NLP文本多样性可视化开源组件大赏:TextGrapher图谱、wordcloud词云、shifterator差异性等项目总结
一、基于wordcloud/stylecloud库进行文本词云可视化
1、使用pyecharts进行词云可视化
Apache ECharts是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,Pyecharts是echarts的python实现版本,pyecharts库下的wordcloud子类客实现词云这一任务,与Tableau生成词云的方式类似,pyecharts也要求输入的数据是经过筛选和统计好的数据,但所有图表均可交互,算是它的一项优势。
地址:https://github.com/pyecharts/pyecharts
1)实现案例
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
words = [
("我爱你", 10000), ("美丽", 6181),("天空", 4386),
("江西", 4055),("任务", 2467), ("红色", 2244),
("大海", 1868), ("人民", 1281)
]
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="案例"))
)
return c
wd = wordcloud_base()
wd.render("word_demo.html")
2、wordcloud
wordcloud.WordCloud() 方法,代表一个文本对应的词云,可以根据文本中词语出现的频率等参数绘制词云,绘制词云的形状、尺寸和颜色均可设定,并且可以给定任意一张图片,生成相应形状的词云结果。
项目地址:https://github.com/amueller/word_cloud
1)实践案例
import wordcloud
text = "An angry mob of anti-vaccine protesters stormed what they thought was BBC headquarters in London on Monday, only to discover that they had been grossly misinformed about its location, among other things.
Videos show the protesters trying to push through a police line and charge the doors of the Television Centre in west London on Monday in a misguided attempt to disrupt BBC Television’s operations. They were about eight years too late, as the U.K.’s public broadcaster moved out of that space in 2013."
w = wordcloud.WordCloud(background_color="white") # 把词云当做一个对象
w.generate(text)
w.to_file("wordcloud.png")
3、stylecloud
stylecloud基于wordcloud库,使用方法更简单一些,支持词云图图标形状设置,轻松解决词云的蒙版【预先设定图形路径】和配色问题,stylecloud可支持传入字、符串列表,可直接读取csv文件(csv有两列,word和freq),并兼容wordcloud。
地址:https://github.com/minimaxir/stylecloud
1)实践案例
在这里,同样借鉴【大邓和他的python】的开源项目,例如,给定一个保存高考的词频csv文件(高考.csv),包括两列,一列是词语word,另一列是词频freq,style-cloud可以直接进行读取。
2)代码实现
import stylecloud
stopwords = open('data/stopwords.txt', encoding='utf-8').read().split('\n')
stylecloud.gen_stylecloud(file_path='高考.csv',
font_path='SourceHanSansCN-Regular.otf',
output_name='高考.png',
icon_name='fas fa-user-graduate',//设定的图形文件
size=500,
custom_stopwords=stopwords)
二、基于TextGrapher进行文本图谱可视化展示
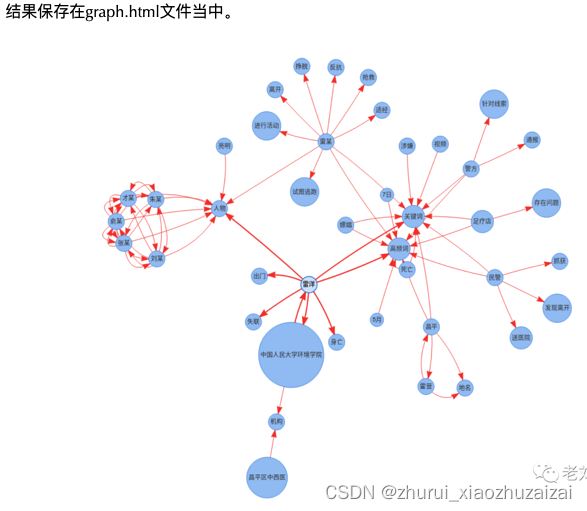
如何用图谱和结构化的方式,即以简洁的方式对输入的文本内容进行最佳的语义表示是个难题。 本项目将对这一问题进行尝试,采用的方法为:输入一篇文档,将文档进行关键信息提取,采用了高频词,关键词,命名实体识别,主谓宾短语识别等抽取方式,并尝试将三类信息进行图谱组织表示,并最终组织成图谱组织形式,形成对文章语义信息的图谱化展示。
这是老刘的一个开源项目:
项目地址:https://github.com/liuhuanyong/TextGrapher
1)代码实现
from text_grapher import *
handler = CrimeMining()
content = """
5月7日20时许,昌平警方针对霍营街道某小区一足疗店存在卖淫嫖娼问题的线索,组织便衣警力前往开展侦查。
21时14分,民警发现雷某(男,29岁,家住附近)从该足疗店离开,立即跟进,亮明身份对其盘查。雷某试图逃跑,在激烈反抗中咬伤民警,并将民警所持视频拍摄设备打落摔坏,后被控制带上车。行驶中,雷某突然挣脱看管,从车后座窜至前排副驾驶位置,踢踹驾驶员迫使停车,打开车门逃跑,被再次控制。因雷某激烈反抗,为防止其再次脱逃,民警依法给其戴上手铐,并于21时45分带上车。在将雷某带回审查途中,发现其身体不适,情况异常,民警立即将其就近送往昌平区中西医结合医院,22时5分进入急诊救治。雷某经抢救无效于22时55分死亡。
当晚,民警在足疗店内将朱某(男,33岁,黑龙江省人)、俞某(女,38岁,安徽省人)、才某(女,26岁,青海省人)、刘某(女,36岁,四川省人)和张某(女,25岁,云南省人)等5名涉嫌违法犯罪人员抓获。经审查并依法提取、检验现场相关物证,证实雷某在足疗店内进行了嫖娼活动并支付200元嫖资。目前,上述人员已被昌平警方依法采取强制措施。
为进一步查明雷某死亡原因,征得家属同意后,将依法委托第三方在检察机关监督下进行尸检。
男子“涉嫌嫖娼死亡”,家属提多个疑点 要求公开执法记录视频
5月7日晚,中国人民大学环境学院2009级硕士研究生雷洋离家后身亡,昌平警方通报称,警方查处足疗店过程中,将“涉嫌嫖娼”的雷某控制并带回审查,此间雷某突然身体不适经抢救无效身亡。
面对雷洋的突然死亡,他的家人表示现在只看到了警方的一条官方微博,对于死因其中只有一句“该人突然身体不适”的简单描述,他们希望能够公布执法纪录仪视频,尽快还原真相。
由雷洋的同学发布的一份情况说明称,5月7日,由于雷洋夫妇刚得一女,其亲属欲来京探望,航班预计当晚23点30分到达。当晚21时左右,雷洋从家里出门去首都机场迎接亲属,之后雷洋失联。(来源:央视、新京报)
"""
handler.main(content)
三、基于shifterator进行文本之间词语差异性计算
Shifterator是一个Python软件包,用于通过词移将文本之间的配对比较可视化,这是一种提取哪些词对两个文本之间的差异有贡献的一般方法,通过词移图可视化,详细的、可解释的水平条形图显示了词移的相互作用成分,可用于直接的文本比较、情感分析等场景。
项目地址: https://shifterator.readthedocs.io/en/latest/
1、基本概述
具体的,该工具将文本作为数据来处理,并映射出两个文本如何相似或不同的复杂问题,涵盖了常见的文本比较措施,包括相对频率、Shannon熵、Tsallis熵、Kullback-Leibler分歧和Jensen-Shannon分歧。

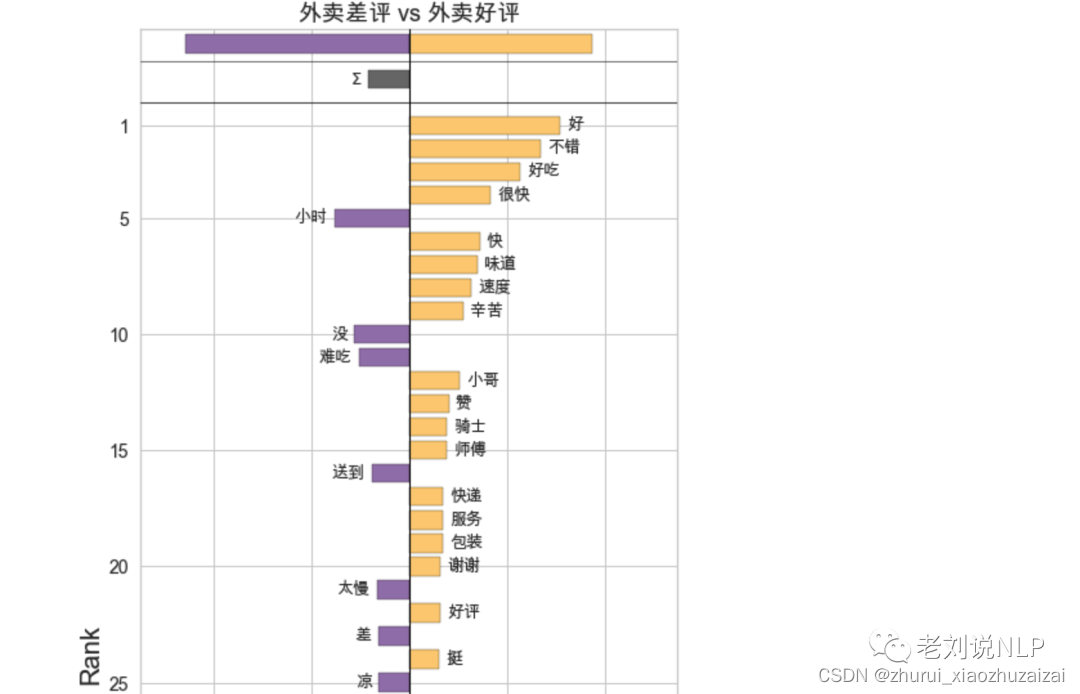
例如,上图显示了美国总统林登以及布什的总统演说情感词移动图,左边显示的是基本的词移图,使用的是labMT情感词典(每个词一个分数),右边是通用的词移图,使用的是SocialSent十年适应性情感词典(每个十年每个词一个分数)。
其中,词移显示了对情感差异贡献最大的50个词。从中可以看到,左边的词是那些导致布什的演讲比约翰逊的演讲更消极的词,右边为积极的词,顶端的条形图显示了总体情绪差异和每种类型的词语对该差异的影响。
2、实践案例
一般而言,给定关于外卖评论的数据,即0/1标签的评论数据,0表示差评、1表示好评,如何挖掘决定两个评价的不同词语分布,我们能够直接想到的就是词云对比,分别分词、去除停用词后进行比对。但Shifterator给了我们另一个视角。
1)给定数据
label,review
0,差评,11点14订餐,13点20饭才到,2个小时才把我的午饭送到,而且还是打了2次客服电话,1次投诉电话才给送来,要是不打电话都不知道几点能吃上午饭?
0,我让多加汁也没加,怎么吃啊?干了吧唧的
0,慢,多远的距离,那么长时间
0,盒子很精致,味道还好。整体不错
0,餐呢?就为了不半价,餐没送来就确认了?必须投诉
0,不管口味如何,送了两个多小时,不骂街我已经是素质好了
0,总是很晚送到
0,"不好吃,饭根本不像饭,难吃的咽不下去"
0,除了速度慢,其他都挺好。速度忒慢了,等了一个小时二十分钟。
1,南瓜粥一般般,卷饼不错
1,味道不错,送餐时间一个多小时
1,天天吃,会不会长胖
1,很好,也很快不错
1,"虽然送餐时间稍晚,但是味道好吃,没得说,态度也很好"
1,速度好快!
1,很准时,而且这次包装很认真,用券太划算了!
1,味道不错,就是量不大
1,肘子挺好吃~
1,经济实惠,又好吃,打包的还好
2)实现代码
import pandas as pd
import collections
import jieba
import re
from shifterator import EntropyShift
import matplotlib
reviews_df = pd.read_csv("data/WaiMai8k.csv", encoding='utf-8')
reviews_df.head()
texts_neg = reviews_df[reviews_df['label']==0]['review'].tolist()
texts_pos = reviews_df[reviews_df['label']==1]['review'].tolist()
def clean_text(docs):
stop_words = open('data/stopwords.txt', encoding='utf-8').read().split('\n')
text = "".join(docs)
text = "".join(re.findall("[\u4e00-\u9fa5]+", text))
words = jieba.lcut(text)
words = [w for w in words if w not in stop_words]
wordfreq_dict = collections.Counter(words)
return wordfreq_dict
clean_texts_neg = clean_text(texts_neg)
clean_texts_pos = clean_text(texts_pos)
matplotlib.rc("font", family='Arial Unicode MS')
entropy_shift = EntropyShift(type2freq_1=clean_texts_neg,
type2freq_2=clean_texts_pos,
base=2)
entropy_shift.get_shift_graph(title='外卖差评 vs 外卖好评')
从中可以看到:最能决定外卖差评的用语是配送时间,其次才是口味,最能决定外卖好评的似乎是口味,其次才是配送时间。
地址:
https://github.com/ryanjgallagher/shifterator
四、基于Matplotlib-barchart-race进行数据动态可视化
1、基本概述
Matplotlib是一个非常强大的Python画图工具,可以使用该工具将很多数据通过图表的形式更直观的呈现出来,支持绘制线图、散点图、等高线图、条形图、柱状图、3D 图形、甚至是图形动画等等。
于此对应的,Pyplot是Matplotlib的子库,提供了和MATLAB 类似的绘图API,包含一系列绘图函数的相关函数,每个函数会对当前的图像进行一些修改,如给图像加上标记,生新的图像,在图像中产生新的绘图区域等等。
项目地址:https://matplotlib.org/stable/gallery/index.html
其中,对于一个具有时许特征的数据来说,如何获取动态数据演化图是我们场景的一个使用场景,例如观察不同国家在过去几十年来的机场吞吐量对比、不同影视明星的排名对比,不同国家的进出口/GDP等数据等对比等。
2、实践案例
pratapvardhan提供了一个简易实现的案例,假设我们有一以下数据,包括了不同年度、不同国家的人口数量,如何使用matplotlib完成绘制。
1)给定数据
matplotlie提供了简易的实现方式,通过使用其中的animatation来实现动图的制作。
实现代码
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import matplotlib.animation as animation
from IPython.display import HTML
url = 'https://gist.githubusercontent.com/johnburnmurdoch/4199dbe55095c3e13de8d5b2e5e5307a/raw/fa018b25c24b7b5f47fd0568937ff6c04e384786/city_populations'
df = pd.read_csv(url, usecols=['name', 'group', 'year', 'value'])
df.head(3)
colors = dict(zip(
["India", "Europe", "Asia", "Latin America", "Middle East", "North America", "Africa"],
["#adb0ff", "#ffb3ff", "#90d595", "#e48381", "#aafbff", "#f7bb5f", "#eafb50"]
))
group_lk = df.set_index('name')['group'].to_dict()
"""Run below cell `draw_barchart(2018)` draws barchart for `year=2018`"""
fig, ax = plt.subplots(figsize=(15, 8))
def draw_barchart(current_year):
dff = df[df['year'].eq(current_year)].sort_values(by='value', ascending=True).tail(10)
ax.clear()
ax.barh(dff['name'], dff['value'], color=[colors[group_lk[x]] for x in dff['name']])
dx = dff['value'].max() / 200
for i, (value, name) in enumerate(zip(dff['value'], dff['name'])):
ax.text(value-dx, i, name, size=14, weight=600, ha='right', va='bottom')
ax.text(value-dx, i-.25, group_lk[name], size=10, color='#444444', ha='right', va='baseline')
ax.text(value+dx, i, f'{value:,.0f}', size=14, ha='left', va='center')
ax.text(1, 0.4, current_year, transform=ax.transAxes, color='#777777', size=46, ha='right', weight=800)
ax.text(0, 1.06, 'Population (thousands)', transform=ax.transAxes, size=12, color='#777777')
ax.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
ax.xaxis.set_ticks_position('top')
ax.tick_params(axis='x', colors='#777777', labelsize=12)
ax.set_yticks([])
ax.margins(0, 0.01)
ax.grid(which='major', axis='x', linestyle='-')
ax.set_axisbelow(True)
ax.text(0, 1.15, 'The most populous cities in the world from 1500 to 2018',
transform=ax.transAxes, size=24, weight=600, ha='left', va='top')
ax.text(1, 0, 'by @pratapvardhan; credit @jburnmurdoch', transform=ax.transAxes, color='#777777', ha='right',
bbox=dict(facecolor='white', alpha=0.8, edgecolor='white'))
plt.box(False)
draw_barchart(2018)
fig, ax = plt.subplots(figsize=(15, 8))
animator = animation.FuncAnimation(fig, draw_barchart, frames=range(1900, 2019))
HTML(animator.to_jshtml())
# or use animator.to_html5_video() or animator.save()
地址:
https://colab.research.google.com/github/pratapvardhan/notebooks/blob/master/barchart-race-matplotlib.ipynb#scrollTo=FwlbfAoVzzXd