一点感想
这是本人的内容安全课堂作业,参考一些网上代码与文章,汇报时排在前面的大佬都是各种深度学习曲线分析,参数调整,获得了教辅博士的大力表扬,本人啥也不会,只能选择一篇简单的论文进行复现,并且进行若干改进,在此记录以避免踩坑。
涉及知识点
中文分词(词性分析),TF-IDF,朴素贝叶斯,人工神经网络
论文内容
进入正文,首先进行论文复现,本论文是基于表情符分析的情感关键句提取方法,里面用到了基于表情符分析的句子情感极性计算、关键词计算、位置信息计算
其中基于表情符分析的句子情感极性计算是对现有方法的改进,通过融入表情符分析提升情感关键句提取的正确率,论文如下

这篇文章主要是介绍表情符分类的若干新方式与新模型,并未提出实现的具体方式,故代码实现时做了一些变化。
论文复现
表情符处理
首先是进行表情符的提取,因为表情符都有[]包裹,所以根据此特征进行匹配提取,所有数据集里的表情符都存至一个数组中,供后面进行处理,首先是第一个函数pre_processer.py介绍
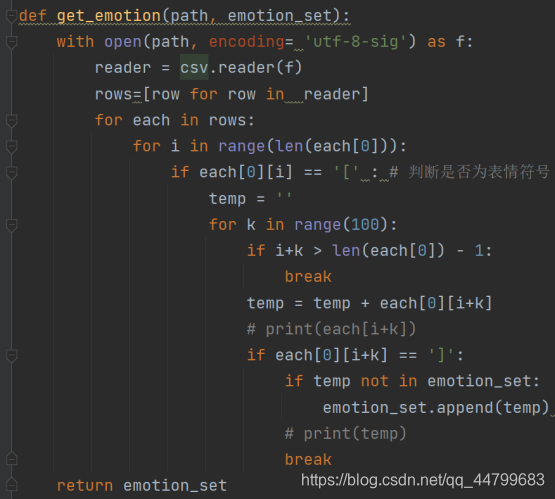
然后将这些表情符进行存储,避免后面进行重复读取,浪费时间
下一个函数进行表情的分类,这里参考论文中的共现率判断方式来评判未知表情的情感,但需要说明的是这里和论文中的复现基础不同,论文中的数据集是采用词向量的训练集,而这里给出的是句向量的标签信息,所以方式做了一个调整,判断该表情在积极句子中出现的次数与消极句子中出现的次数,同时也有中性的句子
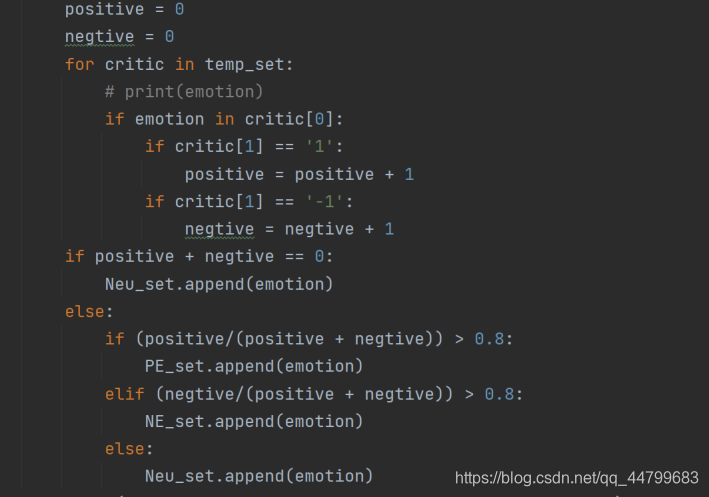
当积极占比大于0.8时就是积极表情,消极同理,其余的由于情感不明显,归入中立的表情当中,分别存入三个数组,至此,表情的情感分类已经完成
文本处理
下面是文字处理的部分,也就是specialize.py部分,复现了论文中的一些关于文字权重的操作,并且进行了一些改进。首先由于给的数据集是句子,而且其中有很多诸如@、//之类的杂质对分析不利
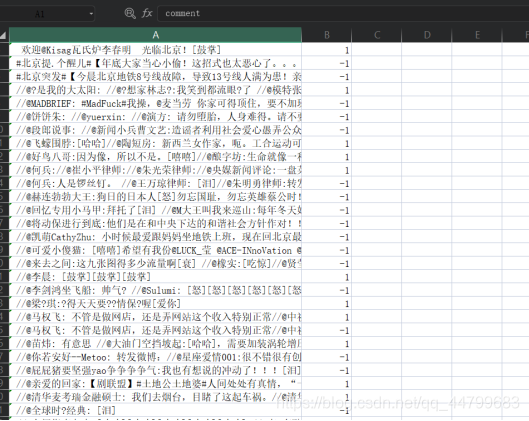
所以首先应该做的就是数据清洗的工作,首先进行匹配过滤与正则过滤,把一些肉眼可见出现频率很高的无意义符号给去除
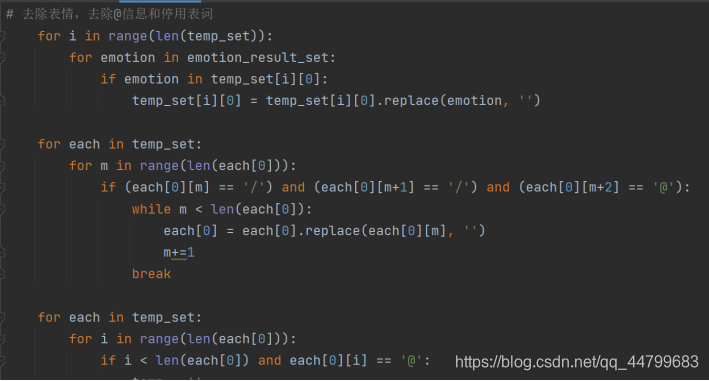
随后使用停词过滤
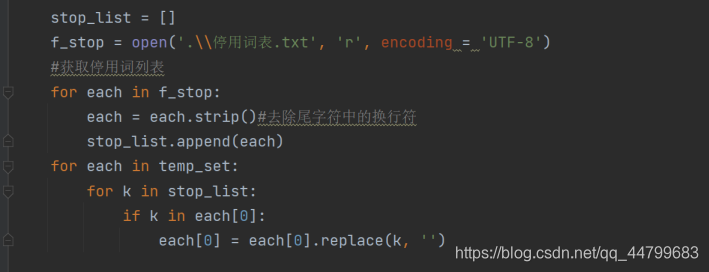
这里发现之前的停用词表存在一些不足, 具体停用词表可自行百度,因为其中存在一些诸如“很”、“特别”之类代表感情的词语,而在这里过滤掉之后影响后文分析,所以手动删除了所有的情感词,只留下一部分过滤无用词与符号,随后进行jieba分词,用作词性的标注

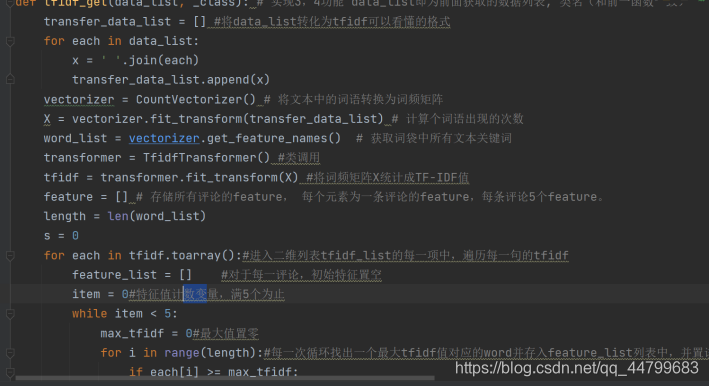
之后是常规程序TF-IDF选择每个句子的重要词成分,这里每个句子选择5个关键词,以避免后面的训练太慢
这里面也用到了论文中所说的副词重要性与位置的重要性进行权重的调整,比如说下面的权重数组
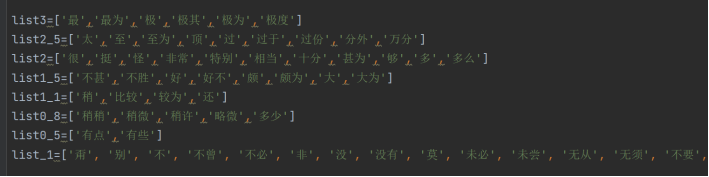
并且进行权重的修正,例如写一个简单的权重返回函数
还有尾词语比中部词语权重增加一倍,生成一个speciallist的特征向量,在后面进行训练的时候加入。这部分是对文字的训练。
构建模型训练
随后就是进行训练的部分,首先是读取数据集,定义初始权重
正面负面与中性的词语和表情权重分别为1、0、-1,然后先直接进行朴素贝叶斯训练,方便与后文实验效果做对比,值得一提的是文中是对词语进行分别打分计算权重,但这里复现时数据集不具备条件,于是赋予基础权重,也就是该词语所在句子超过80%情感的权重。
这里的六万条数据集进行交叉选取数据集与训练集,并且调库进行打分

而后的分类是对普通朴素贝叶斯的一个权重修正
可以看到加入了前面进行处理的特征向量,并且与正确结果进行对比,直接算比例,这里结果中可以看见提升非常明显,从百分之五十多直接提升到百分之八十多,说明论文中提出的方法明显有效(结果写在后文)。
前面都是定义方法,主体函数如下

三个类型分别进行训练并且叠加,因为实验二使用人工神经网络效果还不错,所以这里在后面也加了一个人工神经网络进行处理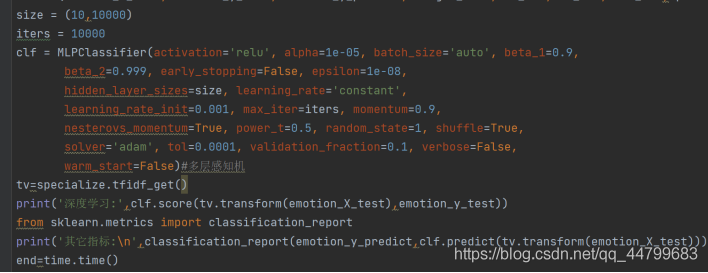
也没有用工具进行调参,自己写了两个循环跑了一晚上,写入文件自己去判断参数优化情况,得出得分较高的参数组合,得出的结果也有了比较明显的优化。
结果
运行代码,得运行结果:
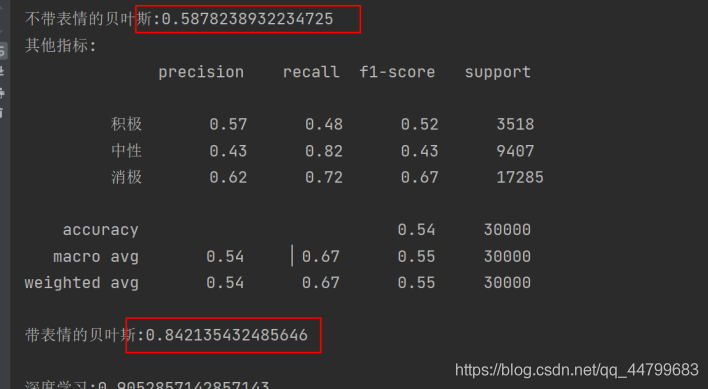
可以看出,用表情辅助对文本数据进行分类情感分析的效果,比单独的朴素贝叶斯分类效果要好一些。
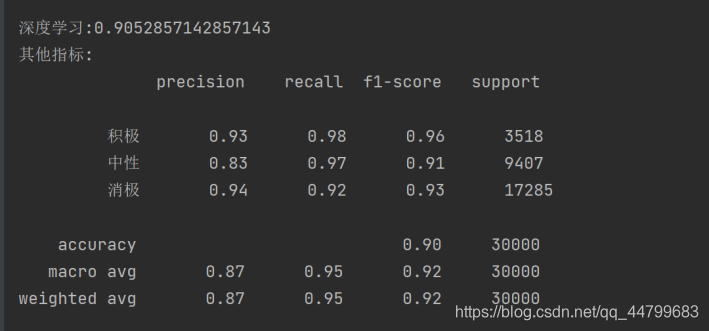

而深度学习又比单纯朴素贝叶斯效果要更好
代码
表情处理
import csv
# 获取某一评论中存在的表情 参数:path:文件路径 emotion_set:用来存储表情列表
def get_emotion(path, emotion_set):
with open(path, encoding= 'utf-8-sig') as f:
reader = csv.reader(f)
rows=[row for row in reader]
for each in rows:
for i in range(len(each[0])):
if each[0][i] == '[' : # 判断是否为表情符号
temp = ''
for k in range(100):
if i+k > len(each[0]) - 1:
break
temp = temp + each[0][i+k]
# print(each[i+k])
if each[0][i+k] == ']':
if temp not in emotion_set:
emotion_set.append(temp) # 若为表情符号则存储在该列表中,使每个符号只出现一次
# print(temp)
break
return emotion_set
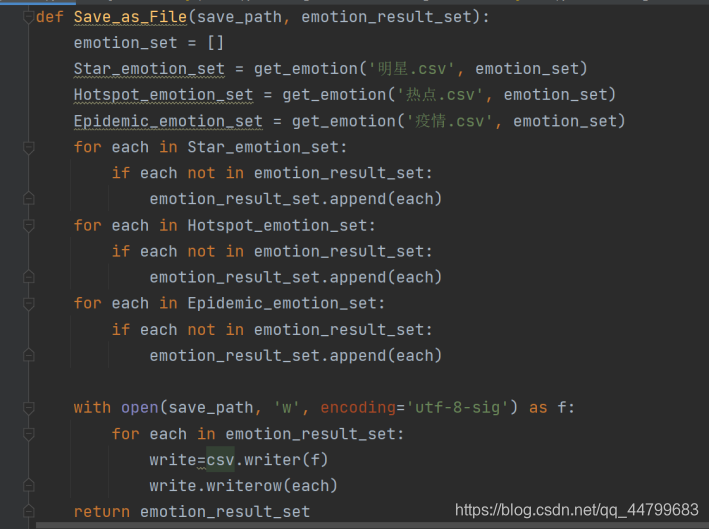
# 整合三个文件获取的表情存储于emotion_result_sat,存储于csv
def Save_as_File(save_path, emotion_result_set):
emotion_set = []
Star_emotion_set = get_emotion('明星.csv', emotion_set)
Hotspot_emotion_set = get_emotion('热点.csv', emotion_set)
Epidemic_emotion_set = get_emotion('疫情.csv', emotion_set)
for each in Star_emotion_set:
if each not in emotion_result_set:
emotion_result_set.append(each)
for each in Hotspot_emotion_set:
if each not in emotion_result_set:
emotion_result_set.append(each)
for each in Epidemic_emotion_set:
if each not in emotion_result_set:
emotion_result_set.append(each)
with open(save_path, 'w', encoding='utf-8-sig') as f:
for each in emotion_result_set:
write=csv.writer(f)
write.writerow(each)
return emotion_result_set
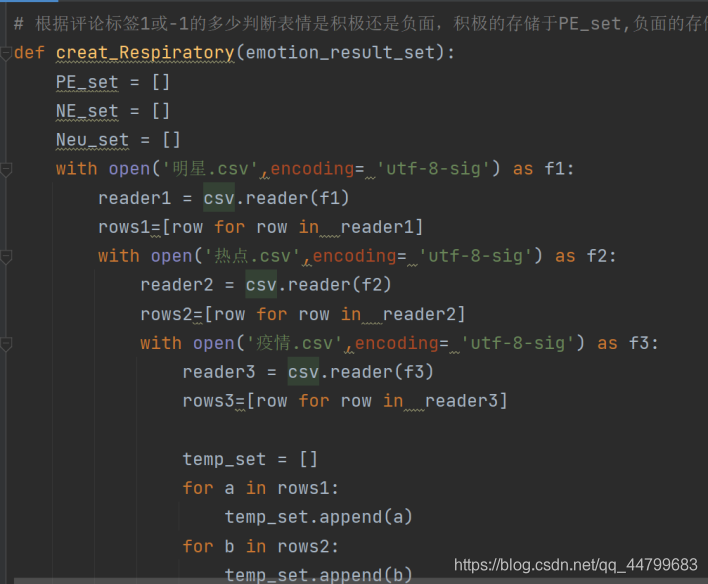
# 根据评论标签1或-1的多少判断表情是积极还是负面,积极的存储于PE_set,负面的存储于NE_set
def creat_Respiratory(emotion_result_set):
PE_set = []
NE_set = []
Neu_set = []
with open('明星.csv',encoding= 'utf-8-sig') as f1:
reader1 = csv.reader(f1)
rows1=[row for row in reader1]
with open('热点.csv',encoding= 'utf-8-sig') as f2:
reader2 = csv.reader(f2)
rows2=[row for row in reader2]
with open('疫情.csv',encoding= 'utf-8-sig') as f3:
reader3 = csv.reader(f3)
rows3=[row for row in reader3]
temp_set = []
for a in rows1:
temp_set.append(a)
for b in rows2:
temp_set.append(b)
for c in rows3:
temp_set.append(c) #将所有评论存储在一个列表temp_set内
# print(temp_set)
for emotion in emotion_result_set:
positive = 0
negtive = 0
for critic in temp_set:
# print(emotion)
if emotion in critic[0]:
if critic[1] == '1':
positive = positive + 1
if critic[1] == '-1':
negtive = negtive + 1
if positive + negtive == 0:
Neu_set.append(emotion)
else:
if (positive/(positive + negtive)) > 0.8:
PE_set.append(emotion)
elif (negtive/(positive + negtive)) > 0.8:
NE_set.append(emotion)
else:
Neu_set.append(emotion)
with open('Positive_emotion.csv', 'w', encoding='utf-8-sig') as f:
for each in PE_set:
write=csv.writer(f)
write.writerow(each)
with open('Negtive_emotion.csv', 'w', encoding='utf-8-sig') as f:
for each in NE_set:
write=csv.writer(f)
write.writerow(each)
with open('Neu_emotion.csv', 'w', encoding='utf-8-sig') as f:
for each in Neu_set:
write=csv.writer(f)
write.writerow(each)
return PE_set, NE_set, Neu_set
# emotion_result_set = []
# emotion_result_set = Save_as_File('.//emotion//All_emotion.csv', emotion_result_set)
# PE_set, NE_set = creat_Respiratory(emotion_result_set)
文本处理
import pre_professer
import jieba
import csv
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
list3=['最','最为','极','极其','极为','极度']
list2_5=['太','至','至为','顶','过','过于','过份','分外','万分']
list2=['很','挺','怪','非常','特别','相当','十分','甚为','够','多','多么']
list1_5=['不甚','不胜','好','好不','颇','颇为','大','大为']
list1_1=['稍','比较','较为','还']
list0_8=['稍稍','稍微','稍许','略微','多少']
list0_5=['有点','有些']
list_1=['甭', '别', '不', '不曾', '不必', '非', '没', '没有', '莫', '未必', '未尝', '无从', '无须', '不要', '不用', '不再', '不很', '不太', '绝非', '决非', '并非', '不能', '不常', '不会', '不可能', '何曾', '何尝', '勿']
def PLfenci(emotion_result_set, _class): #遍历每一条评论分词处理并去杂(去除表情、去除@内容、去除停用词)
label_list = [] # 一维列表,存储评论标签
with open('明星.csv',encoding= 'utf-8-sig') as f1:
reader1 = csv.reader(f1)
rows1=[row for row in reader1]
with open('热点.csv',encoding= 'utf-8-sig') as f2:
reader2 = csv.reader(f2)
rows2=[row for row in reader2]
with open('疫情.csv',encoding= 'utf-8-sig') as f3:
reader3 = csv.reader(f3)
rows3=[row for row in reader3]
temp_set = []
for a in rows1:
if _class == 'Star' or _class == 'All':
temp_set.append(a)
label_list.append(a[1])
for b in rows2:
if _class == 'Hotspot' or _class == 'All':
temp_set.append(b)
label_list.append(b[1])
for c in rows3:
if _class == 'Epidemic' or _class == 'All':
temp_set.append(c) #将评论存储在一个列表temp_set内
label_list.append(c[1])
if _class == 'All':
return temp_set, label_list
# 去除表情,去除@信息和停用表词
for i in range(len(temp_set)):
for emotion in emotion_result_set:
if emotion in temp_set[i][0]:
temp_set[i][0] = temp_set[i][0].replace(emotion, '')
for each in temp_set:
for m in range(len(each[0])):
if (each[0][m] == '/') and (each[0][m+1] == '/') and (each[0][m+2] == '@'):
while m < len(each[0]):
each[0] = each[0].replace(each[0][m], '')
m+=1
break
for each in temp_set:
for i in range(len(each[0])):
if i < len(each[0]) and each[0][i] == '@':
temp = ''
while i < len(each[0]) and (each[0][i] != ':' or each[0][i] == ' '): # 注意要使用中文':'
temp = temp + each[0][i]
i = i + 1
each[0] = each[0].replace(temp, '')
stop_list = []
f_stop = open('.\\停用词表.txt', 'r', encoding = 'UTF-8')
#获取停用词列表
for each in f_stop:
each = each.strip()#去除尾字符中的换行符
stop_list.append(each)
for each in temp_set:
for k in stop_list:
if k in each[0]:
each[0] = each[0].replace(k, '')
# 进行jieba分词
speciallist=[]
data_list = [] # 二维列表,每个元素为一个评论预处理后的结果,每个结果也是一个列表,用','分割。
for k in range(len(temp_set)):
data_list.append([])
k = 0
for each in temp_set:
a=checkpoint(each)
speciallist.append(a)
generator = jieba.cut(each[0])
for i in generator:
data_list[k].append(i)
k = k + 1
# 预处理结果写入segment文件
with open('.\\segment.csv', 'w', newline = '',encoding = 'utf-8-sig') as f:
write = csv.writer(f)
for each in data_list:
write.writerow(each)
return data_list, label_list,speciallist
def tfidf_get(data_list, _class): # 实现3,4功能 data_list即为前面获取的数据列表, 类名(和前一函数一致)
transfer_data_list = [] #将data_list转化为tfidf可以看懂的格式
for each in data_list:
x = ' '.join(each)
transfer_data_list.append(x)
vectorizer = CountVectorizer() # 将文本中的词语转换为词频矩阵
X = vectorizer.fit_transform(transfer_data_list) # 计算个词语出现的次数
word_list = vectorizer.get_feature_names() # 获取词袋中所有文本关键词
transformer = TfidfTransformer() #类调用
tfidf = transformer.fit_transform(X) #将词频矩阵X统计成TF-IDF值
feature = [] # 存储所有评论的feature, 每个元素为一条评论的feature,每条评论5个feature。
length = len(word_list)
s = 0
for each in tfidf.toarray():#进入二维列表tfidf_list的每一项中,遍历每一句的tfidf
feature_list = [] #对于每一评论,初始特征置空
item = 0#特征值计数变量,满5个为止
while item < 5:
max_tfidf = 0#最大值置零
for i in range(length):#每一次循环找出一个最大tfidf值对应的word并存入feature_list列表中,并置该tfidf = 0
if each[i] >= max_tfidf:
max_tfidf = each[i]
m = i#记录相应索引号
if i == (length - 1):# i = length - 1说明句子已经遍历到末尾了,此时最大的tfidf值就可以确定了
feature_list.append(word_list[m])
each[m] = 0
item = item + 1
v = ' '.join(feature_list)
feature.append(v)
s = s + 1
with open('.\\特征数据\\' + _class + '.csv', 'w', newline = '',encoding = 'utf-8-sig') as f:
write = csv.writer(f)
for each in feature:
write.writerow(each)
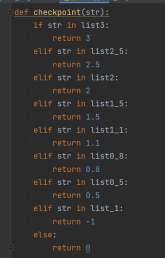
def checkpoint(str):
if str in list3:
return 3
elif str in list2_5:
return 2.5
elif str in list2:
return 2
elif str in list1_5:
return 1.5
elif str in list1_1:
return 1.1
elif str in list0_8:
return 0.8
elif str in list0_5:
return 0.5
elif str in list_1:
return -1
else:
return 0
建模训练
import pre_professer
import specialize
from sklearn.model_selection import train_test_split #数据集划分
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer # 从sklearn.feature_extraction.text里导入文本特征向量化模块
from sklearn.metrics import classification_report
from sklearn.neural_network import MLPClassifier
import time
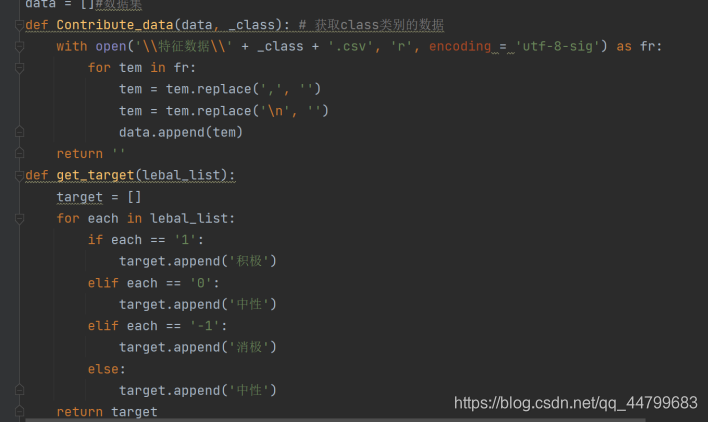
data = []#数据集
def Contribute_data(data, _class): # 获取class类别的数据
with open('\\特征数据\\' + _class + '.csv', 'r', encoding = 'utf-8-sig') as fr:
for tem in fr:
tem = tem.replace(',', '')
tem = tem.replace('\n', '')
data.append(tem)
return ''
def get_target(lebal_list):
target = []
for each in lebal_list:
if each == '1':
target.append('积极')
elif each == '0':
target.append('中性')
elif each == '-1':
target.append('消极')
else:
target.append('中性')
return target
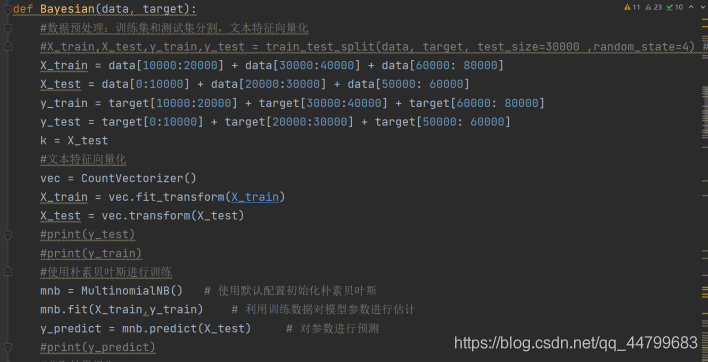
def Bayesian(data, target):
#数据预处理:训练集和测试集分割,文本特征向量化
#X_train,X_test,y_train,y_test = train_test_split(data, target, test_size=30000 ,random_state=4) # 随机采样数据样本作为测试集
X_train = data[10000:20000] + data[30000:40000] + data[60000: 80000]
X_test = data[0:10000] + data[20000:30000] + data[50000: 60000]
y_train = target[10000:20000] + target[30000:40000] + target[60000: 80000]
y_test = target[0:10000] + target[20000:30000] + target[50000: 60000]
k = X_test
#文本特征向量化
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.transform(X_test)
#print(y_test)
#print(y_train)
#使用朴素贝叶斯进行训练
mnb = MultinomialNB() # 使用默认配置初始化朴素贝叶斯
mnb.fit(X_train,y_train) # 利用训练数据对模型参数进行估计
y_predict = mnb.predict(X_test) # 对参数进行预测
#print(y_predict)
#获取结果报告
print ('不带表情的朴素贝叶斯:', mnb.score(X_test,y_test))
print ('其它指标:\n',classification_report(y_test, y_predict, target_names = ['积极', '中性', '消极']))
return k, y_test, y_predict
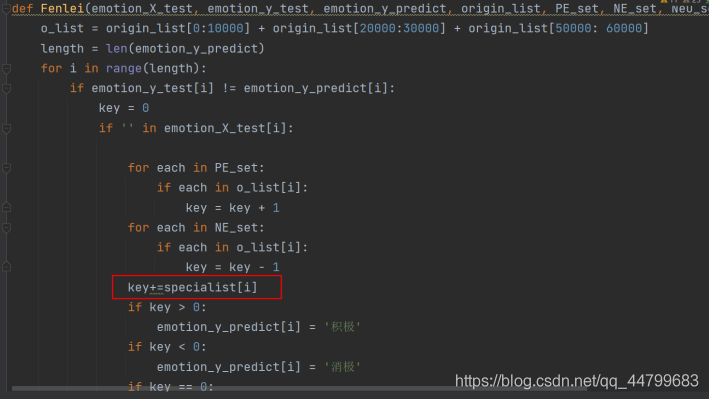
def Fenlei(emotion_X_test, emotion_y_test, emotion_y_predict, origin_list, PE_set, NE_set, Neu_set,specialist): # 运用表情训练
o_list = origin_list[0:10000] + origin_list[20000:30000] + origin_list[50000: 60000]
length = len(emotion_y_predict)
for i in range(length):
if emotion_y_test[i] != emotion_y_predict[i]:
key = 0
if '' in emotion_X_test[i]:
for each in PE_set:
if each in o_list[i]:
key = key + 1
for each in NE_set:
if each in o_list[i]:
key = key - 1
key+=specialist[i]
if key > 0:
emotion_y_predict[i] = '积极'
if key < 0:
emotion_y_predict[i] = '消极'
if key == 0:
emotion_y_predict[i] = '中性'
else:
key = 0.5
for each in PE_set:
if each in o_list[i]:
key = key + 1
for each in NE_set:
if each in o_list[i]:
key = key - 1
for each in Neu_set:
if each in o_list[i]:
key = key - 0.5
if key > 0:
emotion_y_predict[i] = '积极'
if key < 0:
emotion_y_predict[i] = '消极'
if key == 0:
emotion_y_predict[i] = '中性'
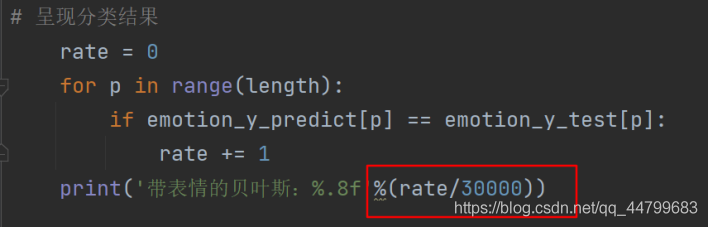
# 呈现分类结果
rate = 0
for p in range(length):
if emotion_y_predict[p] == emotion_y_test[p]:
rate += 1
print('带表情的贝叶斯:%.8f'%(rate/30000))
return ''
start=time.time()
print('开始预处理')
emotion_result_set = []
emotion_result_set = pre_professer.Save_as_File('All_emotion.csv', emotion_result_set)
PE_set, NE_set, Neu_set = pre_professer.creat_Respiratory(emotion_result_set)
print('预处理完毕')
Star_data_list,lebal_list ,specialkist= specialize.PLfenci(emotion_result_set, 'Star')
print('开始star处理')
feature = specialize.tfidf_get(Star_data_list, 'Star')
print('Star类别特征构建成功')
print('开始hotpot处理')
Hotspot_data_list,lebal_list ,specialkist= specialize.PLfenci(emotion_result_set, 'Hotspot')
feature = specialize.tfidf_get(Hotspot_data_list, 'Hotspot')
print('Hotspot特征构建成功')
Epidemic_data_list,lebal_list ,specialkist= specialize.PLfenci(emotion_result_set, 'Epidemic')
feature = specialize.tfidf_get(Epidemic_data_list, 'Epidemic')
print('Epidemic特征构建成功')
Contribute_data(data, 'Star')
Contribute_data(data, 'Hotspot')
Contribute_data(data, 'Epidemic')
origin_list, lebal_list = specialize.PLfenci(emotion_result_set, 'All')
target = get_target(lebal_list)
emotion_X_test, emotion_y_test, emotion_y_predict = Bayesian(data, target)
#print(len(emotion_y_test))
Fenlei(emotion_X_test, emotion_y_test, emotion_y_predict, origin_list, PE_set, NE_set, Neu_set,specialkist)
size = (10,10000)
iters = 10000
clf = MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=size, learning_rate='constant',
learning_rate_init=0.001, max_iter=iters, momentum=0.9,
nesterovs_momentum=True, power_t=0.5, random_state=1, shuffle=True,
solver='adam', tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)#多层感知机
tv=specialize.tfidf_get()
print('深度学习:',clf.score(tv.transform(emotion_X_test),emotion_y_test))
from sklearn.metrics import classification_report
print('其它指标:\n',classification_report(emotion_y_predict,clf.predict(tv.transform(emotion_X_test))))
end=time.time()
参考论文:基于表情符分析的情感关键句提取方法
(提取码:3882)