0 需求描述
文章被引用关系数据表如下:
id |
oid |
1 |
0 |
2 |
0 |
3 |
1 |
4 |
1 |
5 |
2 |
6 |
0 |
7 |
3 |
其中id表示文章id,oid引用的文章,当oid为0时表示当前文章为原创文章,求原创文章被引用的次数。注意本题不能用关联的形式求解
1 需求分析
1.1 数据源准备
with data as(
select 1 as id, 0 as oid
union all
select 2 as id, 0 as oid
union all
select 3 as id, 1 as oid
union all
select 4 as id, 1 as oid
union all
select 5 as id, 2 as oid
union all
select 6 as id, 0 as oid
union all
select 7 as id, 3 as oid
)
select * from data;
1.2 数据分析
题目要求的是原创文章被引用的次数,其中原创文章为oid为0的文章,也就是文章id为【1,2,6】被引用的次数,引用的文章id用oid来描述。一般正常的思路用关联的方式求解,找出非0的oid在oid为0时的id中存在多少个,那么问题就解决了,我们 用 left join形式求解,具体SQL如下:
with data as(
select 1 as id, 0 as oid
union all
select 2 as id, 0 as oid
union all
select 3 as id, 1 as oid
union all
select 4 as id, 1 as oid
union all
select 5 as id, 2 as oid
union all
select 6 as id, 0 as oid
union all
select 7 as id, 3 as oid
)
select t2.id
,count(oid) as cnt
from
(select oid
from data
where oid<>0
) t1
right join
(
select id
from data
where oid=0
) t2
on t1.oid = t2.id
group by t2.id
order by id具体结果如下:
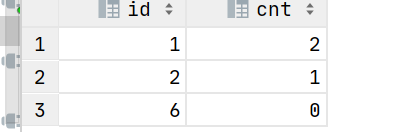
由于题意要求了不能使用join等关联形式求解,通过题意分析此题本质为存在性计数问题,类似于java中我们构建一个HashSet()我们往里面Put数据的时候,每次检查一次是否有该值,有就记为1,最终统计重复的个数有多少个,这类问题也就是我们经常说的容器变换问题,而对应到Hive中时候我们如何构建容器呢?可以通过collect_set()或collect_list()函数来构建,那检查容器中是否存在某个数,我们用array_contains()函数,那么这样一个经典的存在性计数问题就很容易得到解决,具体公式如下。
公式含义:检查当前字段是否在容器中存在,存在计数为1,不存在计数为0,最终求出计数的个数
sum(if(array_contains(array,colum),1,0))我们往往利用该模型解决实际需求中一些问题,如学生退费人数统计问题等。参考文章如下:
(2条消息) SQL之存在性问题分析-HQL面试题39_莫叫石榴姐的博客-CSDN博客
因而,本问题也可以通过构建该模型求解,具体数据变换如下:

第一步:构建原创文章id容器,作为辅助列
with data as(
select 1 as id, 0 as oid
union all
select 2 as id, 0 as oid
union all
select 3 as id, 1 as oid
union all
select 4 as id, 1 as oid
union all
select 5 as id, 2 as oid
union all
select 6 as id, 0 as oid
union all
select 7 as id, 3 as oid
)
select id
, oid
, collect_set(if(oid=0,id,null)) over() as contains
from data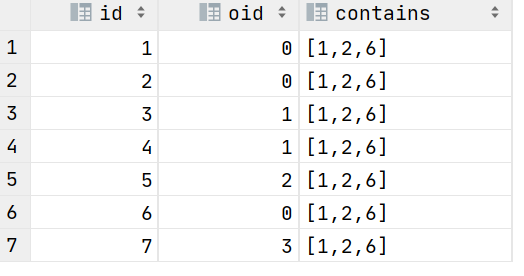
第二步:利用array_contains()函数判断非原创的oid是否在原创文章id容器中,是计数为1,否则计数为0
with data as(
select 1 as id, 0 as oid
union all
select 2 as id, 0 as oid
union all
select 3 as id, 1 as oid
union all
select 4 as id, 1 as oid
union all
select 5 as id, 2 as oid
union all
select 6 as id, 0 as oid
union all
select 7 as id, 3 as oid
)
select id,oid,contains,if(array_contains(contains,oid),1,0) as flag
from
(
select id
, oid
, collect_set(if(oid=0,id,null)) over() as contains
from data
) t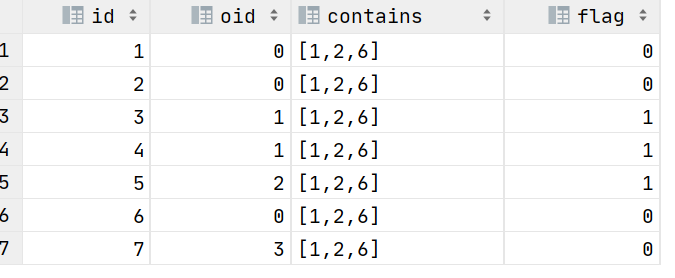
第三步:对原创文章进行汇总求和,得出最终结果
注意:此处需要对原创文章id补充完整,否则会丢记录。补充的方法还是通过array_contains(contains,oid)去判断,如果oid存在于原创文章id中就取该oid,不存在则用原创文章id填充,若该行为非原创记录则记为NULL,最终计算时过滤掉。
with data as(
select 1 as id, 0 as oid
union all
select 2 as id, 0 as oid
union all
select 3 as id, 1 as oid
union all
select 4 as id, 1 as oid
union all
select 5 as id, 2 as oid
union all
select 6 as id, 0 as oid
union all
select 7 as id, 3 as oid
)
select id
,sum(flag) cnt
from
( select if(array_contains(contains,oid),oid,if(oid=0,id,null)) id --清洗数据,补充完整的原创文章id
,if(array_contains(contains,oid),1,0) as flag
from
(
select id
, oid
, collect_set(if(oid=0,id,null)) over() as contains
from data
) t
) t
where id is not null --过滤掉不属于原创文章id的id
group by id
order by id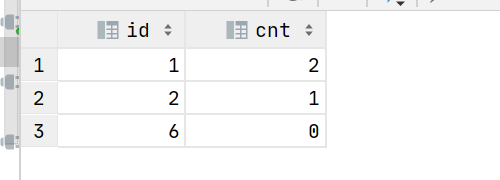
2 小结
本文给出了一种容器变换中存在性计数问题的分析方法,通过 array_contains(array,colum)进行存在性检测,如果存在则记为1,不存在记为0,最终的计算公式如下:
sum(if(array_contains(array,colum),1,0))
通过如上方法可以轻松应对一些判断统计问题。