PersEmoN: A Deep Network for Joint Analysis of Apparent Personality, Emotion and Their Relationship
公众号:EDPJ
目录
6.3 Apparent Personality和Emotion的关系
1. 摘要
分析表象性格(Apparent Personality)和情绪(Emotion)是情感计算(Affective Computing)的核心。现有的成果是对这两者独立的分析。本文探索能否基于面部图像联合学习这两种高级情感特征及其关系。因此,本文提出了PersEmoN。这是一个端到端(End-to-End)训练的类似Siamese的深度网络。它由两个卷积网络组成:其中一个用于表象性格分析,另一个用于情绪分析。它们共享底层的特征提取模块,并且在多任务学习(Multi-Task Learning)的框架内进行优化。情感和性格网络有各自的注释数据集(annotated dateset)。此外,采用类似对抗(adversarial-like)的损失函数来提升异构数据集(heterogeneous dataset)之间的表示相干(representation coherence)。基于此,本文还探讨了情绪与表象性格的关系。
- 表象性格: 一个人的第一印象/表象特征可以用来快速判断其性格特征(Personality Traits)
- 五大性格特征(Big Five Personality Traits,人格心理学,List of Personality Traits)
- 许多这方面的研究表明,不论是用英语词汇还是用中文词汇,不论是让被试对自己还是对他人描述,不论采用什么因素抽取和旋转法,结果都是得到了五个主要因素,它们是:
- Extraversion:外向、有活力、热情;
- Agreeableness:愉快、利他、有感染力;
- Conscientionusness:公正、拘谨、克制;
- Neuroticism:神经质、消极情绪、神经过敏;
- Openness to experience:直率、创造性、思路开阔。
- 这五个因素的字母缩写为OCEAN,意味着“大五”系统的广泛代表性。
- 情感计算: 研究和开发能够识别、解释、处理和模拟人类影响的系统和设备。
- Siamese Network(参考1,参考2): 主要特点
- Siamese 网络采用两个不同的输入,通过两个具有相同架构、参数和权重的相似子网络。
- 这两个子网互为镜像,就像连体双胞胎一样。 因此,对任何子网架构、参数或权重的任何更改也适用于其他子网。
- 两个子网络输出一个编码来计算两个输入之间的差异。
- Siamese 网络的目标是使用相似度分数对两个输入是相同还是不同进行分类。可以使用二元交叉熵、对比函数或三元组损失来计算相似度分数,这些都是用于一般距离度量学习方法的技术。
- Siamese 网络是一种one-shot分类器,它使用判别特征从未知分布中概括不熟悉的类别。
- 异构数据: 类型和格式差异很大的数据。本文的异构数据:在不同的环境中收集。环境的亮度、人物的姿态等都有很大的不同。每个数据集可能会有差异巨大的统计分布。
2. 关键词
情感计算(Affective Computing),情绪(Emotion),表象性格(Apparent Personality),对抗学习(Adversarial Learning),多任务学习(Multi-Task Learning),深度学习(Deep Learning)
3. 面临的问题
- 包含用于学习apparent personality、emotion及其关系丰富表示的,有标注的emotion和apparent personality的大规模数据集是稀缺的。特别是,现有数据集仅包含emotion属性,而其他数据集可能仅对apparent personality进行注释。手动注释emotion和apparent personality的数据可能会部分缓解这种情况。然而,它成本高昂、耗时,而且由于主观性容易出错。
- 现有数据集的差异:数据集通常是在不同的环境中收集的,这些环境可能会在照明、比例、姿势等方面表现出显著变化。每个数据集可能具有截然不同的统计分布。
- Emotion和apparent personality的注释可以在图像、帧级别或视频级别完成。如何将帧级和视频级理解封装到单个网络中?
4. PersEmoN网络结构

- 首先用开源的多任务卷积神经网络(Multi-task Convolutional Neural Network,MTCNN)对apparent personality和emotion数据集中的face进行识别和调整。
- 对于apparent personality数据集,使用稀疏采样(Sparse Sampling)。
- Apparent personality network包含一个特征提取模块(Feature Extraction Module, FEM)和一个用于预测图片属于五大性格特征中哪一种的性格分析模块(Personality Analysis Module, PAM)。把apparent personality scores喂给PAM之前,用一个共识聚合函数(consensus aggregation function)来聚合这个分数。
- Emotion network与apparent personality network共享FEM,且它有各自的emotion分析模块(Emotion Aalysis Module,EAM),该模块用于预测emotion的激起值(Arousal)和唤醒值(valence)。
- 最后,有一个分析emotion和apparent personality关系的模块(Realtionship Analysis Moudel,RAM)。
Arousal代表唤起程度的高低,valence代表积极情绪的高低, 这两个维度都是通过数值来代表他的高低程度。比如一个数值区间[-1,1], -1代表非常低迷/消极,1代表非常激动/积极。 这样,开心(happiness)就可以用 高arousal 和 高 valence来表示,而抑郁(depression) 则可以用 低arousal和低valence 来表示。几乎人类所有的情绪都可以用这两个维度所构成的二维空间来表示。(参考)
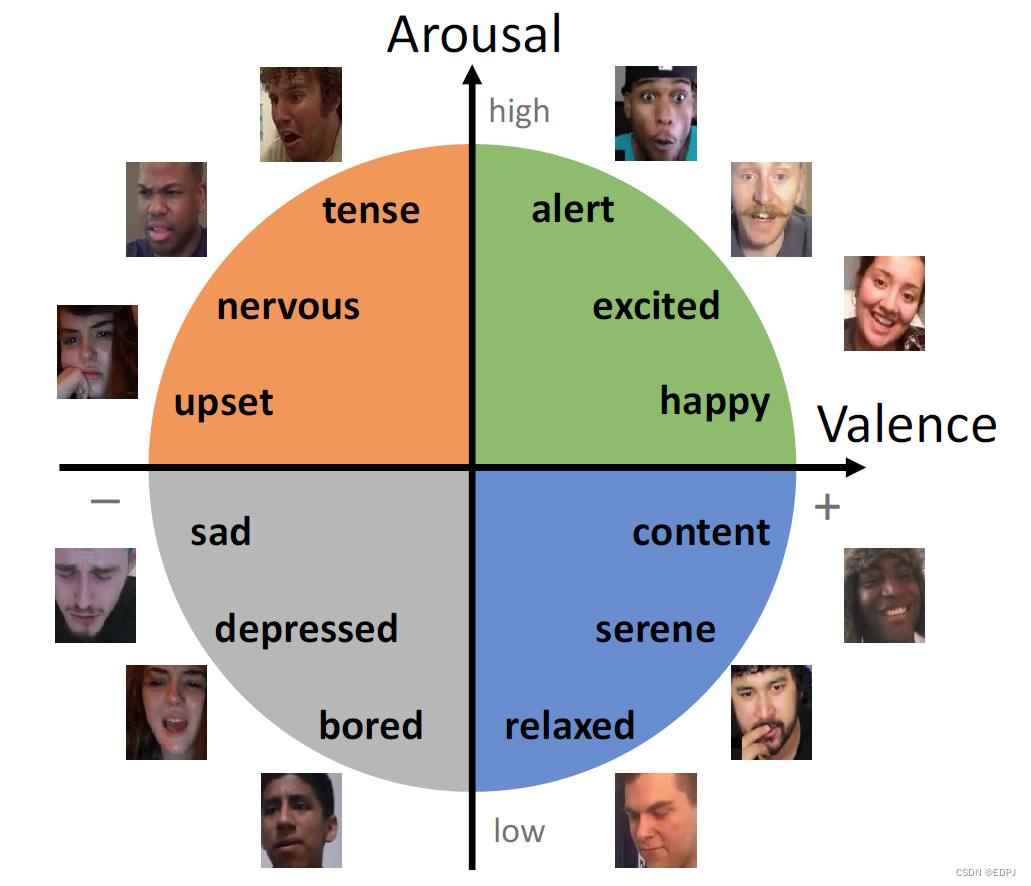
- 在训练阶段,系统会识别图像源于哪个数据集,并自动将其分配至相应分支。
- 在测试阶段,系统会通过PAM和EAM分别估计apparent personality和emotion。
- 在推断阶段,基于PAM和EAM获得apparent personality traits。
- 作为副产品,可以用RAM从emotion(激起值和唤醒值)获得apparent personality traits。
- 值得注意的是,在测试阶段,通过独立处理每一个video frame,本方法也适用于基于video的emotion dataset。
- 不同模块的详细结构如下图所示。Conv是可能包含多个卷积层的卷积单元。方括号中的是residual单元。例如,
表示4个级联的卷积层,每一层有64个大小为
的滤波器。S2表示Stride是2。FC表示全连接层,对应的是输出神经元的的数目。

5. Loss Function
5.1 Personality Loss
V和Y分别表示输入视频及其真实标签(ground truth label)。给定第 i 个视频,其中
表示apparent personality视频的索引集合,P表示数据源于apparent personality数据集。把这第 i 个视频等间隔分成K个片段
,则可得如下模型
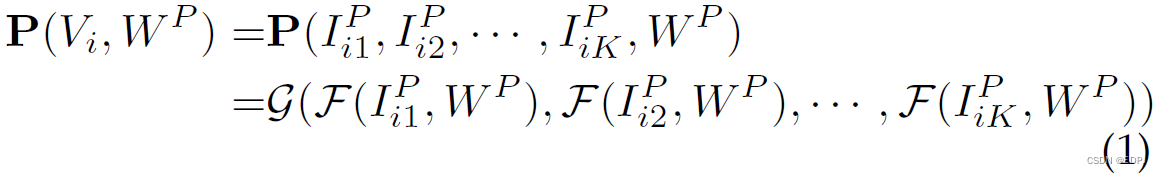
其中,是face frame,从片段
中随机采样获得一个frame
。函数
表示参数为
的personality network,它基于face
得到初步的apparent personality scores。片段共识函数G融合初步分数获得最终的apparent personality scores。用smooth
loss function优化personality network。
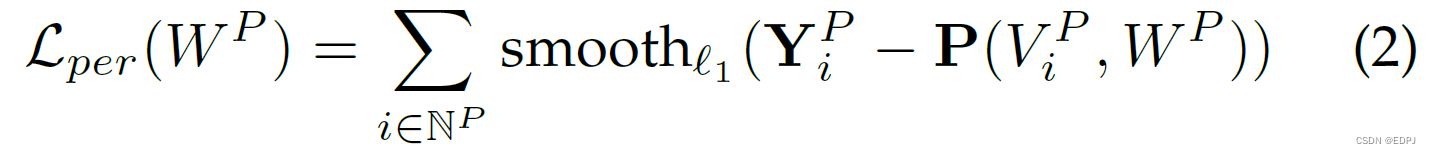
Smooth function表示如下:
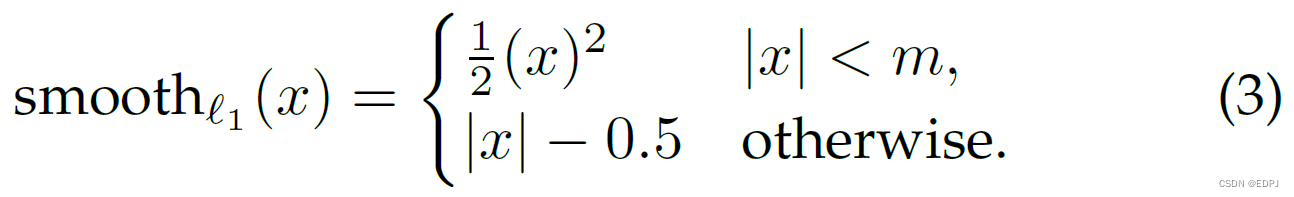
5.2 Emotion Loss
给定face image ,emotion network生成emotion scores:
![]()
Emotion network的loss function表示如下:
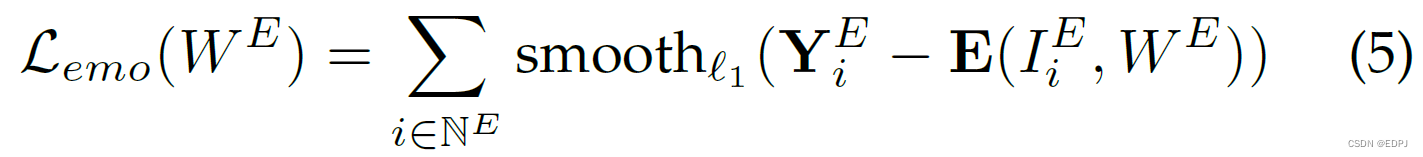
5.3 Dataset Classifier Loss
作者训练了一个参数为的dataset classifier,表示为D,用于区分数据源于哪个数据集。对于每一个源于FEM的feature representation,用如下的softmax loss来训练dataset classifier。对于personality dataset,
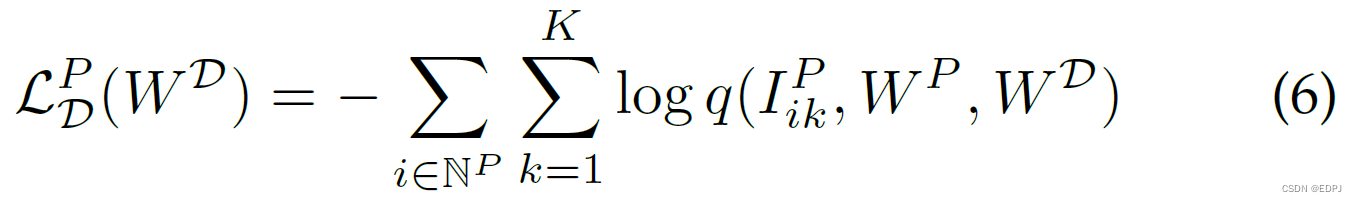
其中,。类似的,对于emotion dataset,
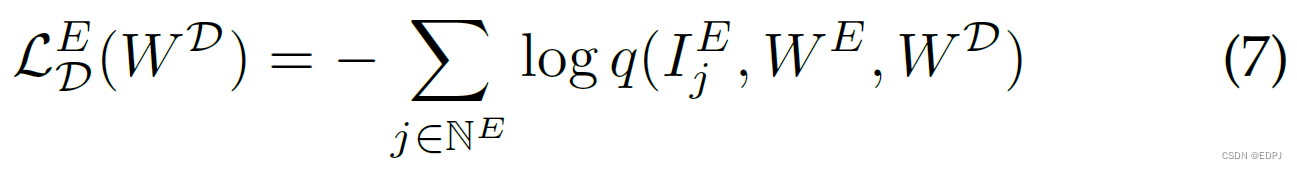
总损失表示为:
![]()
5.4 Adversarial Loss
FEM中引入了类似对抗的学习目标。通过计算预测的数据集标签与数据集标签上的均匀分布间的cross entropy,来最大化模糊两数据集的差异。
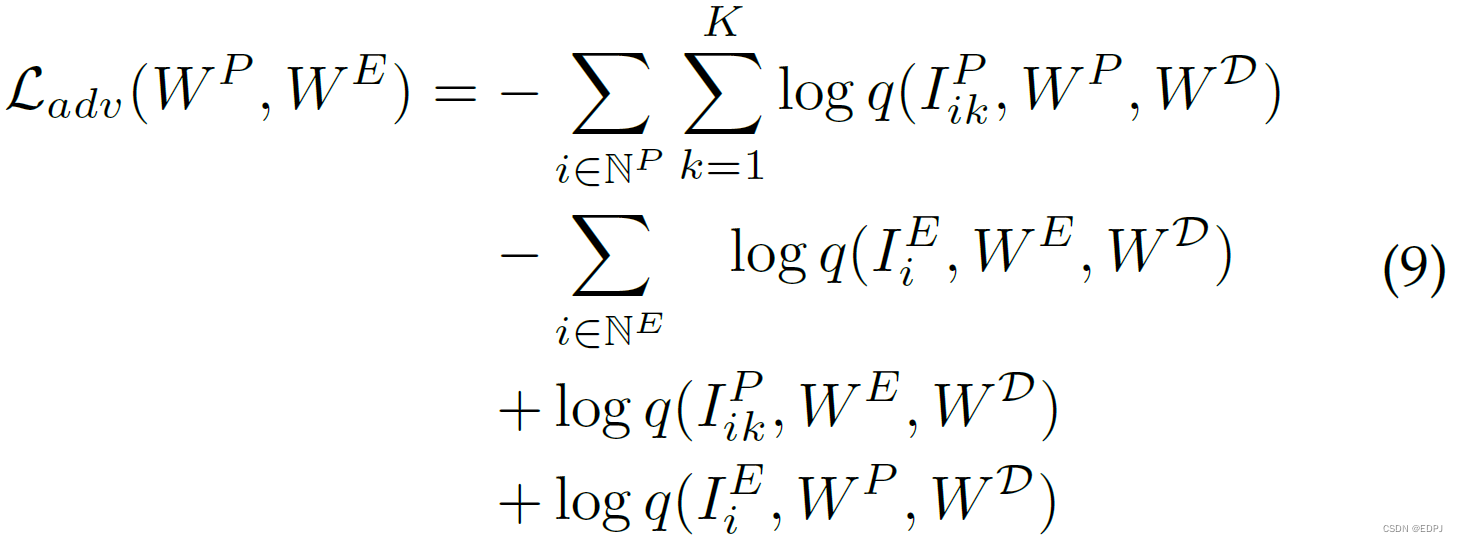
5.4 Relationship Loss
为探索apparent personality是否可以直接从emotion attributes推断获得,论文引入了RAM。它接收源于EAM的emotion scores,从而预测apparent personality scores。RAM的输入可以表示为:

是face frame,从片段
中随机采样获得一个frame
。
表示参数为
的emotion network:基于face frame
获得emotion scores的初步预测。RAM基于视频
给出apparent personality scores:
![]()
表示RAM的参数。RAM经由优化如下目标函数获得:
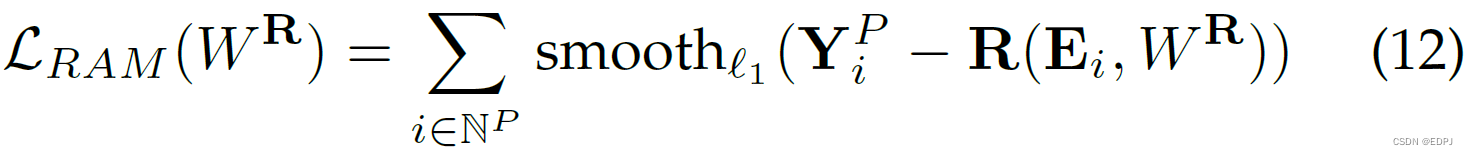
5.5 Overall Loss Functions
PersEmoN的每一个模块都是可微的,整个系统可以用端到端的的方式优化:最小化如下loss function

由于系统主要目标是估计emotion和apparent personality traits,即和
是主要的目标函数,因此他们的权重被设为
。其它loss function的作用是regularization,所以它们的权重相对较小,设为
。 Smooth
function(等式3)的参数m=0.05。
6. Experiments
为评估emotion预测的质量,计算了emotion的预测值和真实值的均方误差(mean square error,MSE)。本文用了两个度量:平均精度(mean accuracy)A和判定系数(coefficient of determination)。
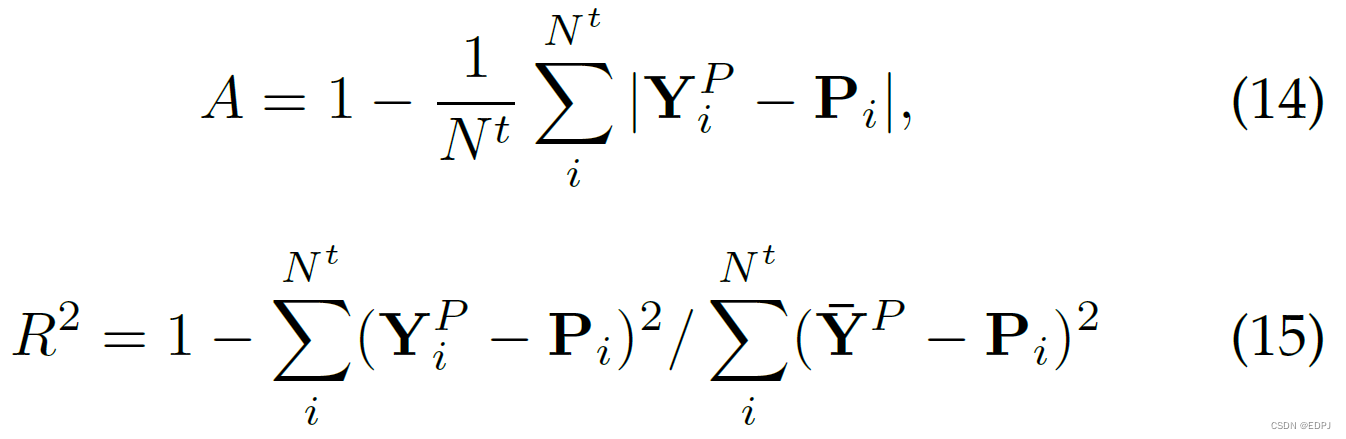
其中,表示testing samples的总数目,
表示真实值,
表示预测值,
表示真实值的均值。
根据判定系数的百科
- 总平方和是真实值与真实值的均值之间的MSE,
- 回归平方和是预测值与真实值均值之间的MSE,
- 残差平方和是预测值与真实值之间的MSE。
本文使用的判定系数
:1 - 残差平方和/回归平方和。在我看来,应该使用(1 - 残差平方和/总平方和)更为准确。
残差平方和越小,即判定系数越大时,预测性能越好。
6.1 Emotion的评估
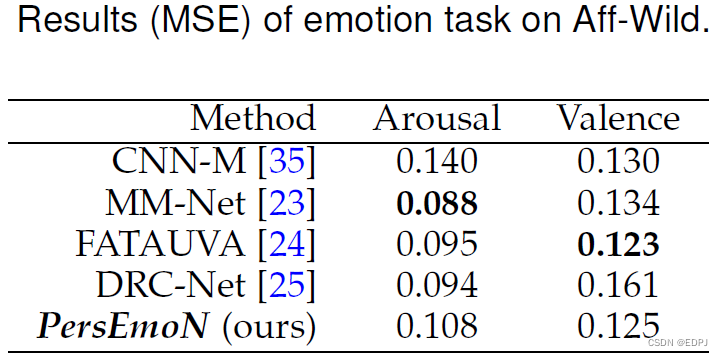
数据表明,尽管PersEmoN不像其他模型一样专为Emotion识别设计,但在激起值(Arousal)和唤醒值(valence)两个维度上的预测,PersEmoN仍有略微优势的性能。
6.2 Apparent Personality的评估
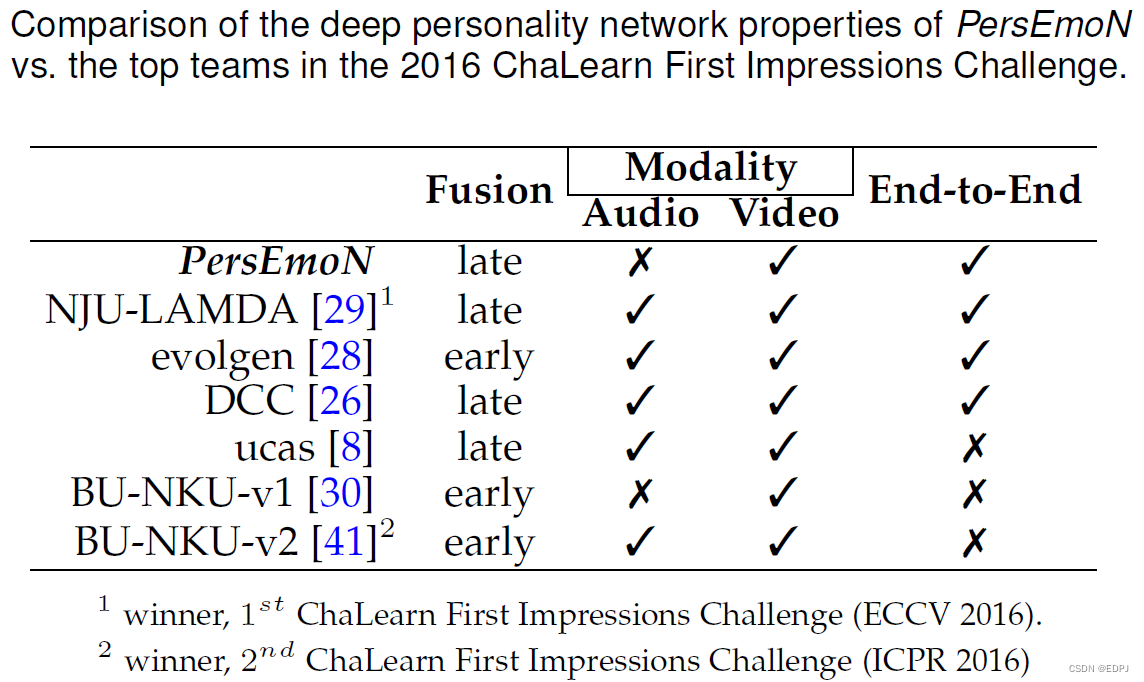
PersEmoN是端到端的模型,且仅使用视频信息进行推断。
特征融合(Fusion)
- 在深度学习的很多工作中(例如目标检测、图像分割),融合不同尺度的特征是提高性能的一个重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。如何将两者高效融合,取其长处,弃之糟泊,是改善分割模型的关键。
- 很多工作通过融合多层来提升检测和分割的性能,按照融合与预测的先后顺序,分类为早融合(Early fusion)和晚融合(Late fusion)。
- 早融合(Early fusion): 先融合多层的特征,然后在融合后的特征上训练预测器(只在完全融合之后,才统一进行检测)。这类方法也被称为skip connection,即采用concat、add操作。这一思路的代表是Inside-Outside Net(ION)和HyperNet。两个经典的特征融合方法:
- concat:系列特征融合,直接将两个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q;
- add:并行策略,将这两个特征向量组合成复向量,对于输入特征x和y,z = x + iy,其中i是虚数单位。
- 晚融合(Late fusion):通过结合不同层的检测结果改进检测性能(尚未完成最终的融合之前,在部分融合的层上就开始进行检测,会有多层的检测,最终将多个检测结果进行融合)。这一类研究思路的代表有两种:
- feature不融合,多尺度的feture分别进行预测,然后对预测结果进行融合,如Single Shot MultiBox Detector (SSD) , Multi-scale CNN(MS-CNN)
- feature进行金字塔融合,融合后进行预测,如Feature Pyramid Network(FPN)等。
下表为使用平均准确度 A 和判定系数的apparent personality预测Benchmark,BU-NKU-v2 的
值未公布。
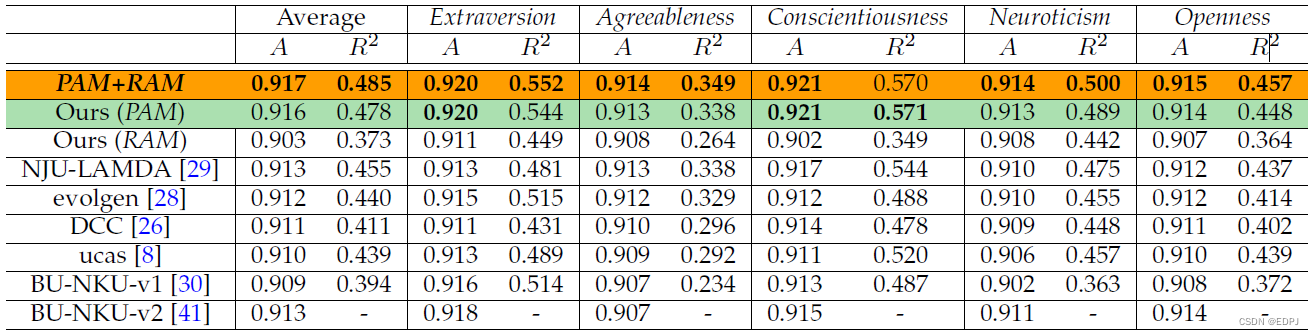
数据表明,即使仅使用视频信息进行预测,PersEmoN仍表现出突出的性能。
6.3 Apparent Personality和Emotion的关系
上图的PAM+RAM,仅用二维的激起值-唤醒值(Arousal-valence),就实现对apparent personality的良好预测。
下图表示不同apparent personality traits和emotion(arousal-valence)space的关系。
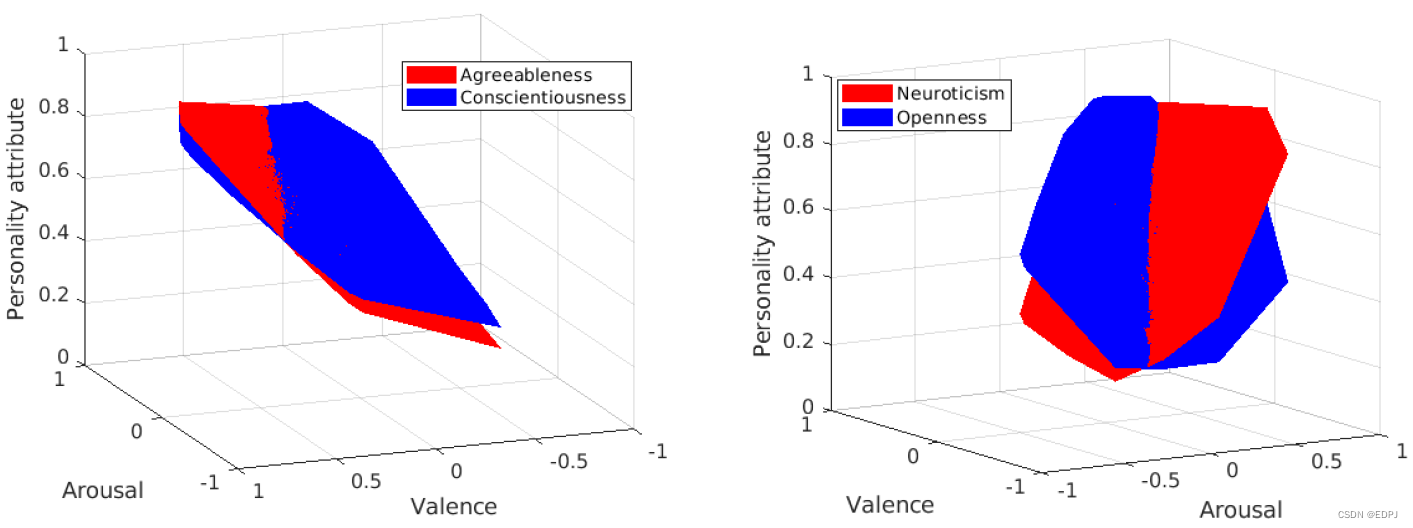
实验结果表明,Agreeableness(愉快、利他、有感染力)和Conscientionusness(公正、拘谨、克制)更为相似;Neuroticism(神经质、消极情绪、神经过敏)和Openness(直率、创造性、思路开阔)差异较大;而未在图中显示的Extraversion(外向、有活力、热情)与Agreeableness更为相似。
6.4 Joint Training的有效性
本文提出multi-task learning新方法的目的是获得可泛化的representation。它不止适用于目标问题,还适用于十分普遍的问题。在PersEmoN中,由于所有task共享FEM,附加的task就像是regalarization,迫使系统在相关任务上表现更好。
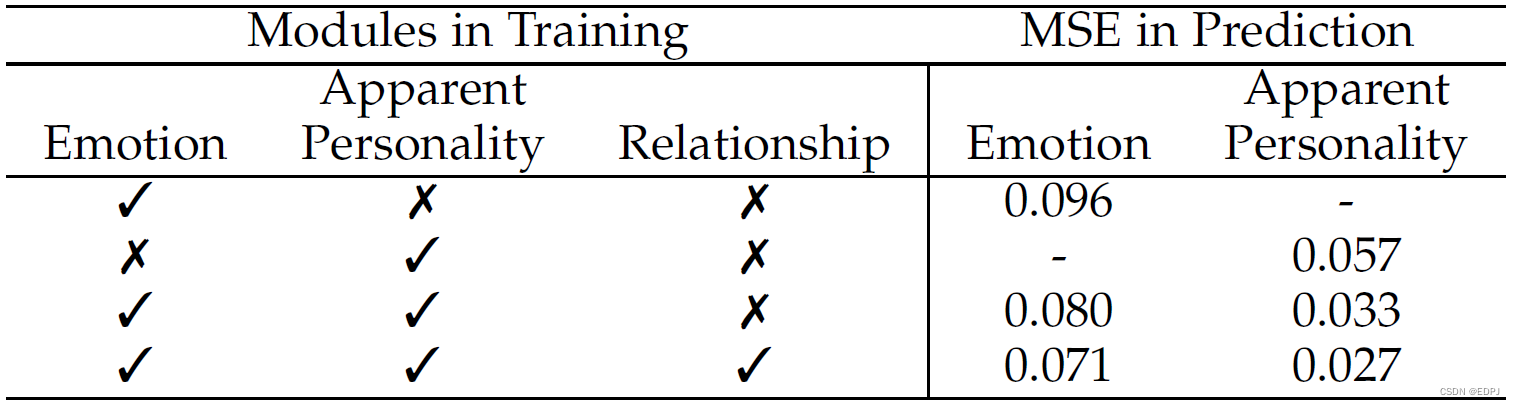
各个模块的加入使性能不断提升。作者认为这些提升源于CNN的BP算法,其中,FEM共享的参数直接影响了整个系统的泛化性能。
6.5 相干策略(Coherence Strategy)

对于不同的dataset,具有良好可迁移性的representation应该是不变的。为此,作者进行了移除PersEmoN中coherence策略的实验。结果表明,coherence策略可提升性能,即需要获得相干的representation。
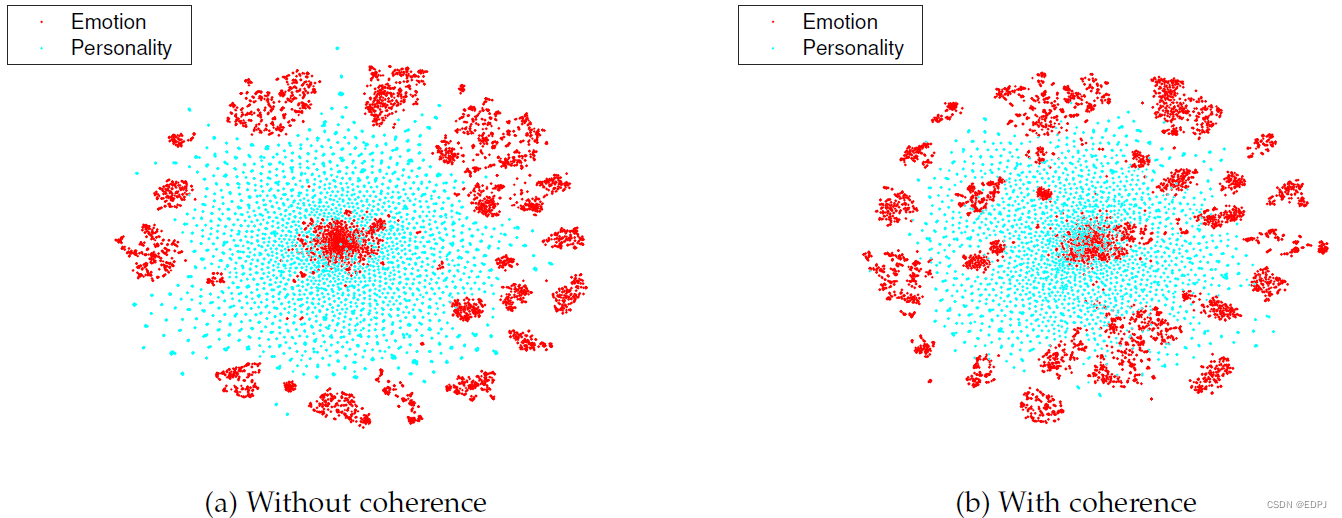
对于apparent ersonality和emotion的数据集,作者用t-SNE把经由FEM获得的512维feature投影到2维空间并进行视觉化。使用相干策略,emotion的大量特征分散到环内,使两个分布相似,重叠明显更大。
7. 参考
Zhang L, Peng S, Winkler S. PersEmoN: a deep network for joint analysis of apparent personality, emotion and their relationship[J]. IEEE Transactions on Affective Computing, 2019. 下载地址:https://arxiv.org/pdf/1811.08657.pdf