torchaudio 和 librosa 是深度学习中语音特征提取最常见的两个库,但是针对同样的特征两个库在提取 MelSpectrogram 特征的时候,得到的结果并不完全一致,这篇文章简述了一些配置和注意事项,从而使得两个库能够提取相同数值大小的特征。
torchaudio 中的 MelSpectrogram 默认参数是:
- center = True
- pad_mode = ‘reflect’
- onesided = True
- norm = None
- mel_scale = ‘htk’
librosa.feature 中的 melspectrogram 默认参数是:
- center = True
- pad_mode = ‘constant’
- norm = ‘slaney’
- htk = False
可以看到,两个库的主要区别就是 pad_mode 、htk(mel_scale) 、norm 三点不一致,因此,要使得两个库提取的结果一致,需要:
- 统一 pad_mode ,如都改成 reflect
- htk(mel_scale)一致,这个参数表示的是在计算 mel 滤波器组的参数时,使用的是哪个公式,其中有以下两个公式:
- htk:全部都满足对数关系, m = 2595 log 10 ( 1 + f 700 ) \mathrm{m}=2595 \log_{10} \left(1+\frac{\mathrm{f}}{700}\right) m=2595log10(1+700f)
- slaney:1K 以下是线性,1K 以上满足对数关系: m = 3 f 200 ( f < 1000 ) , m = 15 + ln f 1000 ln 6.4 27 ( f > = 1000 ) \mathrm{m}=\frac{3 \mathrm{f}}{200}(\mathrm{f}<1000), \mathrm{m}=15+\frac{\ln \frac{\mathrm{f}}{1000}}{\frac{\ln 6.4}{27}} \quad(\mathrm{f}>=1000) m=2003f(f<1000),m=15+27ln6.4ln1000f(f>=1000)
- 而两个库的默认计算公式是不一样的,torchaudio 默认使用 htk,librosa 默认使用 slaney
- 能量归一化 norm:
- 在torchaudio 中,描述为:norm (str or None, optional): If “slaney”, divide the triangular mel weights by the width of the mel band
- 在 librosa 中,表述为:norm{None, ‘slaney’, or number} [scalar]
- If ‘slaney’, divide the triangular mel weights by the width of the mel band (area normalization).
- If numeric, use librosa.util.normalize to normalize each filter by to unit l_p norm. See librosa.util.normalize for a full description of supported norm values (including ±np.inf).
- Otherwise, leave all the triangles aiming for a peak value of 1.0
- 这个参数用来决定 mel 滤波器组的能量是否进行归一化,如果都设为 slaney,那么每个滤波器组的能量大小相同(也就是三角形的面积相同)
基于上面的分析,可以得到以下两种配置使得两个库能够提取到数值相同的特征(注意本文只关注特征的数值,而不关注维度和类型,如 torchaudio 得到的是三维的 tensor,而 librosa 得到的是二维的 numpy array):
import torchaudio
from torchaudio.transforms import MFCC
import librosa
path = '' # 音频文件
waveform, sample_rate = torchaudio.load(path)
print(waveform.shape)
# ----------------------------------配置1---------------------------
# torchaudio
mfcc_transform = MFCC(
sample_rate=sample_rate,
n_mfcc=13,
melkwargs={
"n_fft": 512, "hop_length": 240,
"n_mels": 40, "norm": "slaney", 'mel_scale': 'slaney'},
)
torch_mfcc = mfcc_transform(waveform)
print(torch_mfcc[0, :, 0])
# librosa
wave, sr = librosa.load(path, sr=16000)
print(wave.shape)
librosa_mfcc = librosa.feature.mfcc(
y=wave, sr=sr, n_mfcc=13, n_fft=512, hop_length=240, n_mels=40, pad_mode='reflect', htk=False)
print(librosa_mfcc[:, 0])
# ----------------------------------配置2---------------------------
# torchaudio
mfcc_transform = MFCC(
sample_rate=sample_rate,
n_mfcc=13,
melkwargs={
"n_fft": 512, "hop_length": 240,
"n_mels": 40, "norm": "slaney"},
)
torch_mfcc = mfcc_transform(waveform)
print(torch_mfcc[0, :, 0])
# librosa
wave, sr = librosa.load(path, sr=16000)
print(wave.shape)
librosa_mfcc = librosa.feature.mfcc(
y=wave, sr=sr, n_mfcc=13, n_fft=512, hop_length=240, n_mels=40, pad_mode='reflect', htk=True)
print(librosa_mfcc[:, 0])
配置1 输出:
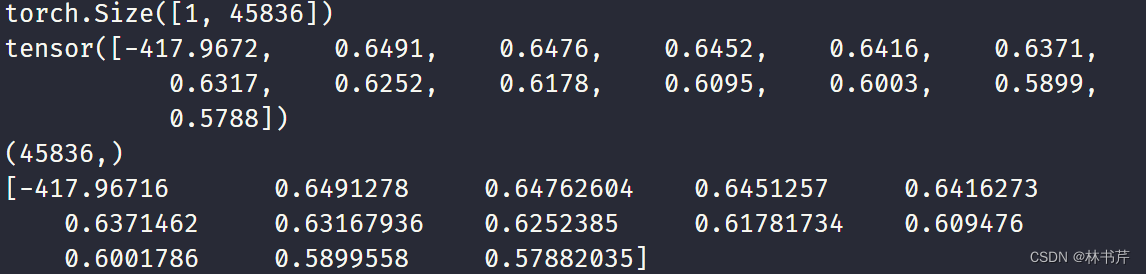
配置2 输出:
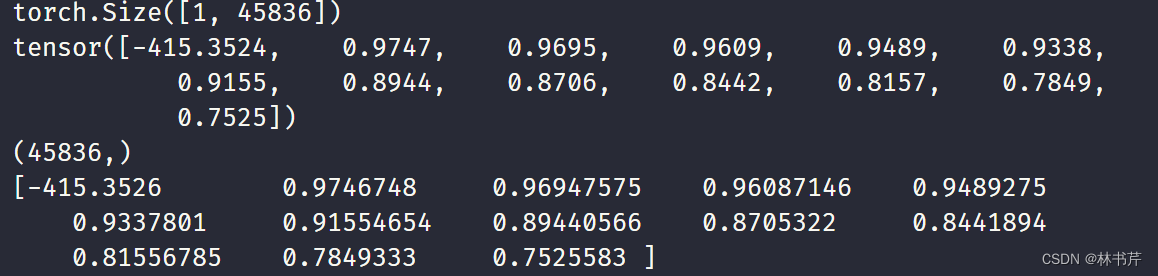
可以看到,这时候两个库提取得到的特征几乎一致(忽略数值计算的误差)。