文章目录
1 理论知识
1.1 支持度、置信度、提升度
Support(支持度):表示某个项集出现的频率,也就是包含该项集的交易数与总交易数的比例。例如P(A)表示项集A的比例, P ( A ∩ B ) P(A\cap B) P(A∩B)表示项集A和项集B同时出现的比例。
Confidence(置信度):表示当A项出现时B项同时出现的频率,记作{A→B}。换言之,置信度指同时包含A项和B项的交易数与包含A项的交易数之比。公式表达:{A→B}的置信度= P ( A ∣ B ) = P ( A ∩ B ) / P ( B P(A|B)=P(A\cap B) / P(B P(A∣B)=P(A∩B)/P(B
Lift(提升度):指A项和B项一同出现的频率,但同时要考虑这两项各自出现的频率。公式表达:{A→B}的提升度={A→B}的置信度/P(B)= P ( A ∩ B ) / P ( B ) = P ( A ∩ B ) / ( P ( A ) ∗ P ( B ) ) P(A\cap B) / P(B)=P(A\cap B)/ (P(A)*P(B)) P(A∩B)/P(B)=P(A∩B)/(P(A)∗P(B))。提升度反映了关联规则中的A与B的相关性,提升度>1且越高表明正相关性越高,提升度<1且越低表明负相关性越高,提升度=1表明没有相关性。负值,商品之间具有相互排斥的作用。
1.2 Apriori算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
该算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递推的方法。
Apriori算法采用了逐层搜索的迭代的方法,算法简单明了,没有复杂的理论推导,也易于实现。但其有一些难以克服的缺点:
(1)对数据库的扫描次数过多。
(2)Apriori算法会产生大量的中间项集。
(3)采用唯一支持度。
(4)算法的适应面窄。
1.3 FP-Growth算法
针对Apriori算法的固有缺陷,J.Han等提出了不产生候选挖掘频繁项集的方法:FP-树频集算法。采用分而治之的策略,在经过第一遍扫描之后,把数据库中的频集压缩进一棵频繁模式树(FP-tree),同时依然保留其中的关联信息,随后再将FP-tree分化成一些条件库,每个库和一个长度为1的频集相关,然后再对这些条件库分别进行挖掘。当原始数据量很大的时候,也可以结合划分的方法,使得一个FP-tree可以放入主存中。实验表明,FP-growth对不同长度的规则都有很好的适应性,同时在效率上较之Apriori算法有巨大的提高。
2 导包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from efficient_apriori import apriori
from sklearn.datasets import load_breast_cancer
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules, fpgrowth
3 数据预处理
查看官网数据集解释:
- Class Name: 2 (democrat, republican)
- handicapped-infants: 2 (y,n)
- water-project-cost-sharing: 2 (y,n)
- adoption-of-the-budget-resolution: 2 (y,n)
- physician-fee-freeze: 2 (y,n)
- el-salvador-aid: 2 (y,n)
- religious-groups-in-schools: 2 (y,n)
- anti-satellite-test-ban: 2 (y,n)
- aid-to-nicaraguan-contras: 2 (y,n)
- mx-missile: 2 (y,n)
- immigration: 2 (y,n)
- synfuels-corporation-cutback: 2 (y,n)
- education-spending: 2 (y,n)
- superfund-right-to-sue: 2 (y,n)
- crime: 2 (y,n)
- duty-free-exports: 2 (y,n)
- export-administration-act-south-africa: 2 (y,n)
# Pandas设置
pd.set_option("display.max_columns", None) # 设置显示完整的列
pd.set_option("display.max_rows", None) # 设置显示完整的行
pd.set_option("display.expand_frame_repr", False) # 设置不折叠数据
pd.set_option("display.max_colwidth", 100) # 设置列的最大宽度
# 加载数据集
dataset = pd.read_csv('../data/house-votes-84.data', delimiter=',', header=None)
columns = [
'党派', '残疾人婴幼儿法案', '水项目费用分摊', '预算决议案', '医生费用冻结议案', '萨尔瓦多援助',
'校园宗教团体决议', '反卫星禁试决议', '援助尼加拉瓜反政府', 'MX导弹议案', '移民决议案', '合成燃料公司削减决议',
'教育支出决议', '超级基金起诉权', '犯罪决议案', '免税出口决议案', '南非出口管理决议案'
]
dataset.columns = columns
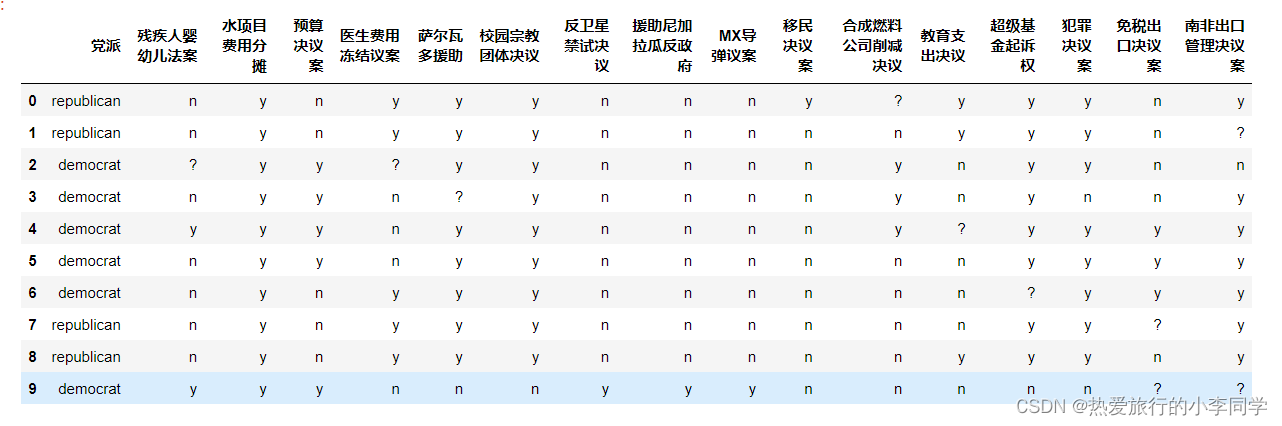
dataset.head(10)
dataset['残疾人婴幼儿法案'].unique()
for col in columns:
dataset[col] = dataset[col].apply(lambda x: col + ':' + x)
print(len(dataset))
dataset.head()
# 编码
encoder = TransactionEncoder()
new_array = encoder.fit_transform(dataset.values)
new_df = pd.DataFrame(data=new_array, columns=encoder.columns_)
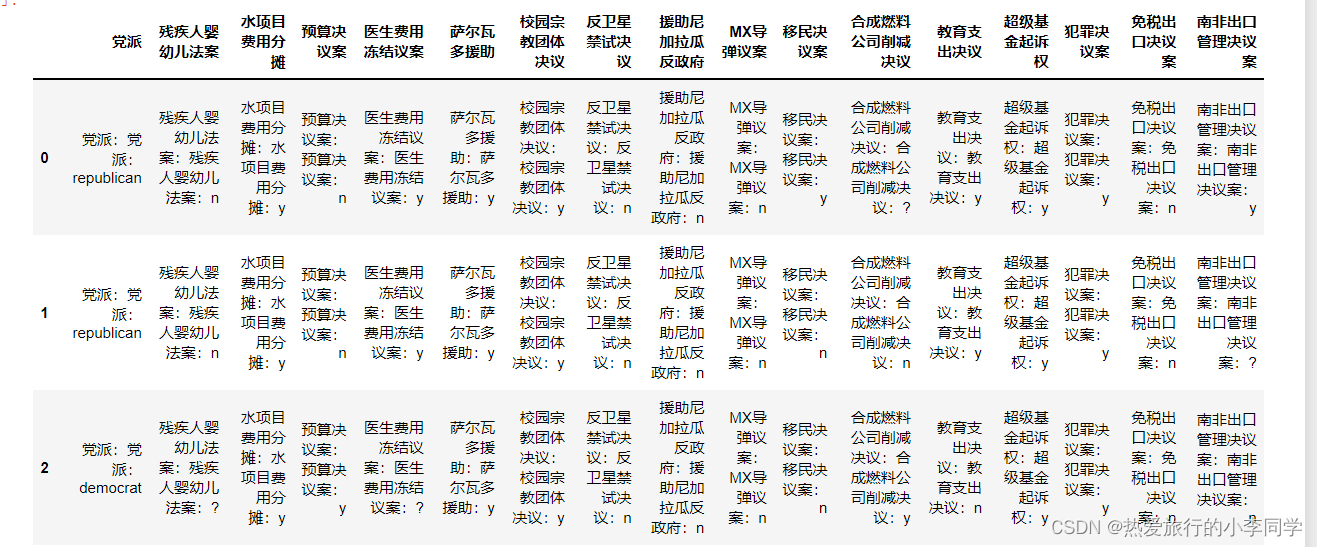
new_df.head()
数据初始形式:
数据初步编码形式:
最终数据形式:

4 挖掘关联规则
Apriori算法
最小支持度设置为0.5
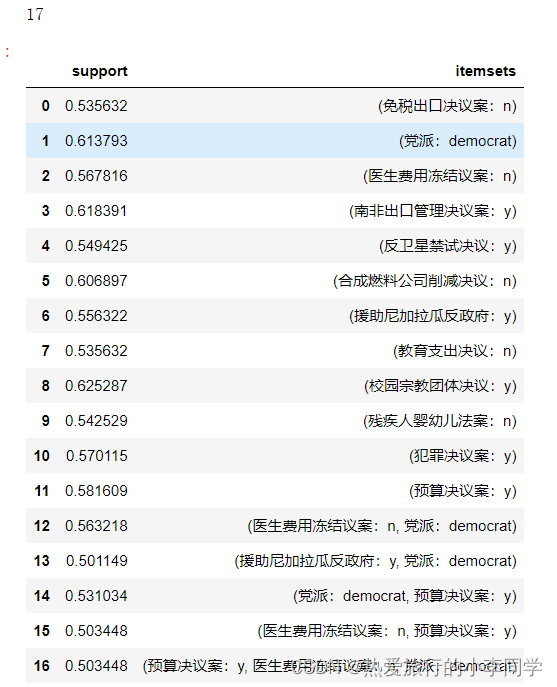
# 挖掘频繁项集 最小支持度设置为0.5
fre_itemset1 = apriori(df=new_df, min_support=0.5, use_colnames=True)
print(len(fre_itemset1))
fre_itemset1 # 17条
最小支持度设置为0.45
# 挖掘频繁项集 最小支持度设置为0.45
fre_itemset2 = apriori(df=new_df, min_support=0.45, use_colnames=True)
print(len(fre_itemset2))
fre_itemset2 # 44条
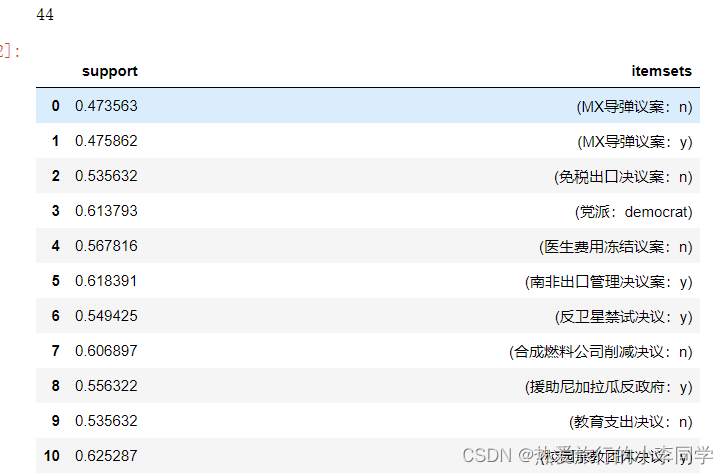
最小支持度设置为0.5 最小置信度设置为0.8
# 关联规则
# 最小支持度设置为0.5 最小置信度设置为0.8
rules1 = association_rules(df=fre_itemset1, metric='confidence', min_threshold=0.8)
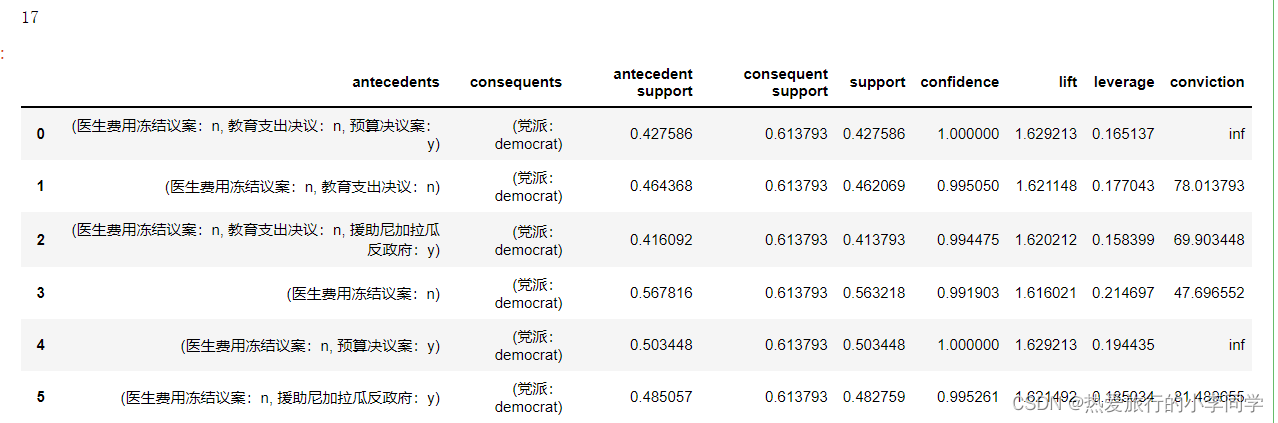
rules1 # 14条
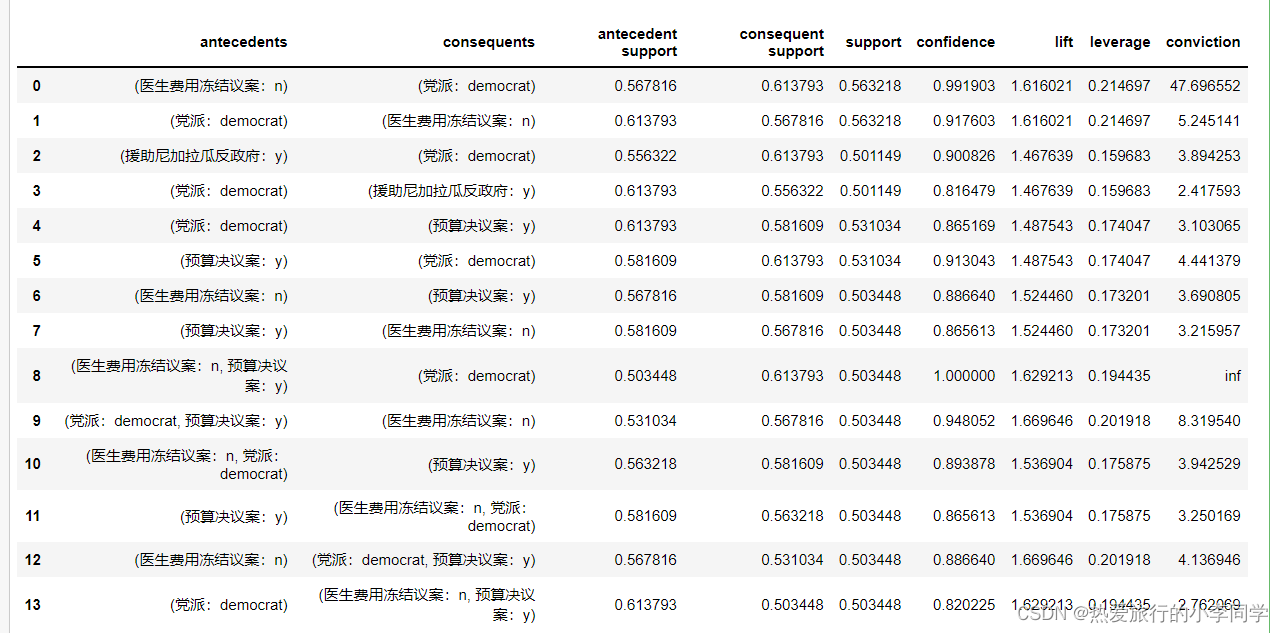
最小支持度设置为0.8 最小置信度设置为0.9
# 最小支持度设置为0.8 最小置信度设置为0.9
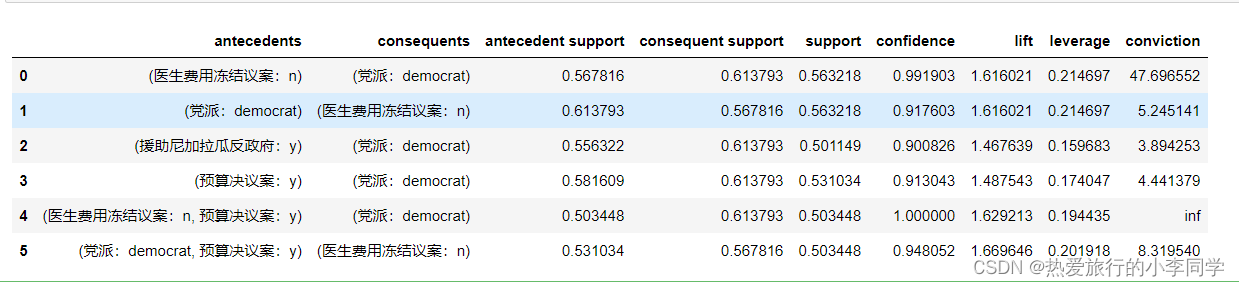
rules2 = association_rules(df=fre_itemset1, metric='confidence', min_threshold=0.9)
rules2 # 6条
FP-Growth算法
最小支持度0.4
# fp-growth算法 最小支持度0.4
fre_itemset3 = fpgrowth(df=new_df, min_support=0.4, use_colnames=True)
print(len(fre_itemset3))
fre_itemset3.tail()
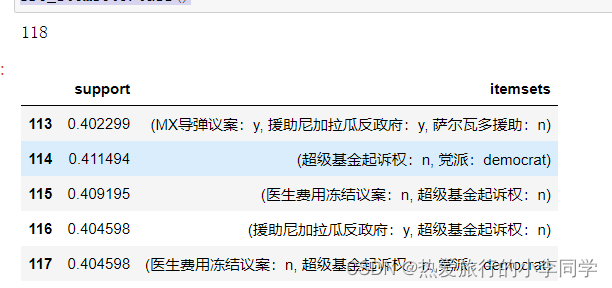
最小支持度0.4,最小置信度0.99
# 关联规则
# 最小支持度设置为0.4 最小置信度设置为0.99
rules3 = association_rules(df=fre_itemset3, metric='confidence', min_threshold=0.99)
print(len(rules3))
rules3