MySQL (8)
前言 :
知识点回顾 : 上文我们已经了解到了我们的事务 , 知道了事务是将诺干个独立的操作打包成一个整体 , 如 1 + 1 此时想将这个结果写到纸上 ,那么 1 + 1 计算 可以看做一个操作, 将答案 2 写 到纸上 也是一个操作 , 事务就是将这两个操作合并成一个整体, 此时如果我们想要只计算出 1 + 1 = 2 ,不写道纸上,这是不行的 , 必须完成整个过程 算 与 写 这就是事务的原子性 。
另外 : 我们还了解到数据库并发执行会带来 的一些问题 ,如 脏读 , 不可重复读问题 幻读 等问题 。
脏读 :
简单的例子 : 张三 通过update user set math = 100 where name = '李四' ;, 将李四的数学成绩改为了 100 ,
此时李四通过select * from user where name = '李四'获取到了他的成绩 ,发现数学成绩为 100 , 就将整个消息告诉了同学 你看我数学考了一百呢
厉不厉害 , 但是过了一会 张三 发现 看错了 将 10 看成了 100 , 那么 就通过update user set math = 100 where name = '李四'改了 回来, 此时 李四 查询的数据就为脏数据 , 出现这种情况就称为脏读
将 张三 和 李四 就可以看作事务 A 和 B 就能得出结论 : 事务A在对某个数据进行修改的同时,事务B 去 读取了 这个 数据。此时,事务B 读到的很可能是一个“脏数据”(这个数据是一个临时的结果,而不是最终的结果)
不可重复读 : 在同一个事务中,同一个查询在不同的时间得到了不同的结果。例如事务在 T1 读取到了某一行数据,在 T2 时间重新读取这一行时候,这一行的数据已经发生修改,所以再次读取时得到了一个和 T1 查询时不同的结果。
简单来说 张山通过 一个 SQL 如 :select * from user where id = 2去查询数据, 一开始通过sql 拿到了数据 假设数据中有一个字段 为 name , 此时拿到 一个name 为张三, 在此时又有一个人 李四, 通过update user set name = '李四' where id = 2,此时 李四将整个信息改变了, 当 张三 在次通过select * from user where id = 2查询到的信息与之前不一样了
幻读 : 同一个查询在不同时间得到了不同的结果,这就是事务中的幻读问题。例如,一个 SELECT 被执行了两次,但是第二次返回了第一次没有返回的一行,那么这一行就是一个“幻像”行。简单来说 : 张山 通过
select * from user;发现 user 表里面有一条数据, 此时 李四 通过insert into user values()又往 user 表里面插入了一条数据, 此时 张三又 通过select * from user查询会发现多了一条, 那么此时就成为 幻读问题 。
补充 :
这里再补充一下 : 我们的MySQL 中有 4 种事务隔离级别:读未提交(存在脏读/不可重复读/幻读问题)、读已提交(存在不可重复读/幻读问题)、可重复读(存在幻读问题)和序列化,其中可重复读是 MySQL 默认的事务隔离级别。脏读是读到了其他事务未提交的数据,不可重复读是读到了其他事务修改的数据,而幻读则是读取到了其他事务新增或删除的“幻像”行数据
复习完 ,下面就进入到我们的 JDBC 学习 :
JDBC
我们之前再学习MySQL 的时候一直是再黑框框内敲的SQL, 但是再实际开发的时候SQL是很少手动输入的,绝大多数的SQL 都是通过代码自动执行的, 这里就需要通过其他编程语言来操作数据库服务器.
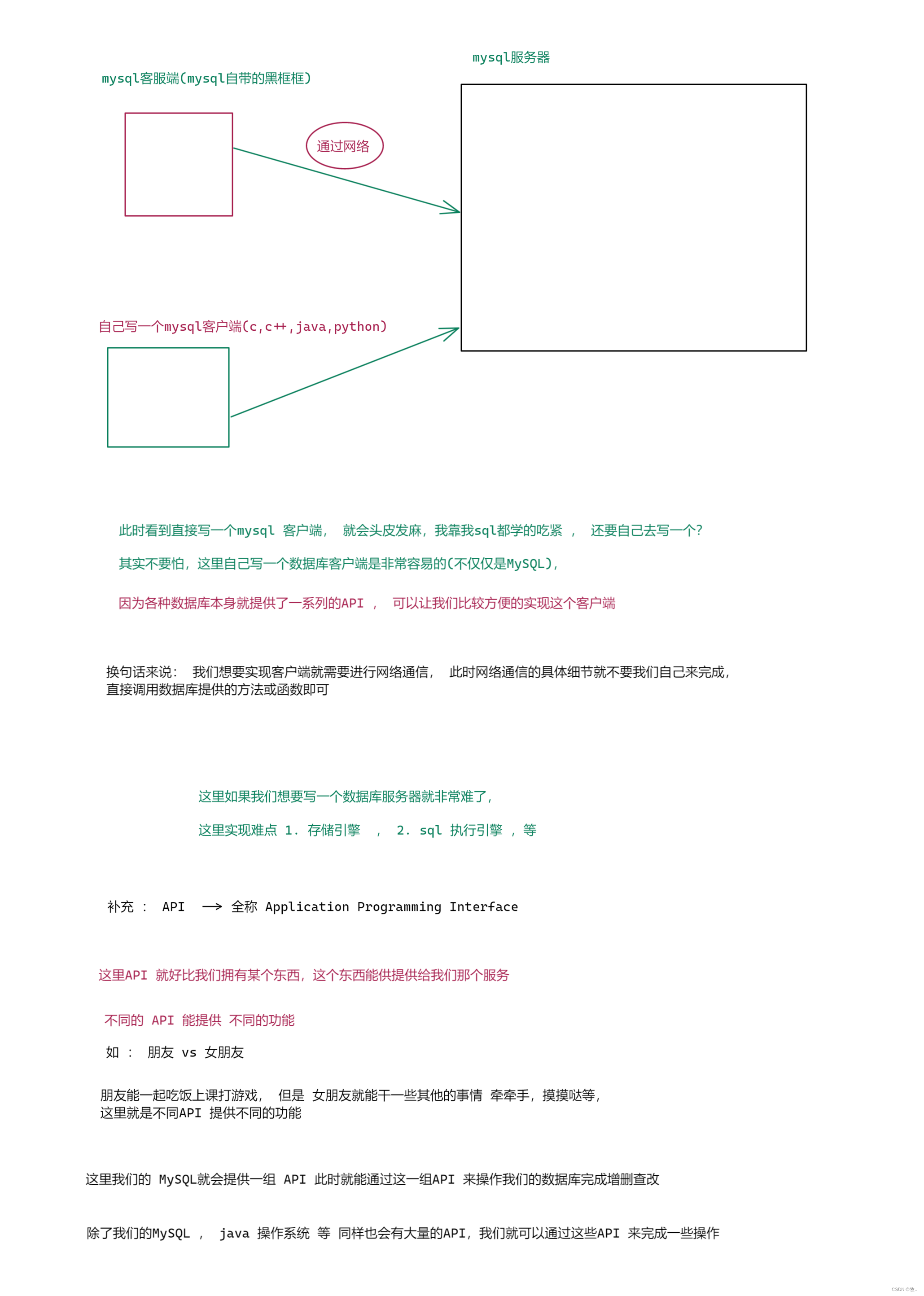
这里我们就可以通过 MySQL 提供的 API 来实现我们的客户端 .
扩展 : MySQL 本来提供的 API 是 C语言, 但考虑到 MySQL 使用的非常广泛, 也就提供了其他语言版本的API , 另外 其他语言的API 本质上还是使用C语言那一套,这里会涉及到跨语言调用的操作.
小问题 :
市面上有很多数据库 如 Oracle , SQLServer ,SQLite等数据 都会提供自己的API, 那么这些API是否相同还是各自拥有一套体系呢?
答案 : 这里是不一样的 , 这里不同的数据库是不同的人开发的, 每个人就会以自己的思路去开发 , 所以说这些API 会一样吗 .
引出 JDBC
小问题看完, 有没有想过 , 这么多数据库 每个都有自己一套的API , 假设我们掌握 了MySQL的 API, 后面到公司发现公司使用的数据库是 Oracle, 那么我们还需要去掌握 Oracle 的API ,如果后面跳槽 公司使用的 又是其他的 数据库, 那么还需要去掌握其他的API,那么是不是就会显的力不从心 ,我靠我咋到哪里都要学呀, 此时我们是不是就渴望能有人能站起来,将这些API 统一成一套,制定成标准 此时我们就学一套即可 .
在我们的java 中就有人站了出来,他就是我们接下来要学习的 JDBC , 为啥是 JDBC呢 因为我们的 JDBC 这一套 API 已经成了java标准库的一部分, 由于java的影响力很大,以自身作为标准, 此时各种数据库厂商,都提供了能供使用 JDBC 相关的驱动包 (驱动包 :相当于 API的具体实现 , JDBC 是约定了API 都有啥,该咋用)
有了JDBC 那么我们就可以只掌握这一套API , 就可以去操作市面上的数据库了(只要他提供给java驱动包) .
知道了由来 这里稍微看看概念 :
JDBC,即Java Database Connectivity,java数据库连接。是一种用于执行SQL语句的Java API,它是Java中的数据库连接规范。这个API由 java.sql.,javax.sql. 包中的一些类和接口组成,它为Java开发人员操作数据库提供了一个标准的API,可以为多种关系数据库提供统一访问。
概念看完下面我们来学习一下JDBC的使用
JDBC的使用
1. 安装对应数据库的驱动包
之前说过 JDBC是将各种数据库的API统一成一个标准,我们只需要掌握JDBC的``API即可,但是有一个前提是需要让JDBC`拥有数据库厂商提供的驱动包, 所以我们想要使用JDBC那么就需要去安装我们数据库对应的驱动包 .

这里我们需要操作MySQL 就需要安装 MySQL的驱动包,在哪里下载呢 ? 我们直接到官网下载即可 。
题外话 : 因为MySQL被 Oracle 收购了,所以我们需要到Oracle的官网进行下载,但是因为Oracle的官网需要注册啥的一堆,这里就不建议去Oracle的官网进行下载 , 这里就可以去我们的中央仓库进行下载. 这里中央仓库就相当于一个应用商店, 里面包含了各个厂商提供的库和组件。
这里提供地址可以保存一下 ,后面会常用 : Maven Repository: Search/Browse/Explore (mvnrepository.com)
点进这个网站 :
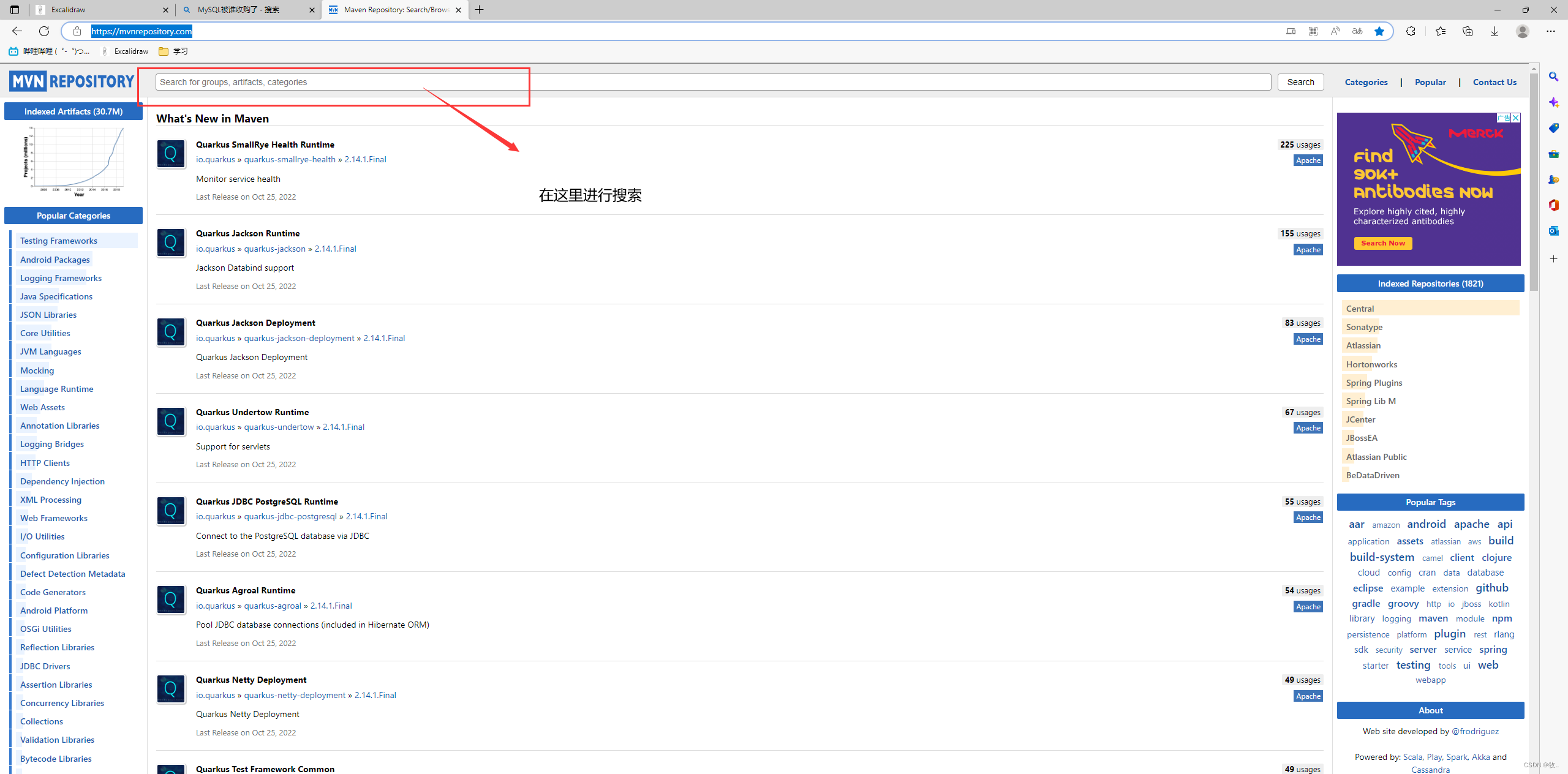
因为我们需要MySQL 的驱动包,这里就直接搜索MySQL即可
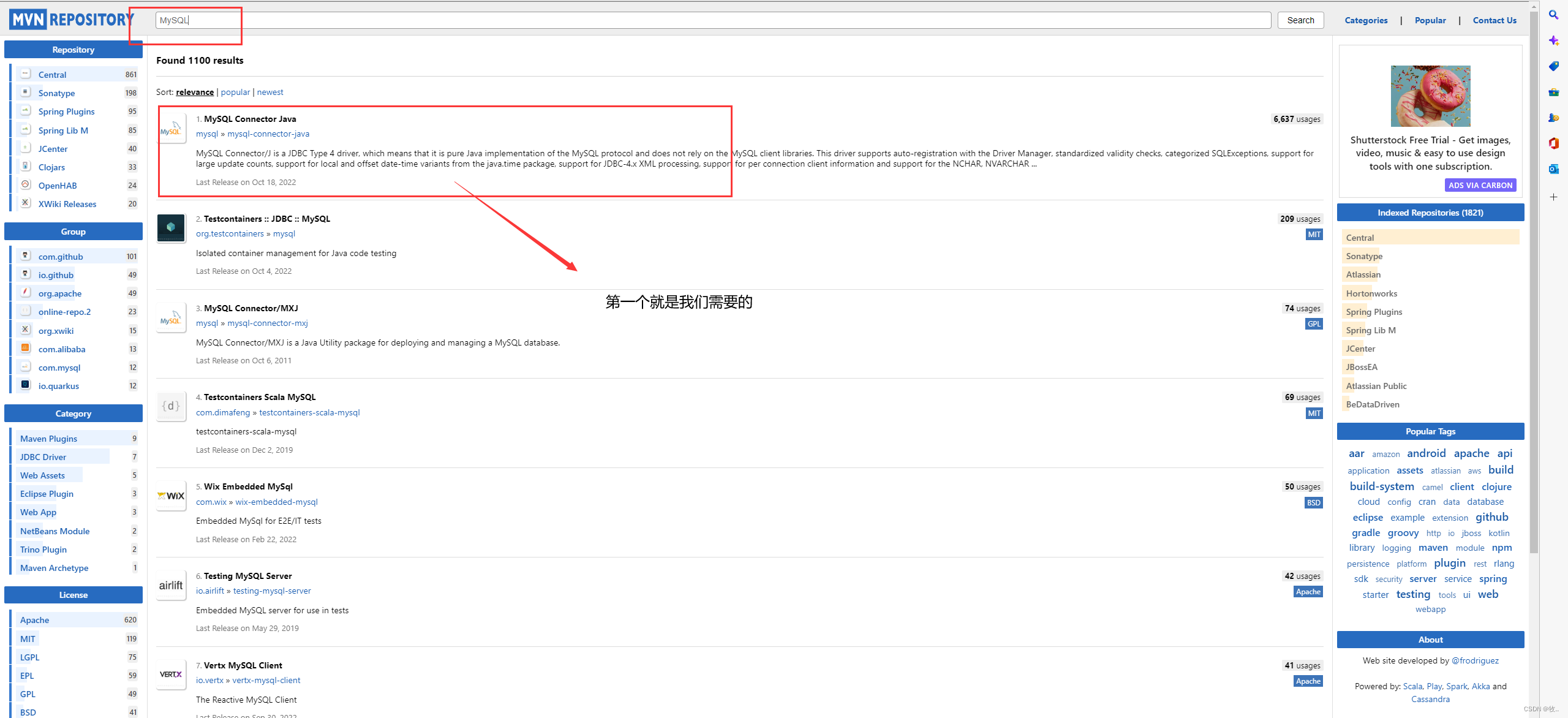
点击第一个 :
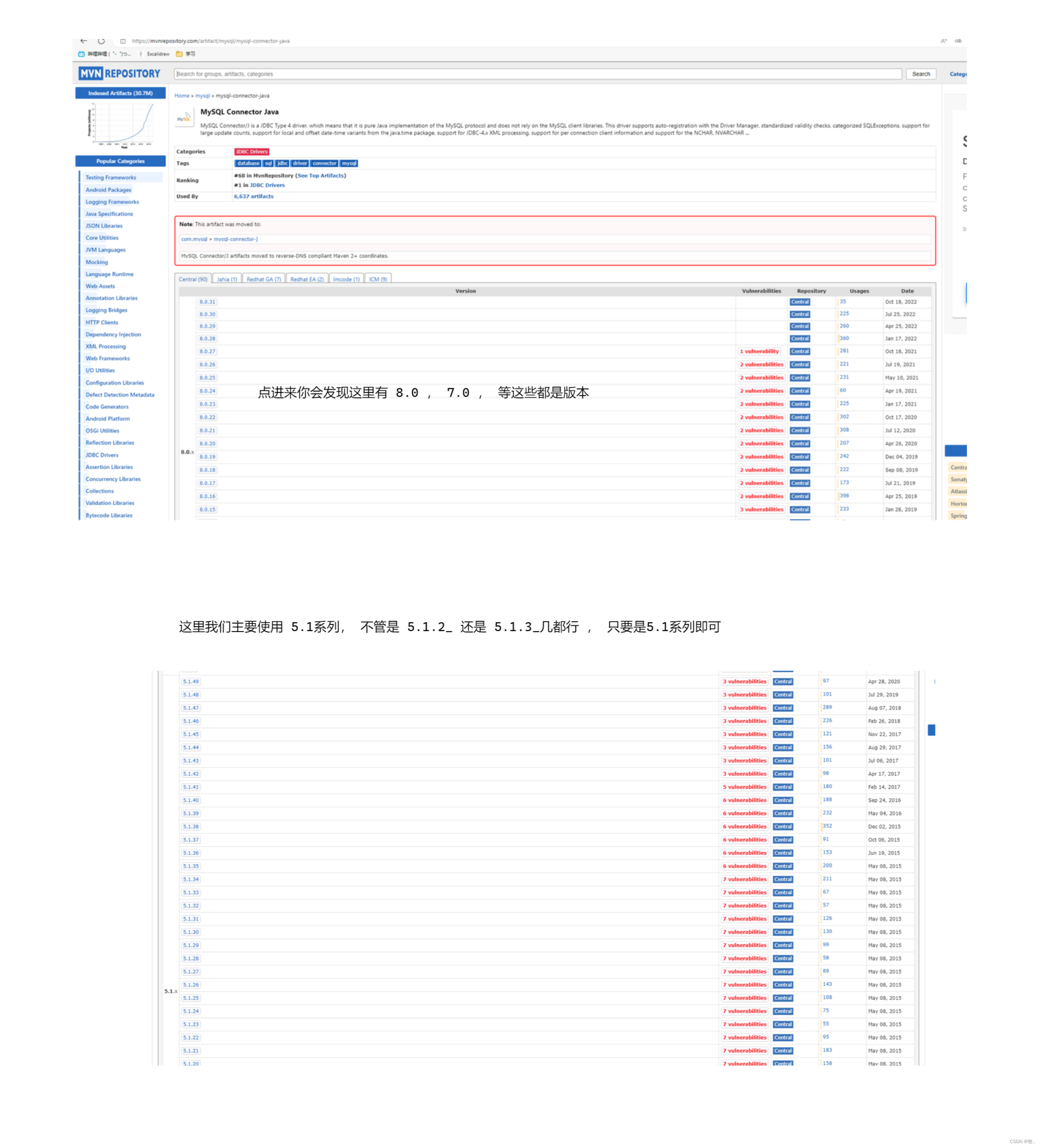
这里我们演示 5.1.49这个版本 :
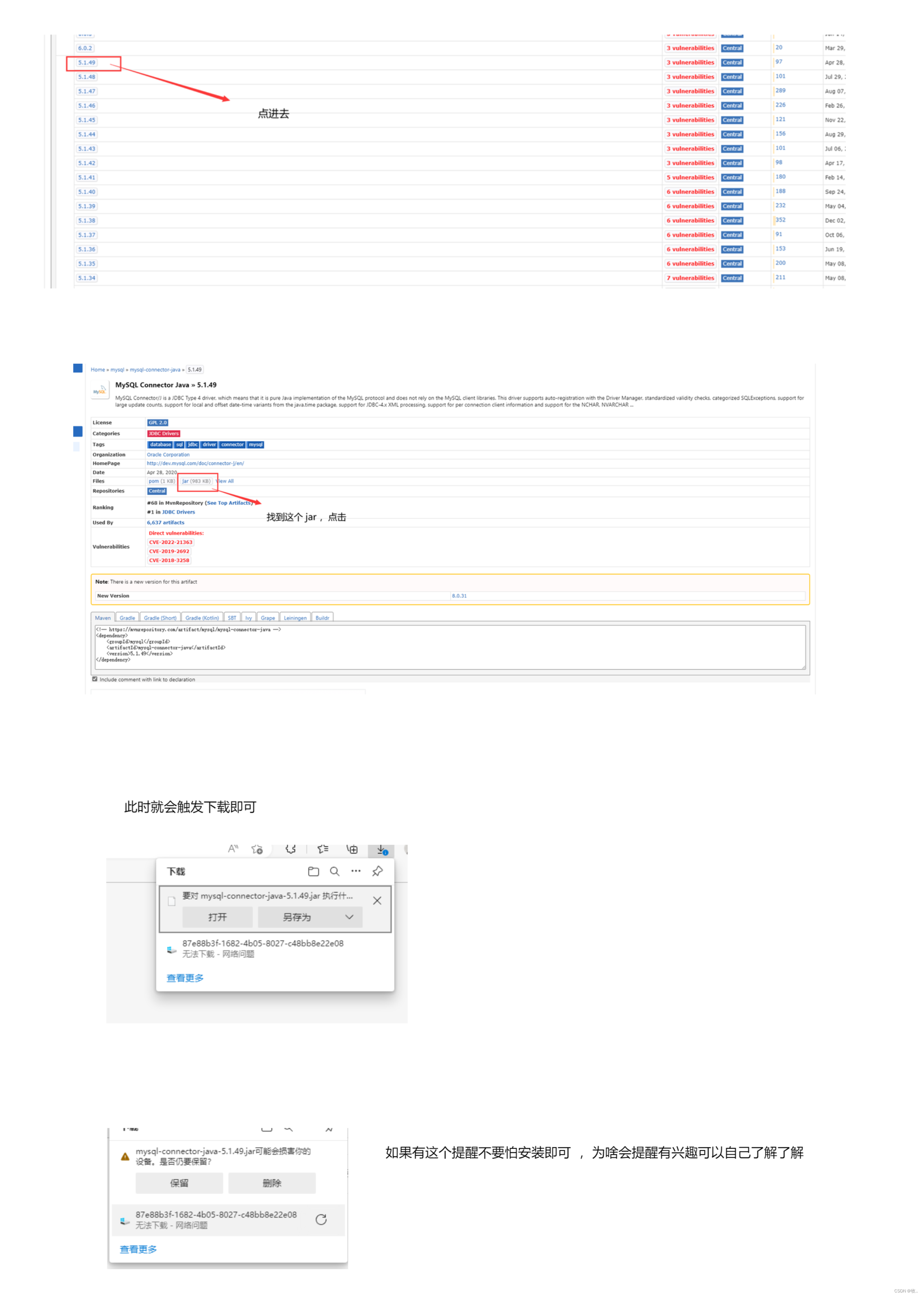
下载完我们的 驱动包, 可以看到 他是一个 .jar 格式的压缩包 他是一个java格式的压缩包 类似于 .rar .zip , 这里我们可以通过解压缩的工具看看
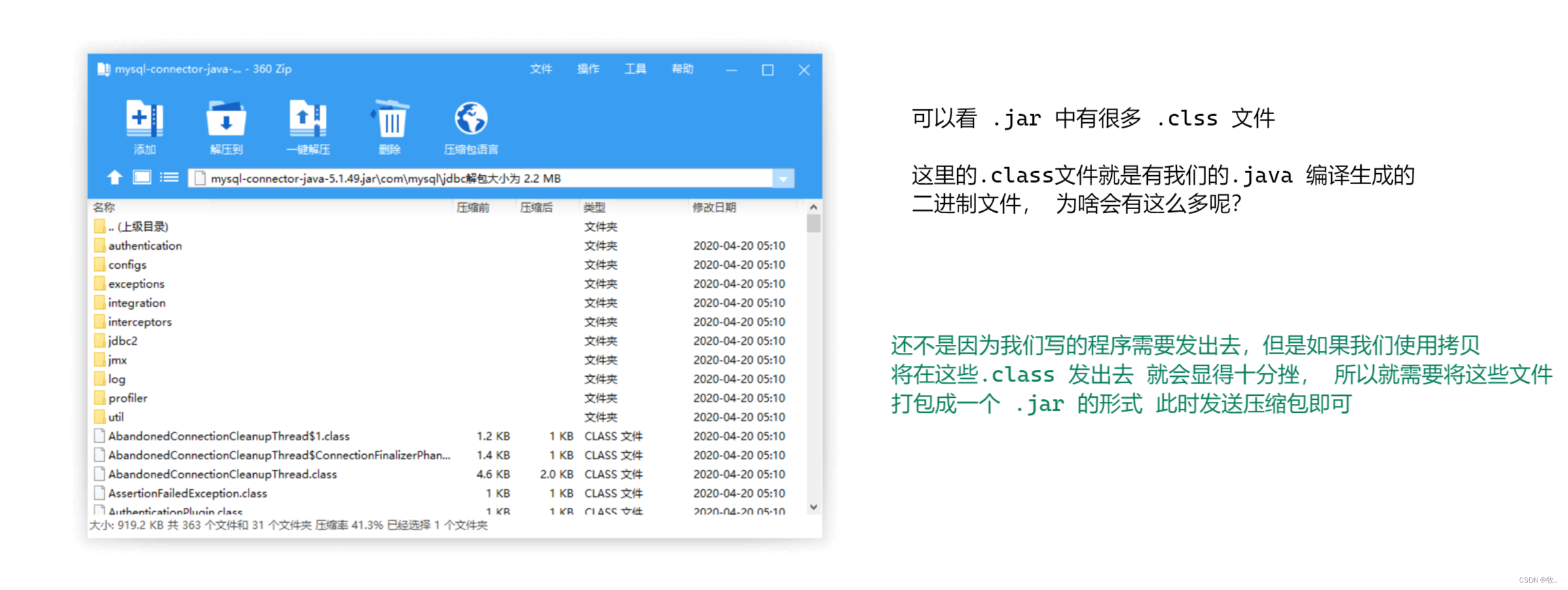
有了 .jar 包 我们就可以导入 idea中 , 使用即可 。
打开我们的 idea

下面我们就可以来编写我们的数据库代码 :
1. 创建数据源操作
图一 :
图二 :
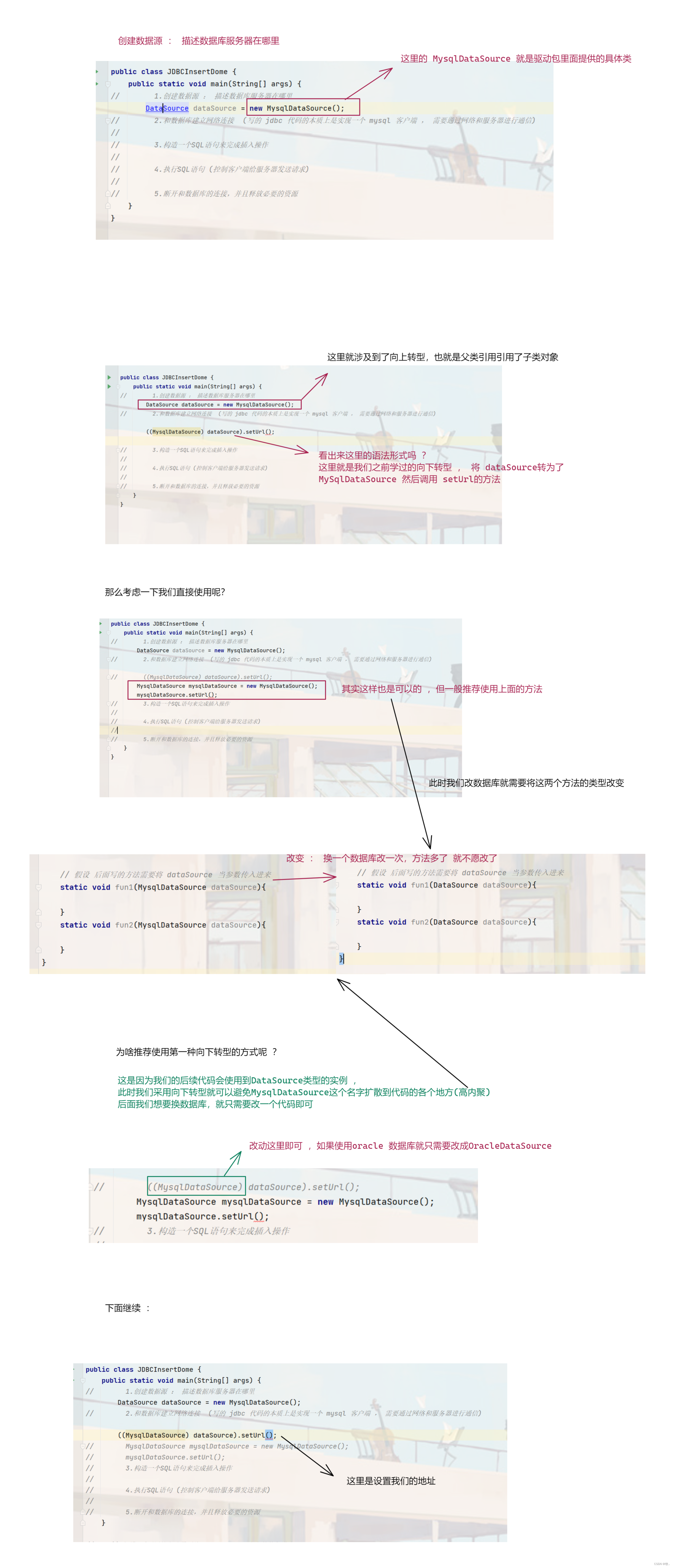
图三 :
图四 :

到此我们的第一步就完成了 , 可以看到我们这里只是描述了服务器在哪里,并没有真正的进行访问 , 下面的连接操作菜是真正的开始通过网络进行通信。
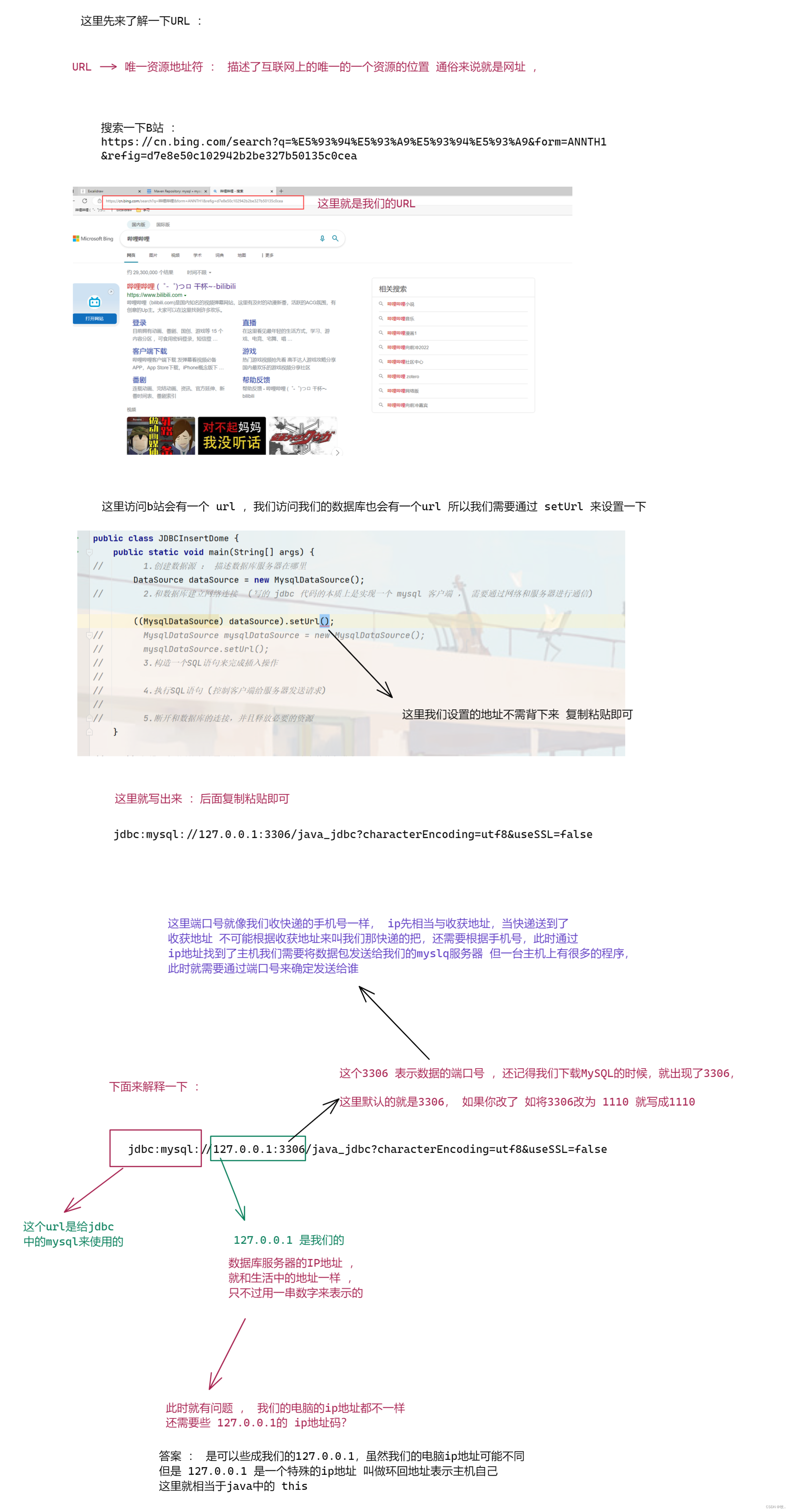
2.与数据库建立网络连接
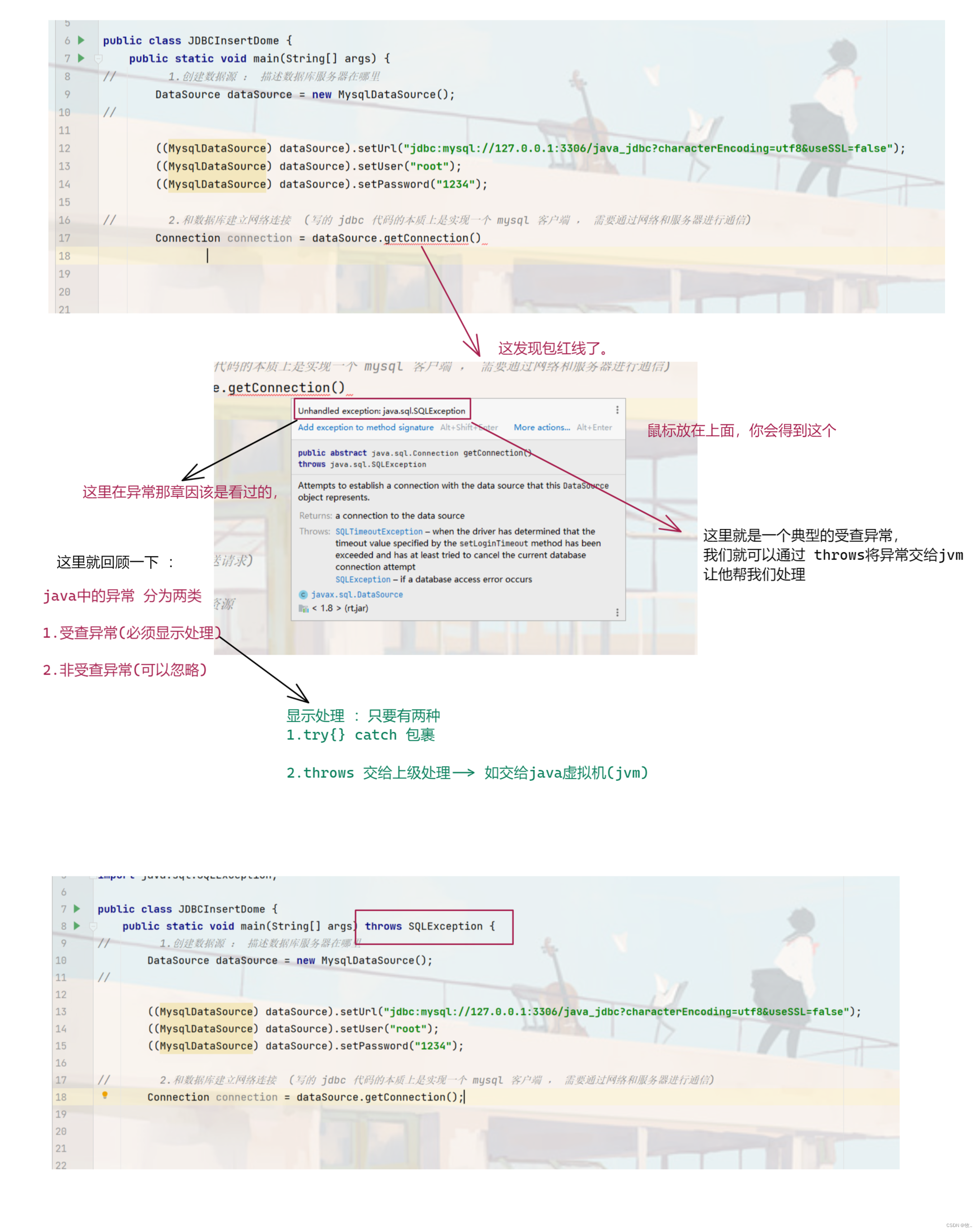
3.构造SQL 语句
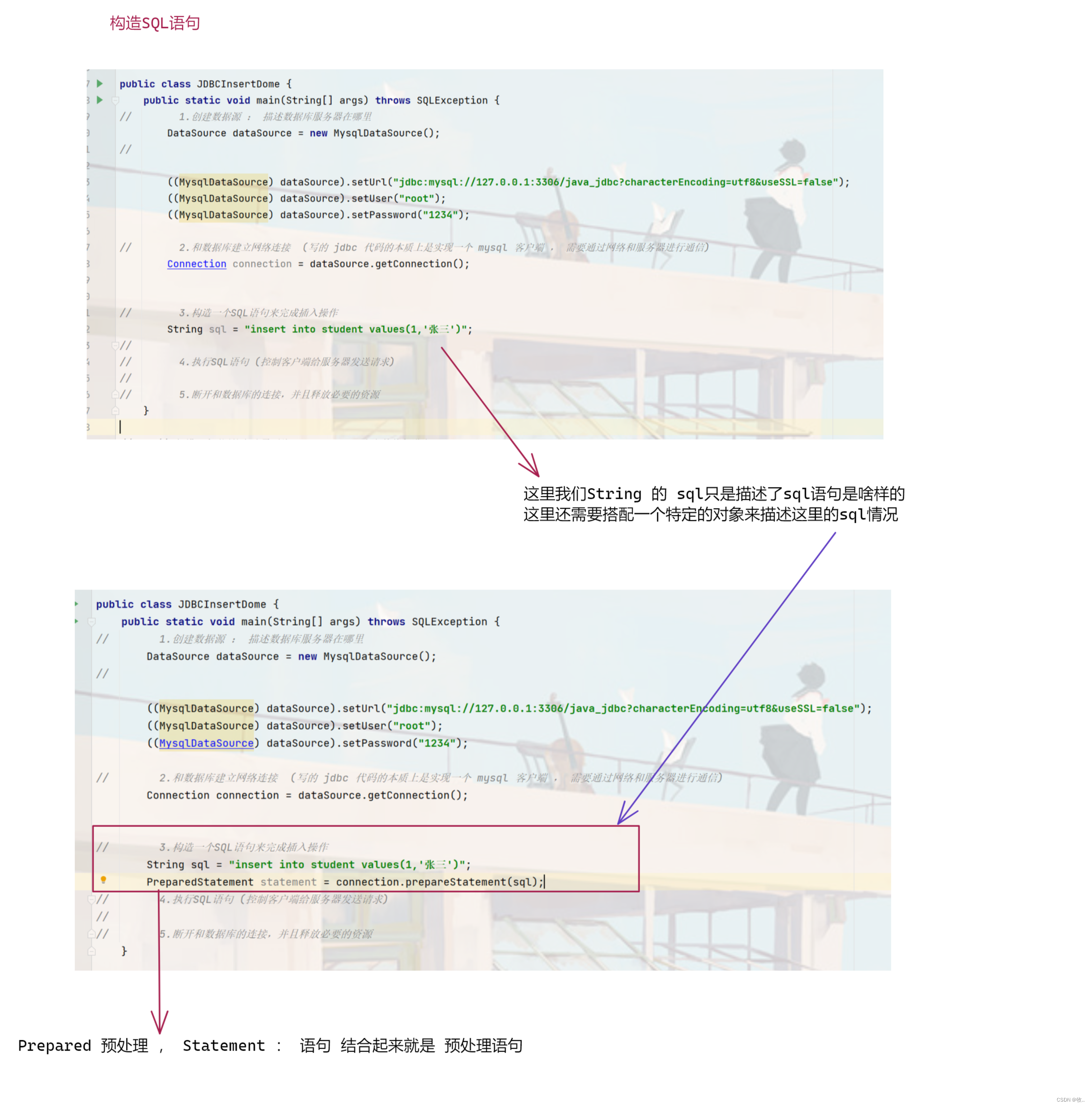
4. 执行SQL + 5.资源回收
另外 :
我们见到过的池有 字符串常量池 , 和刚刚看到的数据库连接池 , 后面我们还能见到 进程池 , 线程池, 内存池,数据库连接池 等
那么 就来简单的了解一下 池 pool : 假设 : 我们是一个妹子 长的好看, 又有才华 追求者非常多 , 此时我们同一时刻,只能谈一个对象, 此时我们想要换一个对象 ,此时成本就比较高 , 因为需要和新的小哥哥重新培养感情 , 此时就比较麻烦, 俗话说日久生情吗 , 此时我们就想到了一个办法 , 就是 与 A 谈对象的时候和B搞暧昧(这里本质上就在培养感情),一旦我们分手了, 那么B是不是就可以立刻上位 ,此时是不是就大大的提高了效率 ,此时B 就称为 备胎 。
这里 只有一个B , 假设我们除 了B 还有 C D E F G 等搞暧昧 ,此时 C D E F G 是不是就构成了一个备胎池 , 这样我们是不是一天换一个都有可能,此时是不是就非常高效 。
注意 : 这里的例子生活上是不提倡的, 虽然生活上不提倡, 但计算里面确非常流行 , 这里我们的数据库连接池就是这样 , 我们创建连接池的同时可以准备一批新的连接 ,此时就不是建立一个连接而是建立好几个连接,这些连接只是暂时未用放在池子里面,随时都可以拿出来使用 。如果我们需要很多连接就可以直接从池子里面拿出来进行连接使用, 另外我们释放的连接也是可以放到池子里面。
改造代码 :
下面继续 : 上面我们的插入操作, 其实不太还好,因为我们将数据写死了,insert into student values(1,'张三')这里就将我们插入的数据写死了 , 按道理是不是应该让用户来自己添加数据,我们根据用户的数据来进行插入,所以这里的代码就有些许不合理,下面我们就来改造一下。
图一 :
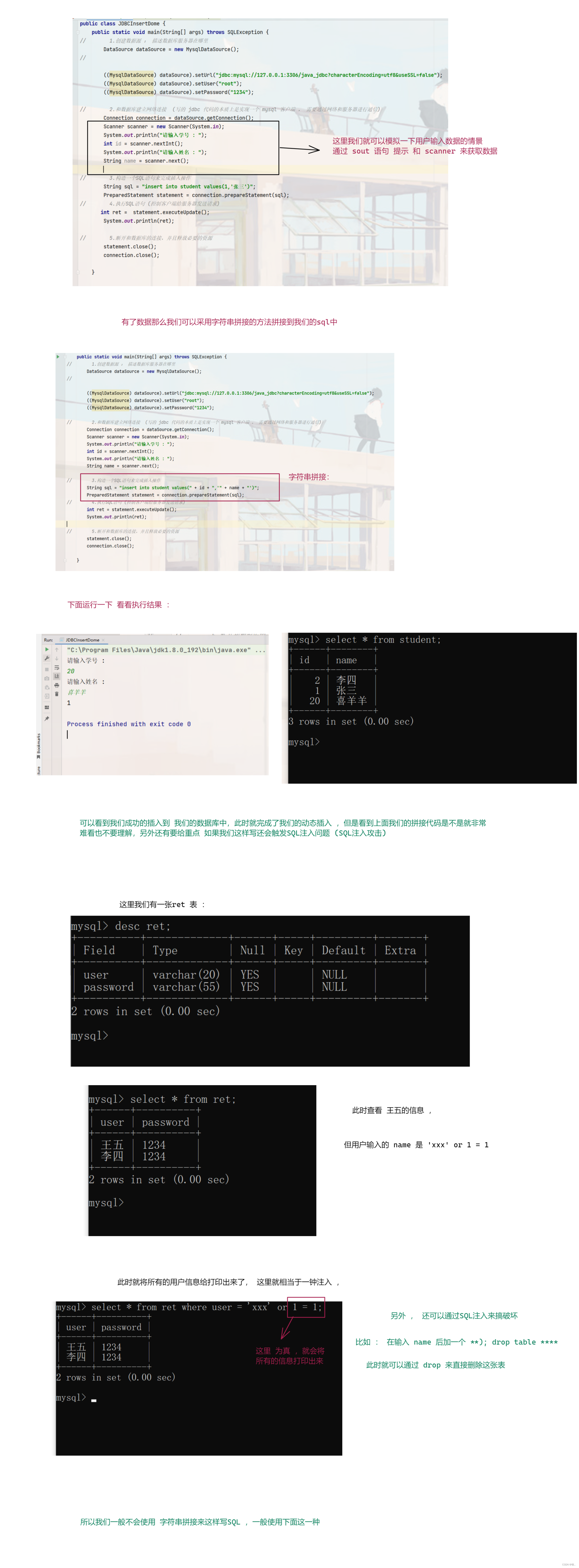
图二 :

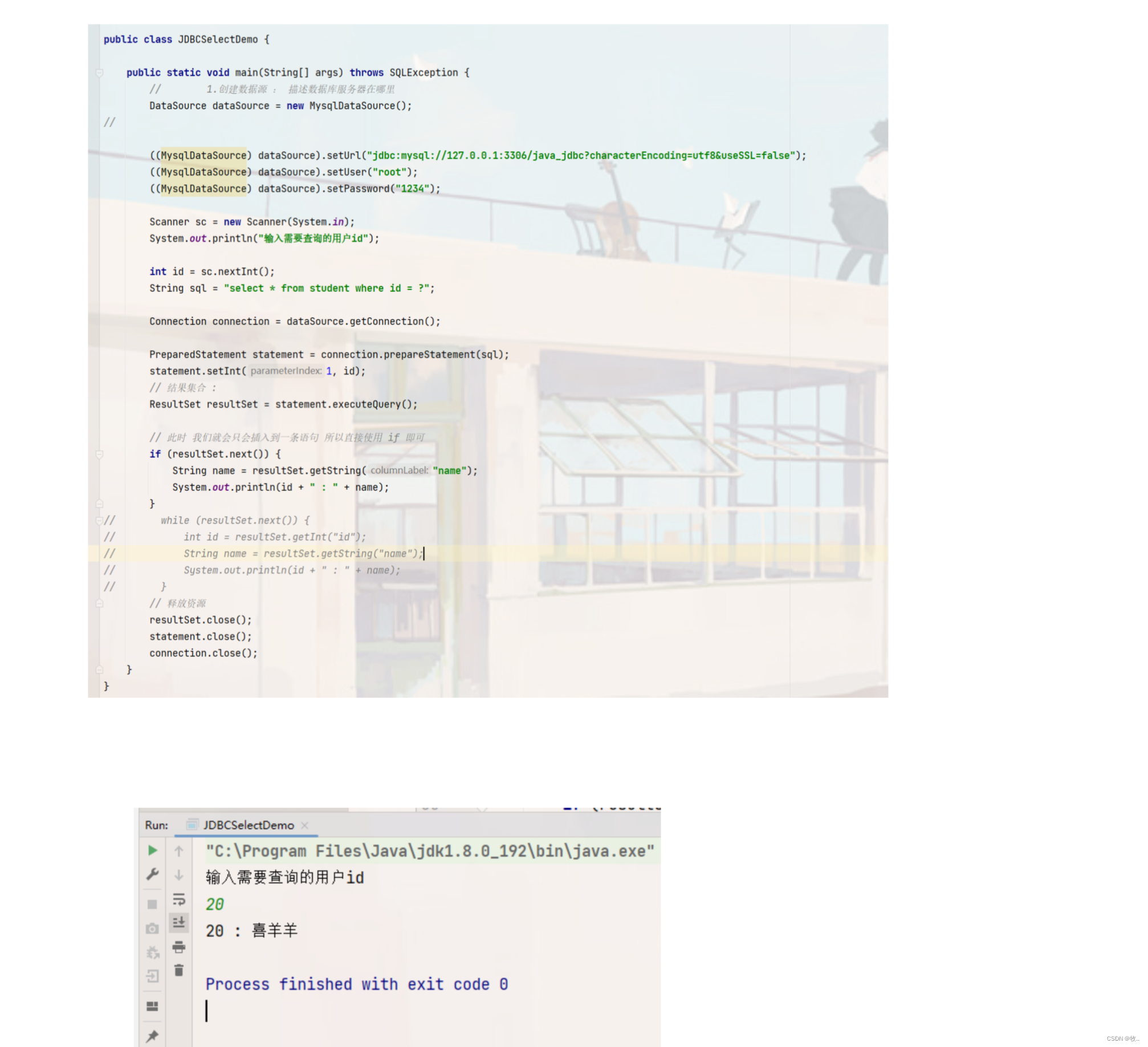
这里我们的增删查 , 都是返回影响的行数 ,最后我们来看一下 我们的查找操作 也是重点(我们往后大部分都在查找数据) , 这里我们就来学习一下 。
查找操作 :
其实 也不要太慌, 这里查找操作之不过多了一步就是遍历结果集合
图一 :

图二 :
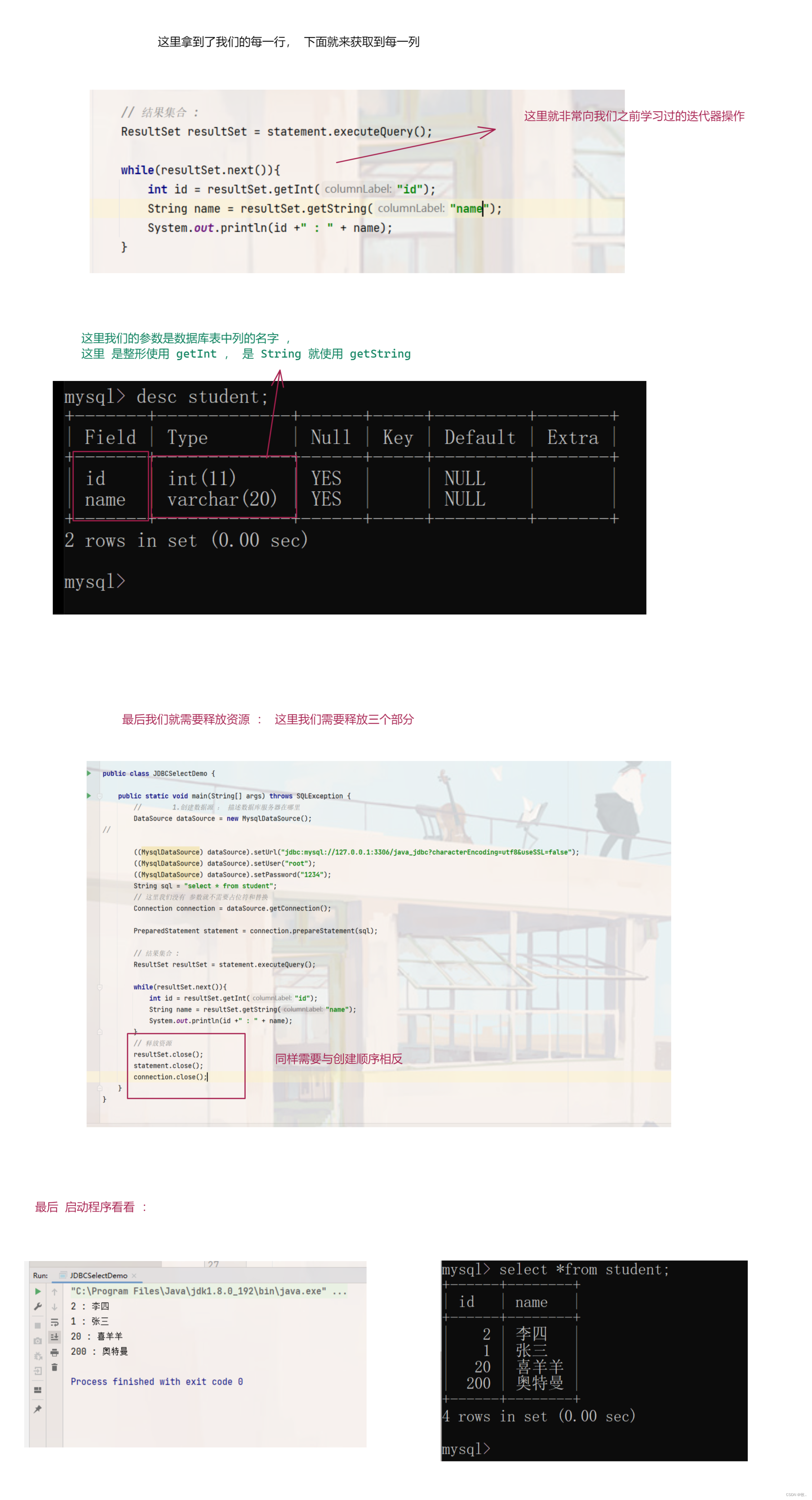
最后我们来写一个通过 id 来查询结果