StanfordcoreNLP
这个老早就出来了,用java写的,但是已经有很多比他效果好的了。
Stanza
2020ACL发表的,看名字就知道和上一个是同一家的。
用已经切好词的句子进行依存分析。
这个功能有什么好处呢?
一开始一直不知道这个功能的好处,这个就是在你已有数据集的基础上,想加点依存或者句法等信息进去的时候,切好词放进去能确保分析结果一一对应,不然切词器用的不一样,结果是不能完美对应回去的,这样处理起来就非常恶心了。
按道理来说应该每个切词器都会有这个功能吧。
import stanza
nlp = stanza.Pipeline(lang='en', tokenize_pretokenized=True)
doc = nlp(["Stanza is a powerful$NLP library.".split()])
for sent in doc.sentences:
print(sent.print_dependencies())
输出结果:

Tankit
2021EACL文章里的
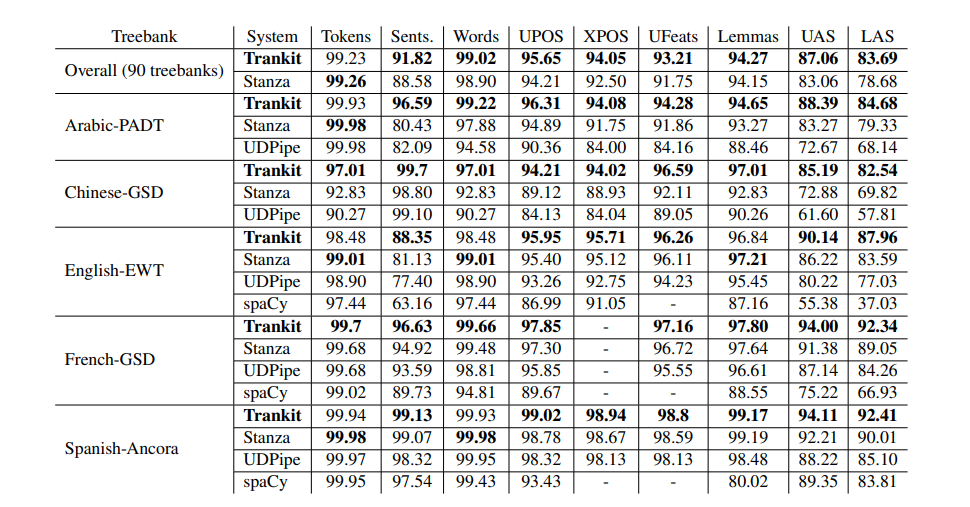
看这结果好像比Stanza好,但是实际上使用人数Stanza更多毕竟老行家,老客户多,而且github上回答问题也很积极,就是说售后工作不错,实验效果的话,可能还是Stanza会好些。
spaCy
这东西主要是快,工业用的,做研究为了效果应该不差这点时间。看过没用过。
SuPar
https://github.com/yzhangcs/parser
封装了Biaffine和CRF等用了解析依存树或者句法树的模型,不过我好像试了没运行成功,好像是模型下太慢了,用户体验其实不怎么样,但是它里面说效果是SOTA,但现在毕竟2023,只能说效果不会差,工具不算老。
总结
应该还有很多,上面主要是对应英文的,但是其实他们也大部分支持中文,对于中文也有很多,如jieba,哈工大的LTP,百度LAC,jiagu等等。
工具很多,知道名字才能进行信息搜集和对比,不然要干啥都不知道。