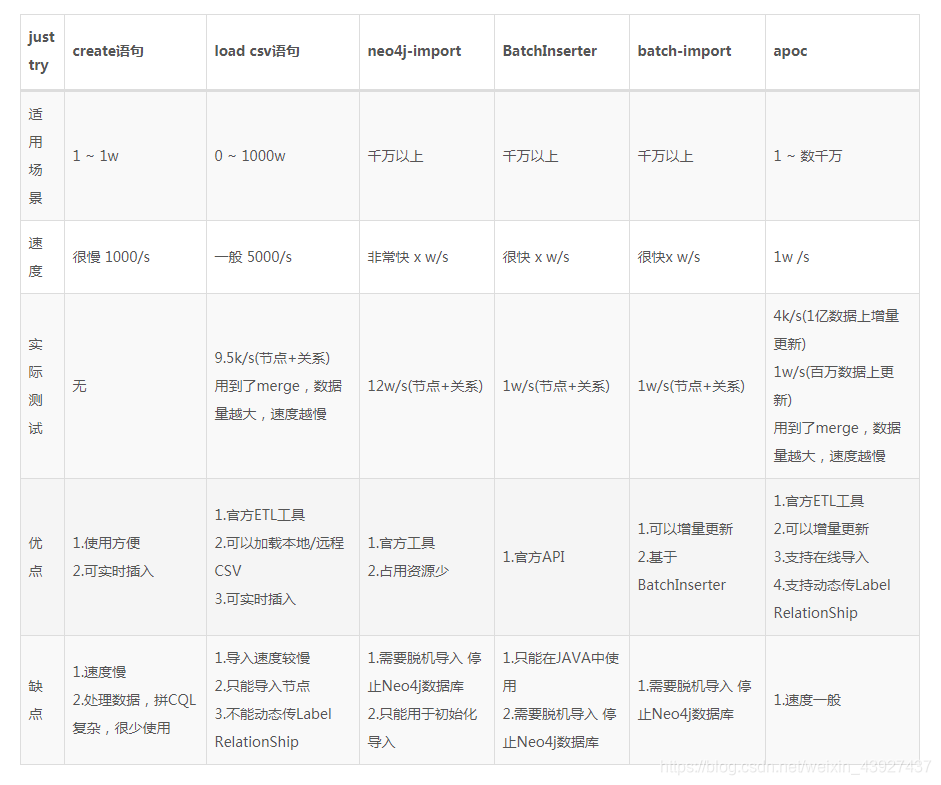
neo4j导入数据的方式有以下几种:
- Cypher create 语句,为每一条数据写一个create
- Cypher load csv 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
- neo4j-admin import导入
- 官方提供的Java API - BatchInserter
- 大牛编写的 batch-import 工具
- neo4j-apoc load.csv + apoc.load.relationship
针对实际业务场景,定制化开发:
CSV文件导入
参考: Neo4j:入门基础(二)之导入CSV文件_Dawn_www的博客-CSDN博客_neo4j导入csv文件
RDF导入neo4j数据库
数据导入之neo4j-admin和neo4j-import的区别
注意: 目前比较常用的批量导入数据的方法有两种,新版本提供的neo4j-import和旧版本升级的neo4j-admin import,之间有些许的不同,但在导入数据的效率上没有太多的不同。
neo4j-admin参数
usage: neo4j-admin import [--mode=csv] [--database=<name>] //模式,默认csv
[--additional-config=<config-file-path>]
[--report-file=<filename>]
[--nodes[:Label1:Label2]=<"file1,file2,...">] //实体文件
[--relationships[:RELATIONSHIP_TYPE]=<"file1,file2,...">] // 关系文件
[--id-type=<STRING|INTEGER|ACTUAL>]
[--input-encoding=<character-set>] // 编码格式
[--ignore-extra-columns[=<true|false>]] // 忽略多余列参数
[--ignore-duplicate-nodes[=<true|false>]] // 忽略重复节点参数
[--ignore-missing-nodes[=<true|false>]] // 忽略丢失的节点参数
或者
bin/neo4j-import [--into]
[--id-type=<STRING|INTEGER|ACTUAL>]
[--nodes[:Label1:Label2]=<"file1,file2,...">] //实体文件
[--relationships[:RELATIONSHIP_TYPE]=<"file1,file2,...">] // 关系文件
Neo4j多库切换
- 方法一:因为Neo4j的import导入时,只能导入一个不存的db,这就在想创建多个库时,需要去切换,Neo4j默认的库是graph.db,在./conf/neo4j.conf可以修改
# Neo4j configuration
#
# For more details and a complete list of settings, please see
# https://neo4j.com/docs/operations-manual/current/reference/configuration-settings/
#*****************************************************************
# The name of the database to mount
#dbms.active_database=graph.db
- 方法二:切换多个库的方法,将新库重新连接到默认库graph.db,然后重启Neo4j
//软连接
cd ./data/databases/
ln -s graph_kg.db graph.db
//重启neo4j
cd $NEO4j_HOME/bin
./neo4j restart
// 删除软连接
ln-s test_chk test_chk_ln
rm -rf ./test_chk_ln