像还更慢了
在这个查找中,最重要的是如何找到黄金分割的那个点
斐波那契数列其实是一个很奇妙的数列,这个数列越往后,数列的前一个的值与后一个值的比,就无限接近于黄金分割的那个值,即0.618… … 此处省略无限多位小数。
借由这个特性,我们可以用斐波那契数列作为辅助,就可以很简单的找到数列的黄金分割点。所以,这个又叫斐波那契查找
概述
重要: 这个查找也必须建立在有序数列上
百度百科: 斐波那契搜索就是在二分查找的基础上根据斐波那契数列进行分割的。在斐波那契数列找一个等于略大于查找表中元素个数的数F[n],将原查找表扩展为长度为F[n](如果要补充元素,则补充重复最后一个元素,直到满足F[n]个元素),完成后进行斐波那契分割,即F[n]个元素分割为前半部分F[n-1]个元素,后半部分F[n-2]个元素,找出要查找的元素在那一部分并递归,直到找到。
简单来说:
首先,这个查找的方法也是一种二分查找,不过他不是中分,数列的起始位置到分割点间元素的个数,比上整个数列元素的个数接近于黄金分割的那个数值,按照这样的方式来分割,来找分割点,由于斐波那契数列的特性,可以利用斐波那契数列中的值来寻找分割点,即先找到斐波那契数列中的一个值,要求此值(即为F[n])大于或等于而且最接近数列中元素的个数,若F[n]大于数列中元素的个数,则将原数列扩充到长度为F[n],扩充的位置用0来填充。
然后由于斐波那契数列F[n]=F[n-1]+F[n-2],而且,F[n-1]/F[n]无限接近与0.618即黄金分割值
所以F[n-1]-1即为F[n]数列的分割点的索引。为什么要-1?因为F[n-1]表示的是一个长度,他从1开始,索引是从0开始
有因为F[n-2]是F[n-1]前面的那个值,所以F[n-1]数列的分割点就是F[n-2]-1
以此类推
但是注意一点: 我们是在一个数组中进行操作的,每次需要查找的那段数列的起始位置的索引不一定是0,索引每次的分割点其实是起始位置索引+F[n-1]-1
实现
实现思路: 首先写一个函数用于创建一个斐波那契数列,用于后续的使用
然后再写一个方法体,即实现斐波那契查找的方法体,首先,用循环找到不小于且最接近数列长度的那个斐波那契数列的值,然后用循环把原数列扩充到对应的大小
然后正式开始查找,用while循环,循环结束条件是数列中没有数据了即起始位置大于终止位置的时候,或者找到了结果的时候
首先找到分割点,然后判断分割点元素的大小和所寻找数据的大小关系
若分割点更大,则向分割后左边部分的数列寻找,并更新所需斐波那契数值的索引(用于后续的寻找分割点)。怎么更新具体在下面代码的注释中
若分割点更小,则向分割点右边部分的数列寻找,并更新所需斐波那契数值的索引(用于后续的寻找分割点)。怎么更新具体在下面代码的注释中
代码如下:
import java.util.Arrays;
public class FibonacciSearch {
public static void main(String[] args) {
FibonacciSearchDemo searchDemo=new FibonacciSearchDemo();
int[] array={
0,1,3,5,7,8,9,10,11,12,45,78,49};
int Array[]=new int[8000000];
for (int i = 0; i < 8000000; i++) {
Array[i]= (int) (Math.random()*8000000);
}
QuickSortDemo sortDemo=new QuickSortDemo();
sortDemo.SortDemo(Array);
Long time1=System.currentTimeMillis();
System.out.println(searchDemo.SearchDemo(Array, 12));
System.out.println("耗时(毫秒)"+(System.currentTimeMillis()-time1));
}
}
class FibonacciSearchDemo{
public int SearchDemo(int[] arr,int key){
int low=0; //记录数列的起始索引
int high= arr.length-1; //记录数列的终止索引
int[] fib=getFibArr(100); //接收斐波那契数列
int k=0;//用来记录所需的斐波那契数值在斐波那契数列中的索引
int mid;//mid用来记录数列中的中分点
// 在斐波那契数列中寻找一个数值,要求此值不小于数列的长度,且最接近数列的长度
while (high+1>fib[k]-1){
//为什么要加一?因为hight表示的是最大索引值,他和数列的长度差1
// 为什么fib[k]-1,因为我们要找到那个值不小于数列的长度,而且,是最接近数列的长度的那个值
k++;
}
// 数列的原长度可能达不到前面找到的那个数值的大小,这里需要将数列扩增
int[] temp= Arrays.copyOf(arr,fib[k]);//这个方法可以将arr数组增长到fib[k],增加的元素都默认为0
// 我们需要的是用数列的最后一个元素来填充数组,所以需要修改后面的0
for (int i = high+1; i < temp.length; i++) {
temp[i]=arr[high];
}
while (low<=high){
mid=low+fib[k-1]-1;//为啥最后面要减一?因为fib[k-1]在此处表示的是一个数量,即从low索引到中分点间的元素个数,而此处我们想要的mid表示的是一个索引
// 这里为啥是fib[k-1]?因为fib[k]表示的是这个数列的长度,所以这个数列的黄金分割点到数列头的长度就是fib[k]的前一个数值,我们这里需要的就是黄金分割点,所以k-1
if (key<temp[mid]){
//若所寻找的值小于中间值,则进入分割后左边的数列,即F[k-1]的那一部分数列
high=mid-1;
k--;
// 为什么这里k自减?因为进入下次循环的时候,从数列头到这个黄金分割点(即f[k-1])的长度,就是我们下次循环时候数列的总长,
// 而这个数列的黄金分割点正是f[k-1]的前一个数值,所以这里我们需要得到的是斐波那契数列中的前一个数值,即fib[k-1]的前一个数值,所以是k--
}else if (key>temp[mid]){
//若所寻找的值大于中间值,则进入分割后右边的那一部分数列,即F[k-2]的那一部分
low=mid+1;
k-=2;
// 这里为什么是k自减2?因为当数列经过黄金分割之后,如果key>temp[mid],即key在经过黄金分割后的数列的后半部分,
// 则我们下次就需要把后半部分的这个数列进行黄金分割找值,如果要对这个数列黄金分割,我们需要先知道这个数列的长度,这个数列的长度就很明显
// 因为斐波那契数列f(n)=f(n-1)+f(n-2),由因为黄金分割后数列后半部分长度不可能大于前半部分长度,所以后半部分长度就是f(n-2)了,
// f(n-2)的黄金分割点就是这次黄金分割点的上上个数值,即f[k-1]的上上个数值,也就是f[k-1-1-1],所以f[k-1-1]的黄金分割点又是f[k-1-1]的上一个数值
// 所以此处是k自减2
// 明明后面是个减三个1为啥这里只k自减两次?因为,在每次循环开始之前,得到的中间值都是low+fib[k-1]-1,每次用的值不是k而是k-1
}else {
return mid;
}
}
return -1;
}
public int[] getFibArr(int n){
int[] fib=new int[n];
fib[0]=0;
if (n==1){
return fib;
}
fib[1]=1;
if (n==2){
return fib;
}
for (int i = 2; i < n; i++) {
fib[i]=fib[i-1]+fib[i-2];
}
return fib;
}
}
这里顺便测试了一下在8百万个数据中查找的速度,QuickSortDemo sortDemo=new QuickSortDemo(); sortDemo.SortDemo(Array);是上一篇文章中写的快速排序