Tensorflow 模型保存、节点修改以及Serving 图优化
文章目录
前言 (与正文无关, 可忽略)
近期打算总结一些 Tensorflow 的基础知识, 方便查阅. 本文的写作动机是考虑到一个小问题: 我们常用 tf.data 系列 API 来生成训练数据, 因此 Train Graph 的输入节点通常是 Iterator 节点 (比如会调用 tf.data.make_one_shot_iterator 以及该对象的 get_next() 方法), 但是在 Serving 的时候, 我在想应该如何处理输入节点, 如何把新增的 tf.placeholder 加入到 Serving 图中.
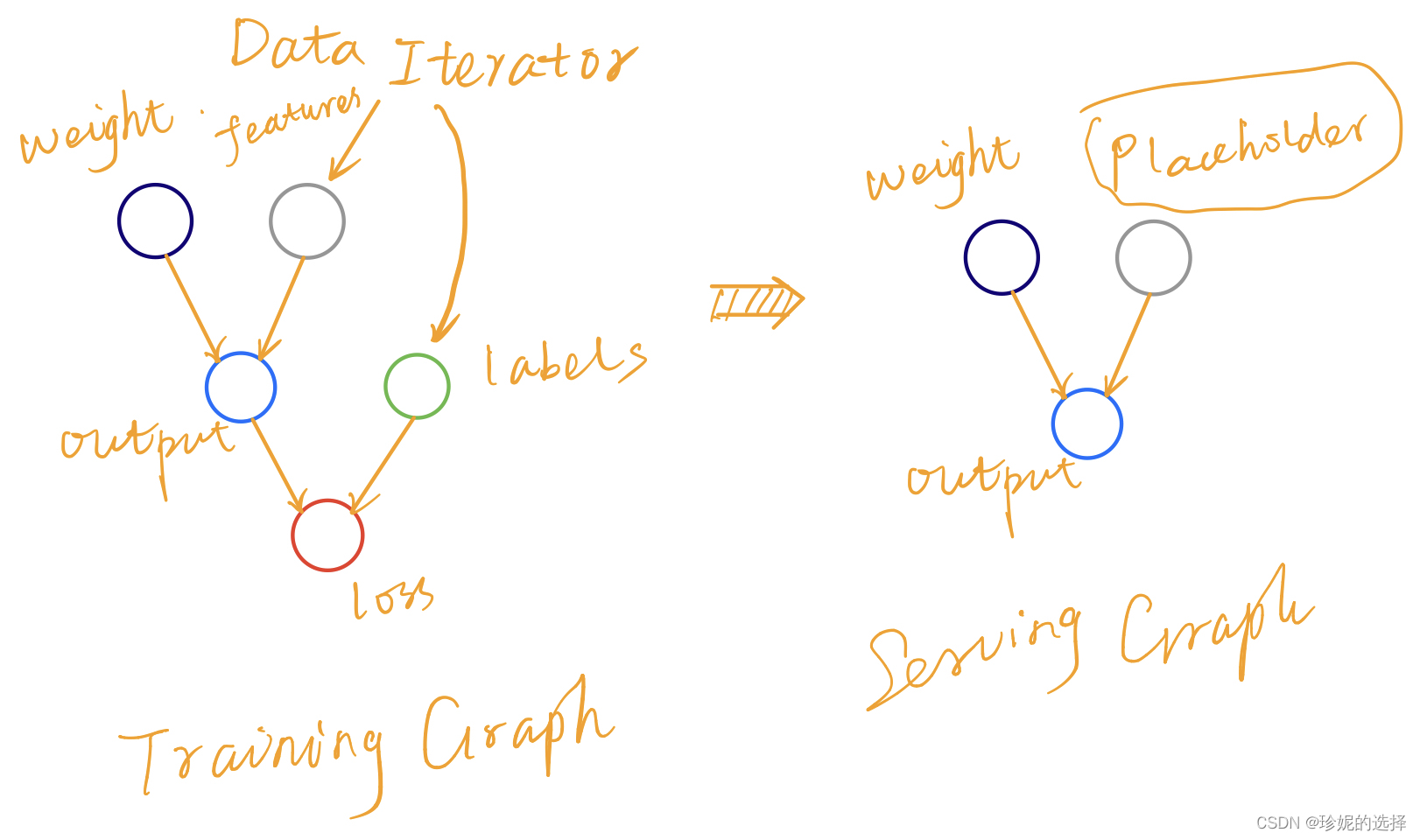
一种方法是将 Serving Graph 重新写一遍, 输入节点更新成 tf.placeholder, 然后输入到模型中, 从而生成一个新的 Graph; 但我希望有更简洁的方法, 比如能不能直接将 Iterator 输入节点替换成 tf.placeholder, 这样即便我不知道模型代码是如何写的, 也能构建好 Serving 图. 在该问题的指引下, 对 TF 模型的保存与加载, Graph/MetaGraph 等概念有了稍微深入的了解.
总览
本文介绍 Tensorflow 模型部分保存方式, 主要包含 checkpoint 格式、frozen_graph 格式(SavedModel 格式暂略), 通过代码实例了解模型的保存方式, Serving 图的优化以及对 Serving 图中的节点进行修改更新.
代码地址
本文代码在 Python 3.5.2 | Tensorflow 1.15.0 环境下测试成功.
本文所有代码均可以从 https://github.com/axzml/BlogShare/tree/master/Tensorflow/GraphDef 下载.
广而告之
可以在微信中搜索 “珍妮的算法之路” 或者 “world4458” 关注我的微信公众号, 可以及时获取最新原创技术文章更新.
另外可以看看知乎专栏 PoorMemory-机器学习, 以后文章也会发在知乎专栏中.
checkpoint 格式
训练代码 & 保存 ckpt
写了一个简单的训练代码(train.py)如下, 五脏俱全, 其中定义了三个主要函数:
data_generator(): 生成 Fake 数据参与模型训练model(): 定义了简单的神经网络train(): 定义训练代码, 调用tf.train.Saver()以 checkpoint 的形式保存模型
# _*_ coding:utf-8 _*_
## train.py
import tensorflow as tf
import os
import numpy as np
from os.path import join, exists
batch_size = 2
steps = 10
epochs = 1
emb_dim = 4
sample_num = epochs * steps * batch_size
checkpoint_dir = 'checkpoint_dir'
meta_name = '0'
saver_dir = join(checkpoint_dir, meta_name)
def data_generator():
"""产生 Fake 训练数据"""
dataset = tf.data.Dataset.from_tensor_slices((np.random.randn(sample_num, emb_dim),\
np.random.randn(sample_num)))
dataset = dataset.repeat(epochs).batch(batch_size)
iterator = tf.data.make_one_shot_iterator(dataset)
feature, label = iterator.get_next()
return feature, label
def model(feature, params=[10, 5, 1]):
"""定义模型, 3层DNN"""
fc1 = tf.layers.dense(feature, params[0], activation=tf.nn.relu, name='fc1')
fc2 = tf.layers.dense(fc1, params[1], activation=tf.nn.relu, name='fc2')
fc3 = tf.layers.dense(fc2, params[2], activation=tf.nn.sigmoid, name='fc3')
out = tf.identity(fc3, name='output')
return out
def train():
feature, label = data_generator()
output = model(feature)
loss = tf.reduce_mean(tf.square(output - label))
train_op = tf.train.AdamOptimizer(learning_rate=0.1, name='Adam').minimize(loss)
saver = tf.train.Saver()
if exists(checkpoint_dir):
os.system('rm -rf {}'.format(checkpoint_dir))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
try:
local_step = 0
save_freq = 2
while True:
local_step += 1
_, loss_val = sess.run([train_op, loss])
if local_step % save_freq == 0:
saver.save(sess, saver_dir)
print('loss: {:.4f}'.format(loss_val))
except tf.errors.OutOfRangeError:
print("train end!")
if __name__ == '__main__':
train()
运行 python train.py 会在当前目录下生成 checkpoint_dir 目录, 其组成如下:
checkpoint_dir/
|-- 0.data-00000-of-00001 ## 记录了网络参数值
|-- 0.index ## 记录了网络参数名
|-- 0.meta ## 保存 MetaGraphDef, 该文件以 pb 格式记录了网络结构
`-- checkpoint ## 该文件记录了最新的 ckpt
加载 ckpt & 检查 graph 结构
checkpoint 格式的模型需要在 Tensorflow 框架下进行加载. 比如编写 eval.py 进行 inference, 代码如下:
#_*_ coding:utf-8 _*_
## eval.py
import tensorflow as tf
import os
from os.path import join, exists
import numpy as np
emb_dim = 4
checkpoint_dir = 'checkpoint_dir'
meta_name = '0'
saver_dir = join(checkpoint_dir, meta_name)
meta_file = saver_dir + '.meta'
model_file = tf.train.latest_checkpoint(checkpoint_dir)
np.random.seed(123)
test_data = np.random.randn(4, emb_dim) ## 生成测试数据
def eval_graph():
with tf.Session() as sess:
saver = tf.train.import_meta_graph(meta_file)
saver.restore(sess, model_file)
output = sess.run(['output:0'], feed_dict={
'IteratorGetNext:0': test_data
})
print('eval_graph:\n{}'.format(output))
if __name__ == '__main__':
eval_graph()
在上面代码中, 注意到输入和输出节点名分别为 output 以及 IteratorGetNext. 对于输出节点, 由于在 train.py 的 model() 函数中使用
out = tf.identity(fc3, name='output')
对输出节点重新命名为 output, 因此输出节点的名字非常好确定. 但是输入节点的名字却不太好确定, 原因是训练时采用 tf.data API 来传入数据, 没有显式地对输入节点进行命名. 不过由于保存模型时网络结构都已经存放在 0.meta 文件中了, 因此可以通过解析该文件来查看网络的输入节点, 具体方法如下:
#_*_ coding:utf-8 _*_
## check_graph.py
import tensorflow as tf
from tensorflow.python.framework import meta_graph
from tensorflow.core.protobuf.meta_graph_pb2 import MetaGraphDef
from google.protobuf import text_format
import os
from os.path import join, exists
import numpy as np
checkpoint_dir = 'checkpoint_dir'
meta_name = '0'
saver_dir = join(checkpoint_dir, meta_name)
meta_file = saver_dir + '.meta'
model_file = tf.train.latest_checkpoint(checkpoint_dir)
def read_pb_meta(meta_file):
"""读取 pb 格式的 meta 文件"""
meta_graph_def = meta_graph.read_meta_graph_file(meta_file)
return meta_graph_def
def read_txt_meta(txt_meta_file):
"""读取文本格式的 meta 文件"""
meta_graph = MetaGraphDef()
with open(txt_meta_file, 'rb') as f:
text_format.Merge(f.read(), meta_graph)
return meta_graph
def read_pb_graph(graph_file):
"""读取 pb 格式的 graph_def 文件"""
try:
with tf.gfile.GFile(graph_file, 'rb') as pb:
graph_def = tf.GraphDef()
graph_def.ParseFromString(pb.read())
except IOError as e:
raise Exception("Parse '{}' Failed!".format(graph_file))
return graph_def
def check_graph_def(graph_def):
"""检查 graph_def 中的各节点"""
with tf.Graph().as_default() as graph:
tf.import_graph_def(
graph_def,
name=""
)
print('===> {}'.format(type(graph)))
for op in graph.get_operations():
print(op.name, op.values()) ## 打印网络结构
def check_graph(graph_file):
"""检查 pb 格式的 graph_def 文件中的各节点"""
graph_def = read_pb_graph(graph_file)
check_graph_def(graph_def)
if __name__ == '__main__':
check_graph_def(read_pb_meta(meta_file).graph_def)
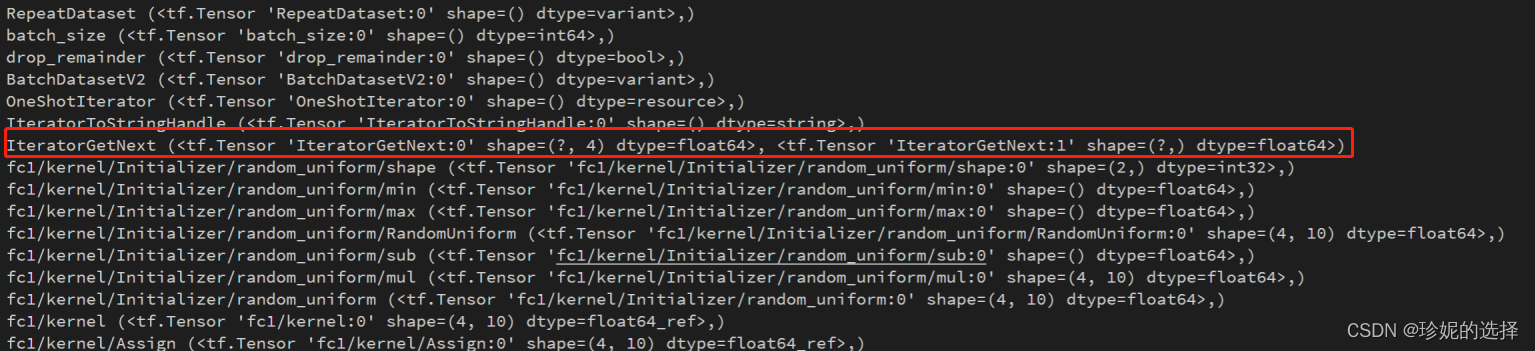
输出结果如下图所示, 可以发现距离网络参数 fc1/kernel 最近的节点是 IteratorGetNext, 因此输入节点的名字基本可以确认是它了.
节点修改
现在回到 “前言” 中提到的问题, 如果我希望使用自行创建的 tf.placeholder 节点作为 Graph 的输入节点, 而不是采用 IteratorGetNext, 应该如何实现. 一方面可以重新将 Tensorflow Graph 写一遍, 使用 tf.placeholder 作为输入; 另一方面其实可以考虑将 IteratorGetNet 节点用自定义的节点给替换掉, 这一步参考了博文 如何在建好TF图后修改图. 具体做法如下, 代码在 infer.py 中:
#_*_ coding:utf-8 _*_
## infer.py
import tensorflow as tf
from tensorflow.python.framework import meta_graph
import os
from os.path import join, exists
import numpy as np
emb_dim = 4
checkpoint_dir = 'checkpoint_dir'
meta_name = '0'
saver_dir = join(checkpoint_dir, meta_name)
meta_file = saver_dir + '.meta'
model_file = tf.train.latest_checkpoint(checkpoint_dir)
np.random.seed(123)
test_data = np.random.randn(4, emb_dim)
def read_pb_meta(meta_file):
meta_graph_def = meta_graph.read_meta_graph_file(meta_file)
return meta_graph_def
def update_node(graph, src_node_name, tar_node):
"""
@params:
graph : tensorflow Graph object
src_node_name : source node name to be modified
tar_node : target node
"""
input = graph.get_tensor_by_name('{}:0'.format(src_node_name))
for op in input.consumers():
idx_list = []
for idx, item in enumerate(op.inputs):
if src_node_name in item.name:
idx_list.append(idx)
for idx in idx_list:
op._update_input(idx, tar_node)
def modify_graph():
meta_graph_def = read_pb_meta(meta_file)
with tf.Graph().as_default() as graph:
tf.import_graph_def(meta_graph_def.graph_def, name="")
input_ph = tf.placeholder(tf.float64, [None, emb_dim], name='input')
update_node(graph, 'IteratorGetNext', input_ph)
with tf.Session(graph=graph) as sess:
saver = tf.train.import_meta_graph(meta_file)
saver.restore(sess, model_file)
output = sess.run(['output:0'], feed_dict={
'input:0': test_data
})
print('modify_graph:\n{}'.format(output))
if __name__ == '__main__':
modify_graph()
该文件定义了函数 update_node 来实现对 graph 中节点的替换, 函数如下:
def update_node(graph, src_node_name, tar_node):
"""
@params:
graph : tensorflow Graph object
src_node_name : source node name to be modified
tar_node : target node
"""
input = graph.get_tensor_by_name('{}:0'.format(src_node_name))
for op in input.consumers():
idx_list = []
for idx, item in enumerate(op.inputs):
if src_node_name in item.name:
idx_list.append(idx)
for idx in idx_list:
op._update_input(idx, tar_node)
其中 src_node_name 表示要被替换掉的节点名字, 比如希望替换 IteratorGetNext. 通过该名字在 graph 中找到对应的节点 input, 然后调用 input.consumers() 找到使用该节点的 op, 再通过更新 op 的输入 (op.inputs) 来实现对节点的替换. 由于替换的方法 op._update_input 需要使用索引 idx, 因此用 idx_list 来记录要替换节点的索引.
frozen_graph 格式
前面介绍的 checkpoint 格式将网络结构和参数分开保存, 而 frozen_graph 格式则会将网络参数以 Const 节点的形式写入到 GraphDef, 并保存到统一的 protobuf 文件中, 由于 protobuf 是跨语言、跨平台序列化数据协议, 因此还可以用 C++/Java/Python 等对模型进行加载.
下面写了个简单的将 ckpt 转换为 frozen_graph 的例子 frozen_graph.py, 代码如下:
#_*_ coding:utf-8 _*_
## frozen_graph.py
import tensorflow as tf
from tensorflow.python.framework import meta_graph
from tensorflow.python.framework import dtypes
from tensorflow.python.tools import optimize_for_inference_lib
import os
from os.path import join, exists
import numpy as np
emb_dim = 4
checkpoint_dir = 'checkpoint_dir'
meta_name = '0'
saver_dir = join(checkpoint_dir, meta_name)
meta_file = saver_dir + '.meta'
model_file = tf.train.latest_checkpoint(checkpoint_dir)
np.random.seed(123)
test_data = np.random.randn(4, emb_dim)
def read_pb_meta(meta_file):
meta_graph_def = meta_graph.read_meta_graph_file(meta_file)
return meta_graph_def
def update_node(graph, src_node_name, tar_node):
"""
@params:
graph : tensorflow Graph object
src_node_name : source node name to be modified
tar_node : target node
"""
input = graph.get_tensor_by_name('{}:0'.format(src_node_name))
for op in input.consumers():
idx_list = []
for idx, item in enumerate(op.inputs):
if src_node_name in item.name:
idx_list.append(idx)
for idx in idx_list:
op._update_input(idx, tar_node)
def check_graph_def(graph_def):
with tf.Graph().as_default() as graph:
tf.import_graph_def(
graph_def,
name=""
)
print('===> {}'.format(type(graph)))
for op in graph.get_operations():
print(op.name, op.values()) ## 打印网络结构
def write_frozen_graph():
meta_graph_def = read_pb_meta(meta_file)
with tf.Graph().as_default() as graph:
tf.import_graph_def(meta_graph_def.graph_def, name="")
input_ph = tf.placeholder(tf.float64, [None, emb_dim], name='input')
update_node(graph, 'IteratorGetNext', input_ph)
with tf.Session(graph=graph) as sess:
saver = tf.train.import_meta_graph(meta_file)
saver.restore(sess, model_file)
input_node_names = ['input']
##placeholder_type_enum = [dtypes.float64.as_datatype_enum]
placeholder_type_enum = [input_ph.dtype.as_datatype_enum]
output_node_names = ['output']
## 对 graph 进行优化, 把和 inference 无关的节点给删除, 比如 Saver 有关的节点
graph_def = optimize_for_inference_lib.optimize_for_inference(
graph.as_graph_def(), input_node_names, output_node_names, placeholder_type_enum
)
check_graph_def(graph_def)
## 将 ckpt 转换为 frozen_graph, 网络权重和结构写入统一 pb 文件中, 参数以 Const 的形式保存
frozen_graph = tf.graph_util.convert_variables_to_constants(sess,
graph_def, output_node_names)
out_graph_path = os.path.join('.', "frozen_model.pb")
with tf.gfile.GFile(out_graph_path, "wb") as f:
f.write(frozen_graph.SerializeToString())
def read_frozen_graph():
with tf.Graph().as_default() as graph:
graph_def = tf.GraphDef()
with open("frozen_model.pb", 'rb') as f:
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
# print(graph_def)
with tf.Session(graph=graph) as sess:
output = sess.run(['output:0'], feed_dict={
'input:0': test_data
})
print('frozen_graph:\n{}'.format(output))
if __name__ == '__main__':
write_frozen_graph()
read_frozen_graph()
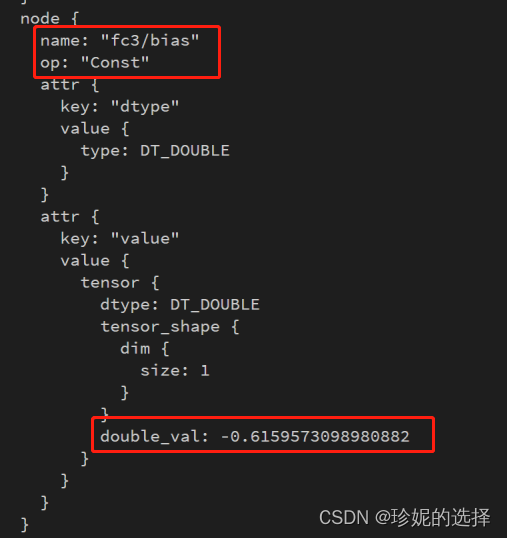
其中 write_frozen_graph() 中调用 optimize_for_inference_lib.optimize_for_inference 对 Graph 节点进行优化, 将在下一节进行介绍. 此外还调用 tf.graph_util.convert_variables_to_constants 将 ckpt 转换为 frozen_graph, 参数以 Const 的形式保存:
Serving 图优化
在上一节生成 frozen_graph 时, 调用了 optimize_for_inference_lib.optimize_for_inference 对 Graph 节点进行优化, 本节简要对其进行说明. 在调用该函数前如果打印从 checkpoint 中加载的 graph 时, 会发现结构中包含很多在训练时需要但在线 Serving 时并不需要的 Op, 如优化算法 Adam, 模型保存 Saver, 梯度 gradients 等等, 如下图:
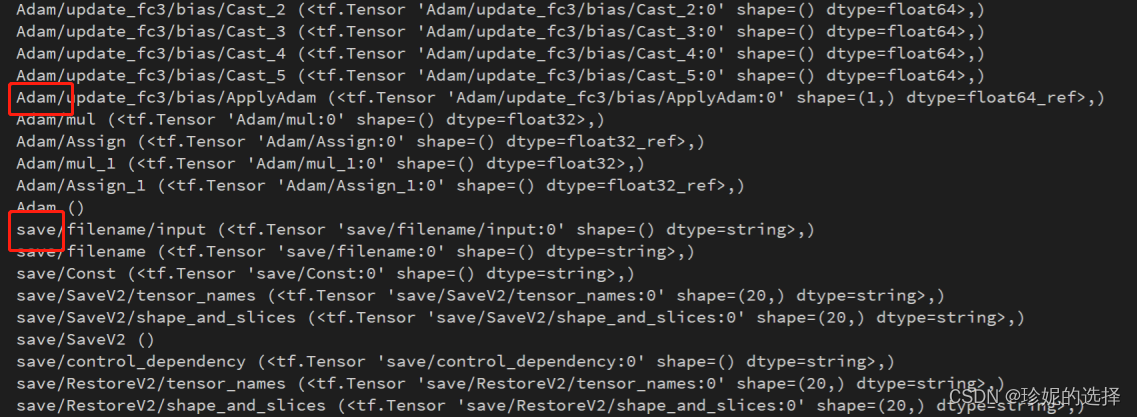
optimize_for_inference_lib.optimize_for_inference 函数的一个主要工作就是将 graph 在 Serving 时无用的 Op 给去除.
def optimize_for_inference(input_graph_def, input_node_names, output_node_names,
placeholder_type_enum, toco_compatible=False):
## ..... 显示核心代码
optimized_graph_def = strip_unused_lib.strip_unused(
optimized_graph_def, input_node_names, output_node_names,
placeholder_type_enum)
optimized_graph_def = graph_util.remove_training_nodes(
optimized_graph_def, output_node_names)
## ....
return optimized_graph_def
其中 strip_unused_lib.strip_unused 定义如下:
def strip_unused(input_graph_def, input_node_names, output_node_names,
placeholder_type_enum):
"""Removes unused nodes from a GraphDef.
Args:
input_graph_def: A graph with nodes we want to prune.
input_node_names: A list of the nodes we use as inputs.
output_node_names: A list of the output nodes.
placeholder_type_enum: The AttrValue enum for the placeholder data type, or
a list that specifies one value per input node name.
Returns:
A `GraphDef` with all unnecessary ops removed.
Raises:
ValueError: If any element in `input_node_names` refers to a tensor instead
of an operation.
KeyError: If any element in `input_node_names` is not found in the graph.
"""
for name in input_node_names:
if ":" in name:
raise ValueError(f"Name '{
name}' appears to refer to a Tensor, not an "
"Operation.")
# Here we replace the nodes we're going to override as inputs with
# placeholders so that any unused nodes that are inputs to them are
# automatically stripped out by extract_sub_graph().
not_found = {
name for name in input_node_names}
inputs_replaced_graph_def = graph_pb2.GraphDef()
for node in input_graph_def.node:
if node.name in input_node_names:
not_found.remove(node.name)
placeholder_node = node_def_pb2.NodeDef()
placeholder_node.op = "Placeholder"
placeholder_node.name = node.name
if isinstance(placeholder_type_enum, list):
input_node_index = input_node_names.index(node.name)
placeholder_node.attr["dtype"].CopyFrom(
attr_value_pb2.AttrValue(type=placeholder_type_enum[
input_node_index]))
else:
placeholder_node.attr["dtype"].CopyFrom(
attr_value_pb2.AttrValue(type=placeholder_type_enum))
if "_output_shapes" in node.attr:
placeholder_node.attr["_output_shapes"].CopyFrom(node.attr[
"_output_shapes"])
if "shape" in node.attr:
placeholder_node.attr["shape"].CopyFrom(node.attr["shape"])
inputs_replaced_graph_def.node.extend([placeholder_node])
else:
inputs_replaced_graph_def.node.extend([copy.deepcopy(node)])
if not_found:
raise KeyError(f"The following input nodes were not found: {
not_found}.")
output_graph_def = graph_util.extract_sub_graph(inputs_replaced_graph_def,
output_node_names)
return output_graph_def
该代码需要传入 graph_def, 输入节点名字 input_node_names 以及输出节点名字 output_node_names, 前面一大段代码是为了用 Placeholder 替换原本的输入节点, 算是将整个 Graph 重新写了一遍. 之后在 graph_util.extract_sub_graph 函数中, 利用 BFS 算法保留 Serving 时需要的节点, 而将不需要的节点全部给去除:
def extract_sub_graph(graph_def, dest_nodes):
"""Extract the subgraph that can reach any of the nodes in 'dest_nodes'.
Args:
graph_def: A graph_pb2.GraphDef proto.
dest_nodes: An iterable of strings specifying the destination node names.
Returns:
The GraphDef of the sub-graph.
Raises:
TypeError: If 'graph_def' is not a graph_pb2.GraphDef proto.
"""
## ... BFS 遍历 Serving 时用到的节点
nodes_to_keep = _bfs_for_reachable_nodes(dest_nodes, name_to_input_name)
nodes_to_keep_list = sorted(
list(nodes_to_keep), key=lambda n: name_to_seq_num[n])
# Now construct the output GraphDef
out = graph_pb2.GraphDef()
for n in nodes_to_keep_list:
out.node.extend([copy.deepcopy(name_to_node[n])])
out.library.CopyFrom(graph_def.library)
out.versions.CopyFrom(graph_def.versions)
return out
其中 BFS 函数定义如下:
def _node_name(n):
if n.startswith("^"):
return n[1:]
else:
return n.split(":")[0]
def _extract_graph_summary(graph_def):
"""Extracts useful information from the graph and returns them."""
name_to_input_name = {
} # Keyed by the dest node name.
name_to_node = {
} # Keyed by node name.
# Keeps track of node sequences. It is important to still output the
# operations in the original order.
name_to_seq_num = {
} # Keyed by node name.
seq = 0
for node in graph_def.node:
n = _node_name(node.name)
name_to_node[n] = node
name_to_input_name[n] = [_node_name(x) for x in node.input]
### ....
name_to_seq_num[n] = seq
seq += 1
return name_to_input_name, name_to_node, name_to_seq_num
def _bfs_for_reachable_nodes(target_nodes, name_to_input_name):
"""Breadth first search for reachable nodes from target nodes."""
nodes_to_keep = set()
# Breadth first search to find all the nodes that we should keep.
next_to_visit = list(target_nodes)
while next_to_visit:
node = next_to_visit[0]
del next_to_visit[0]
if node in nodes_to_keep:
# Already visited this node.
continue
nodes_to_keep.add(node)
if node in name_to_input_name:
next_to_visit += name_to_input_name[node]
return nodes_to_keep
之所以把这几段代码单独拎出来, 可以在合适的时候拿出来对 graph_def 进行调试, 打印中间结果. 经过 optimize_for_inference_lib.optimize_for_inference 的处理后, graph 更为简洁轻量, 打印其中的 Op 得到:
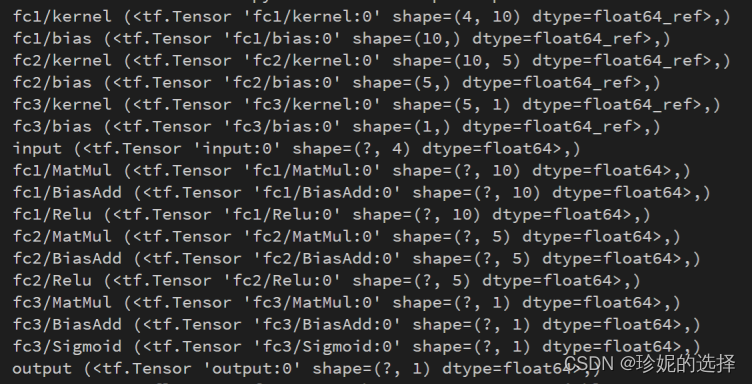
可以看到, 训练中会用到的 Adam, Saver 等节点全部被移除了, 整个 graph 变得异常干净整洁.
总结
写文章就是, 一鼓作气, 再而衰, 三而竭, 再一鼓作气.
我要去玩耍了.