题目:
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] = [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接,并且没有顶点存在与自身相连的边。
请你确定是否存在从顶点 source 开始,到顶点 destination 结束的 有效路径 。
给你数组 edges 和整数 n、source 和 destination,如果从 source 到 destination 存在 有效路径 ,则返回 true,否则返回 false 。
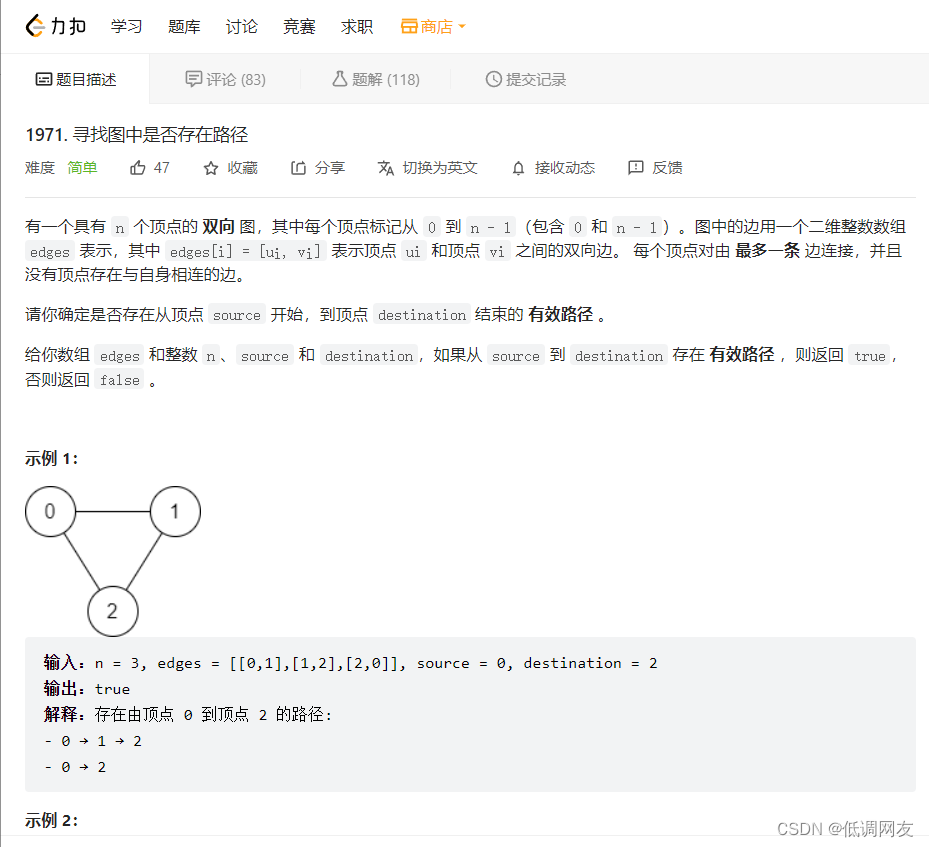
第一种方法:深搜
class Solution {
List<Integer>[] edgeforv; //每一个顶点所对应直接相连的顶点,
boolean[] visited; //判断顶点是否被访问过
public boolean validPath(int n, int[][] edges, int source, int destination) {
edgeforv = new List[n];
visited = new boolean[n];
for(int i = 0; i < n; i++){
edgeforv[i] = new ArrayList<Integer>();
}
for(int[] edge : edges){
edgeforv[edge[0]].add(edge[1]); //将每个顶点的直接相连顶点存进来
edgeforv[edge[1]].add(edge[0]); //将每个顶点的直接相连顶点存进来
//这里的处理就是为了深搜广搜做准备
}
return dfs(source,destination);
}
public boolean dfs(int source,int destination){
if(visited[destination]) return true;
visited[source] = true;
List<Integer> nextVertys = edgeforv[source];
//nextVertys是下个顶点的集合
for(int i = 0; i < nextVertys.size(); i++){
int next = nextVertys.get(i);
if(!visited[next] && dfs(next,destination)){
return true;
}
}
return visited[destination];
}
}
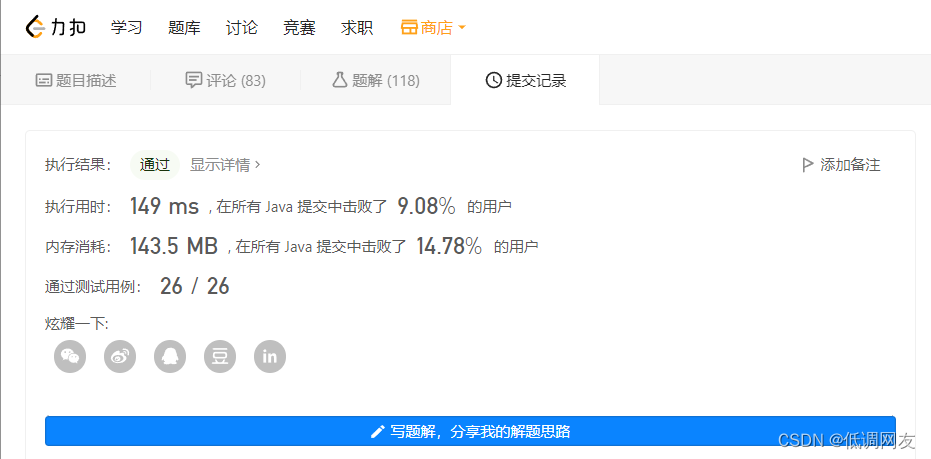
从这里可以看出性能很差
第二种解法:广搜
class Solution {
public boolean validPath(int n, int[][] edges, int source, int destination) {
List<Integer>[] edgeforv = new List[n];
for(int i = 0; i < n; i++){
edgeforv[i] = new ArrayList<Integer>();
}
for(int[] edge : edges){
edgeforv[edge[0]].add(edge[1]);//将每个顶点的直接相连顶点存进来
edgeforv[edge[1]].add(edge[0]);//将每个顶点的直接相连顶点存进来
}
boolean[] visited = new boolean[n];//判断是否访问过
//广搜算法开始
Queue<Integer> visitedges = new LinkedList<>();
visitedges.offer(source);
while(!visitedges.isEmpty() && !visited[destination]){
int verty = visitedges.poll();
List<Integer> verty_edge = edgeforv[verty];
for(int i = 0; i < verty_edge.size(); i++){
if(!visited[verty_edge.get(i)]){
visitedges.offer(verty_edge.get(i));
}
}
visited[verty] = true;
}
return visited[destination];
}
}
//可以将List<>[] 改进为List<List<>>, 上面是广搜
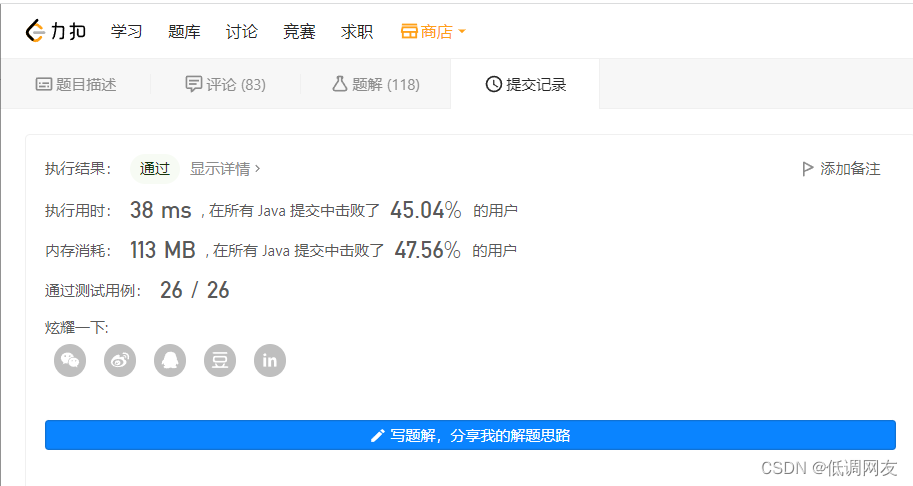
广搜性能处于中等。 比深搜好。
第三种解法:并查集
思想:
将连通的点合并成一个集合,最后判断俩个点是否在同一个集合(即双方的父亲是否一样)
经典例题:判断a,b是否为亲戚(自行百度)
并查集需要分三步走:
1.初始化 --> init()
2.1 找祖先 --> find(son) --> 高级,路径压缩
2.2加入边(合并集合) -->union(a, b)方法
3. (题目问题)判断祖先是否一样 (也等价于能否连通)
1.init()
void init(int[] father){
//刚开每个点都是独立的集合,即每个点的父亲都是它本身
for (int i = 0; i < father.length; ++i) {
father[i] = i;
}
}
2.union: 将a集合 合并到 b集合里面,即将 b变成a父亲的父亲,即b为a的爷爷
void union(int a, int b){
int fatherA = find(a);
int fatherB = find(b);
if(fatherA == father) return;
father[fatherA] = fatherB;
}
3.find()
给出俩种方式:
1.路径压缩:在find(father[v])的时候已经把根结点里包含的所有子节点的父节点都指向它, 即祖先是所有还是子节点的父亲。 所有下一次union的时候从同一个点开始就能立马找到它直接相连的父节点了 (可以参考下面的2.非路径压缩以及下面的图)
int find(int v){
if(v == father[v]) return v;
else{
father[v] = find(father[v]); //此处为路径压缩,在find(father[v])的时候已经把根结点里包含的所有子节点的父节点都指向它, 即祖先是所有还是子节点的父亲
return father[v];
}
}
2.非路径压缩–>不断的向上找父亲,返回最顶层的父亲,但是每个子节点的父亲都是直接相连的父亲,每次查找都要不断的递归,非常慢
比如(4,5)(4,6)… (4, 1000)
那么每次 union(a,b)在里面调用 find(v)的时候就会非常慢 (都从4一步一步到达最上层)
int find(int v){
if(v == father[v]) return v;
else{
return find(father[v]);
}
}
非路径压缩和路径压缩可从图直观看出:

最后再上上述题目的题解:(下面的join方法就是上述的union方法)
// 并查集
class Solution {
// 节点数量3 到 1000
int[] father;
// 并查集初始化
public void init() {
for (int i = 0; i < father.length; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
public int find(int u) {
/*
这里递归的意义是,如果我的集合没有改变,那我的祖先就是我自己
如果我的集合被合并了,那我只能去找合并我的father,如果father不是祖先,那我就找father的father
直到找到祖先。
如果这样找,就需要每次遍历n,过程跟下面注释掉的find函数一样,就会超时
*/
if(u == father[u]) return u;
else{
father[u] = find(father[u]);
return father[u];
}
}
// 将v->u 这条边加入并查集
public void join(int u, int v) {
u = find(u);
v = find(v);
if (u == v) return ;
father[v] = u;
}
// 判断 u 和 v是否找到同一个根,本题用不上
public boolean same(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
public boolean validPath(int n, int[][] edges, int source, int destination) {
father = new int[n];
init();
for(int i = 0; i < edges.length; i++) {
join(edges[i][0], edges[i][1]);
}
return same(source, destination);
}
// public void find(int x, int y){
// if(parent[x] != parent[y]){
// if(parent[x] < parent[y]){
// int root = parent[y];
// for(int i = 0; i < parent.length;i++){
// if(parent[i] == root){
// parent[i] = parent[x];
// }
// }
// }else{
// int root = parent[x];
// for(int i = 0; i < parent.length;i++){
// if(parent[i] == root){
// parent[i] = parent[y];
// }
// }
// }
// }
// for(int i = 0; i < parent.length; i++){
// System.out.print(parent[i] + " ");
// }
// System.out.println(" ");
// }
//每次遍历n,超时
}
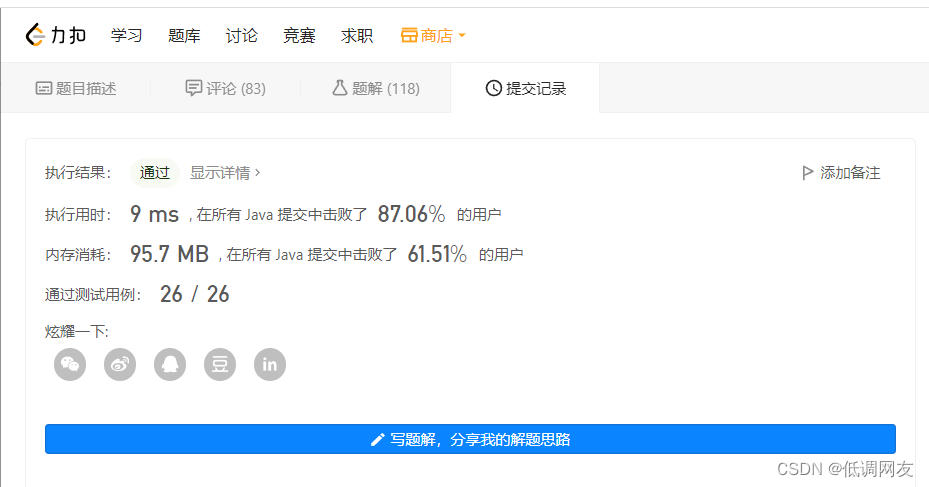
并查集的思路就是每次都去合并 相连顶点的集合。
百度思想:此处有经典例题,找亲属
百度:并查集
题目记录完毕